

Spring Data @Repository 的分页查询
分页查询在网站的设计中必不可少。
分页查询有几种方式,通常用的是:网页分页和后端分页。
不要觉得现在还有人用网页分页的方式吗?
相信我,奇葩远比想象得多。经历过一个项目,全部都是网页分页,后端都是大量的 JOIN 和毫无人性的返回几千条记录。
为什么不返回上万条?那是因为后台数据库不大,只有 5 万多点的数据量。连个 Limit 都懒得用的项目还堂而皇之的上线运行了好几年到不重做差不多就没法用的地步。
我们来说说基于 Spring Data 的分页查询。
如果项目使用的是 Spring Data,那么恭喜你,这分页太方便了。
PagingAndSortingRepository 接口
首先你的实体仓库类,需要继承 PagingAndSortingRepository 这个接口。
写法也简单到只写一个继承就可以了。
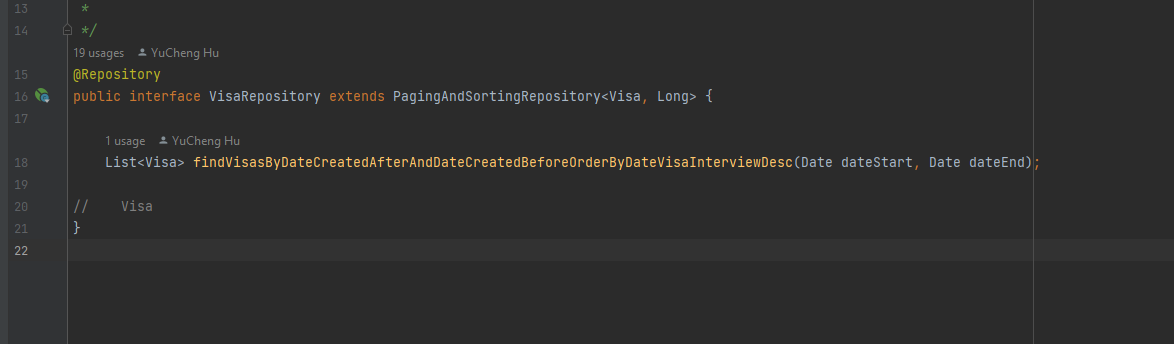
PagingAndSortingRepository 接口继承于 CrudRepository 接口,拥有CrudRepository 接口的所有方法, 并新增两个功能:分页和排序。
Service
Service 层也简单到不能再简单了。
假设我们希望查询一个实体类的所有数据,但是我们希望进行分页。
我们可以简单到
public Page<Visa> findAllVisa(Pageable pageable) {
return visaRepository.findAll(pageable);
}
只写这一段话就可以了。
我们只需要把 pageable 作为参数传递进去就行了。
Pageable 是一个接口。
定义分页对象
要对实体数据进行分页,我们需要让实体数据知道后面查询的时候是怎么分页的。
在服务层或者控制层定义一个 Pageable 对象。
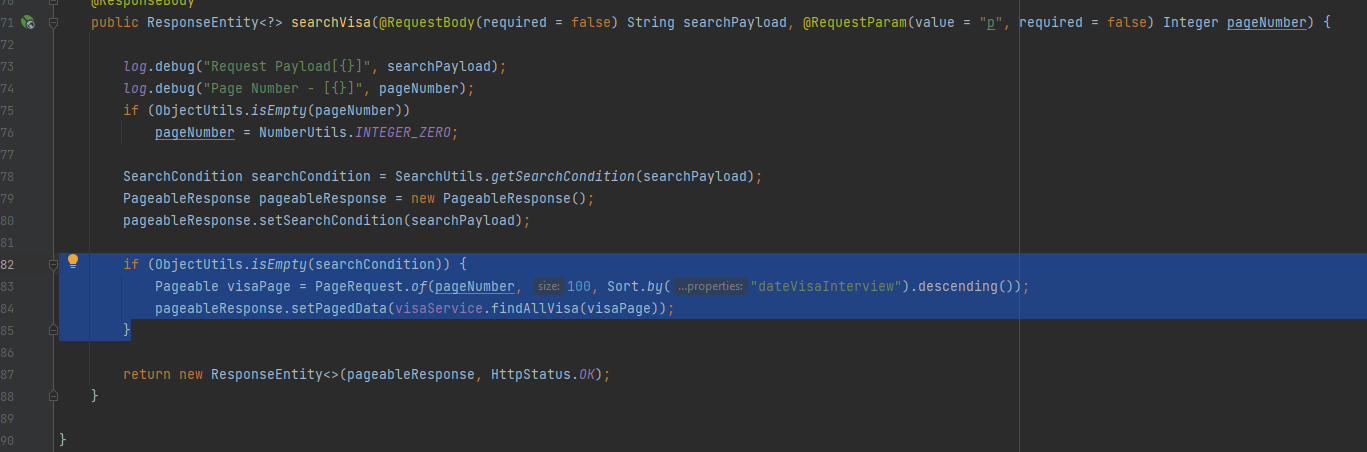
if (ObjectUtils.isEmpty(searchCondition)) {
Pageable visaPage = PageRequest.of(pageNumber, 100, Sort.by("dateVisaInterview").descending());
pageableResponse.setPagedData(visaService.findAllVisa(visaPage));
}
在这个对象中,我们创建了一个 visaPage 分页对象。
在这个分页对象中,我们提供了参数:
- 分页的当前页
- 每一个页面的大小
- 排序字段
返回
在分页查询的结果都会返回一个叫做 Page 的对象。
Page 是一个接口,继承的 Slice。
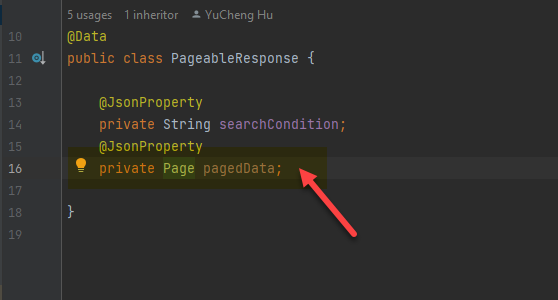
为了让程序更加简单,我们直接定义了一个返回的对象。将 Page 的内容返回到 API 上。
运行结果
如果 API 运行没有问题的话,在 API 的返回中,我们可以看到下面的信息。
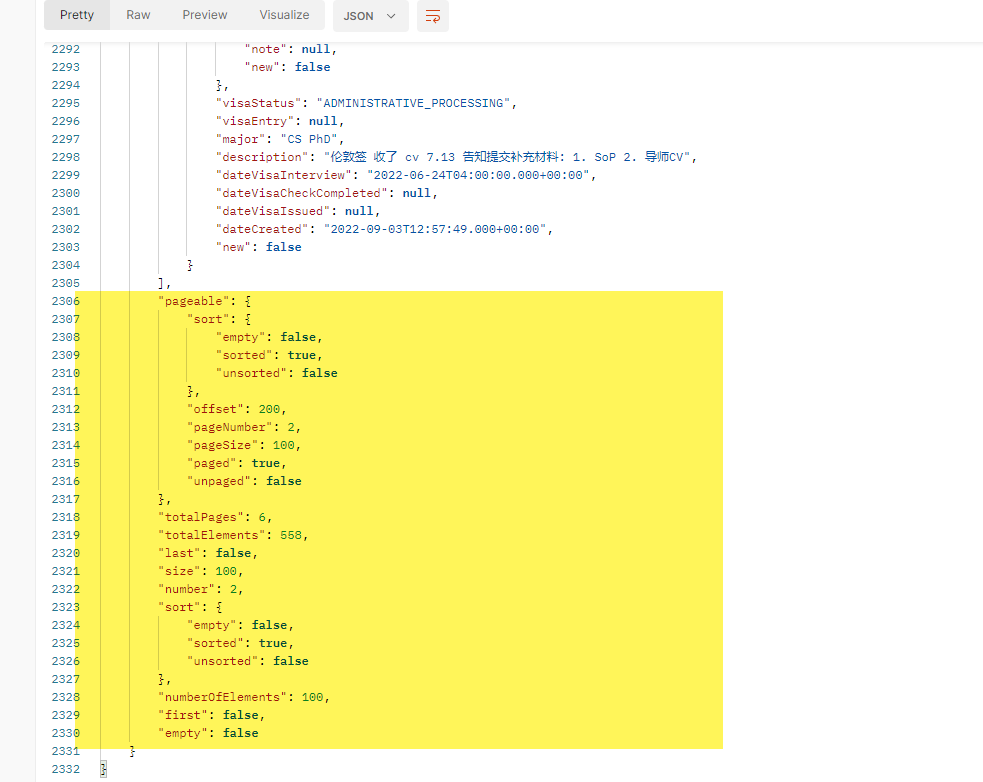
针对分页查询的所有信息都有了。
包括有当前页,页大小,偏移量,总数据量。
使用 Spring Data 的分页查询,能够大大加快程序的处理,甚至能够让程序员不再关注后端是如何获得查询数据和如何进行查询的。
真的是一个非常贴心的接口。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)
2021-09-11 Node 的 cross-env 模块
2021-09-11 如何禁用 Gmail 的分类(Categories )标签
2021-09-11 JavaScript 的 Math.floor() 函数
2021-09-11 JavaScript 的 Math.ceil() 函数
2021-09-11 NVM 如何切换版本
2021-09-11 Npm 安装提示 EUNSUPPORTEDPROTOCOL 错误
2020-09-11 Docsify 初始化文件夹