

网络编程常用的几种字符编码
乱码是所有程序员都经历过的噩梦。
拯救你生命的只有 UTF-8。
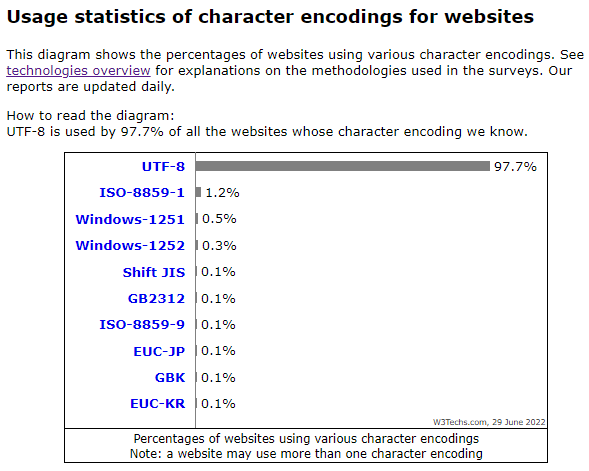
如果你不知道用什么字符集,用 UTF-8,如果没有强制要求,也用 UTF-8,相信我,没错的。
从上面的网页使用的编码就知道为什么了。如果你的公司还在使用 ISO-8895-1 的话,你可以好好鄙视下,说明这公司负责技术的不行嘛。
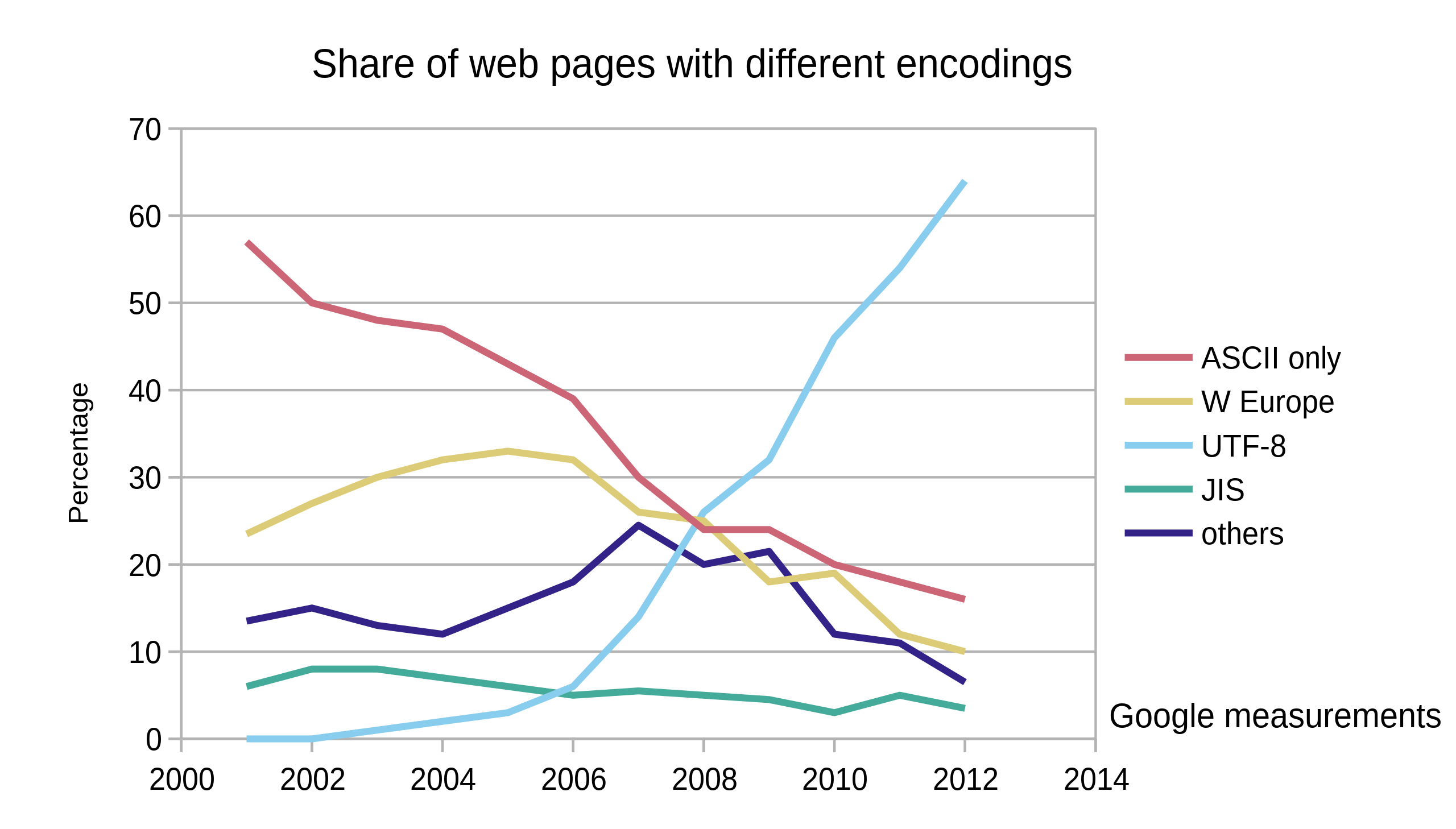
如果你公司是中文公司,被强制使用 GBK 或者 GB18030,你就不要鄙视了,因为使用 GB 字符集是在中国大陆销售的软件的强制标准,但是还使用 GB 2312 的话,你也可以鄙视下了。
欧美的编码
欧美常常使用的编码是不适合中文使用的,换句话说就是你写的代码没有办法接受中文的输入也没有办法存储中文,当然也没有办法存储日韩文字了。
ASCII 编码
(American Standand Code for InformationInterchange) 的缩写
ASCII 码是计算机最开始支持的基于拉丁字母的编码,一个字符用一个字节表示,只用了低 7 位,最高位为 0,因此总共有 128 个ASCII码,范围为 0~127。
这个编码应该是大学计算机课程的第一节课,就是要学习 ASCII 编码。
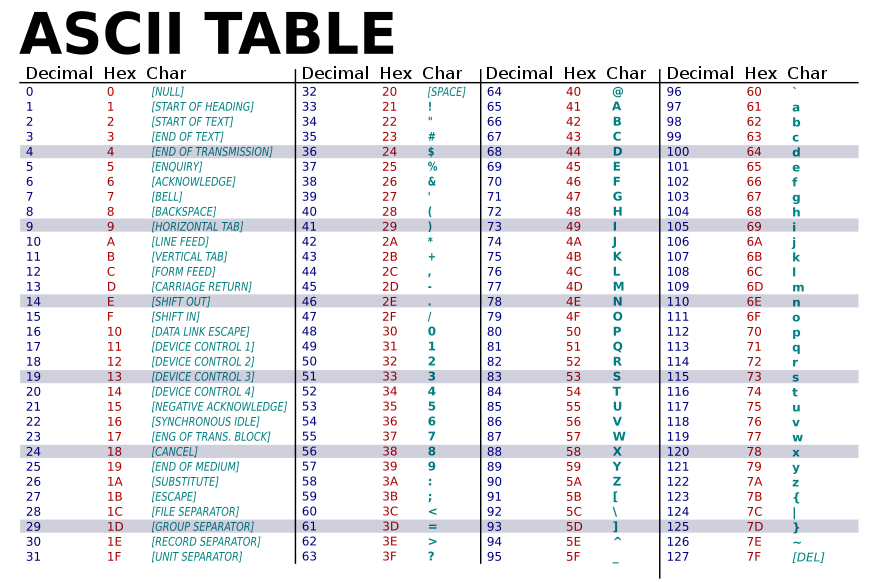
这个字符集简单来说就是只能用于英文,字符集太小,啥都存不下。
ISO-8859-1 编码
ISO -8859-1编码 是单字节编码 ,向下兼容ASCII,其编码*范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号。
因为 ASCII 字符集实在太小了,现在就有了 ISO-8859-1。
对我们来说这个字符集的最大问题就是不能支持中文,韩语,日文,在欧美国家用用还行。
但是很多软件默认都使用 ISO-8859-1,欧美国家的程序员又没有太多字符集的需求,因此很有可能会默认就使用这个字符集,所以你也可以吐槽下。
中文字符集
中文字符集就是我们常用的 GB 字符集了。
GB是 国标 两字的拼音首字,2312 是标准序号。GB 有 3 个版本,按照字符集的大小排序,其实也是按照发布时间排序。
GB2312
最早的中文字符集,和 ASCII 字符集一样,字符集太小,很多汉字打不出来,异体字也打不出来。
GB2312 规定对收录的每个字符采用两个字节表示。
GBK
即汉字国标扩展码。
GBK编码,是对GB2312编码的扩展,因此完全兼容GB2312-80标准。GBK编码依然采用双字节编码方案,其编码范围:8140-FEFE,剔除xx7F码位,共23940个码位。共收录汉字和图形符号21886个,其中汉字(包括部首和构件)21003个,图形符号883个。GBK编码支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字,并包含了BIG5编码中的所有汉字。GBK编码方案于1995年12月15日正式发布,这一版的GBK规范为1.0版。
Windows 95 系统就是以GBK为内码,又由于GBK同时也涵盖了Unicode 所有CJK汉字,所以也可以和Unicode 做一一对应。
从 2000 年以后的程序设计相关,如果是中文的话,基本上都会使用 GBK 字符集了,已经不怎么使用 GB2312 字符集了。
因为 GBK 的字符存储得更多,生僻字也可以显示了。
GB18030
2000年3月17日发布的汉字编码国家标准GB18030编码,是对GBK编码的扩充,覆盖中文、日文、朝鲜语和中国少数民族文字,其中收录27484个汉字。
GB18030字符集采用单字节、双字节和四字节三种方式对字符编码。兼容GBK和GB2312字符集。
它完全兼容ASCII码与GBK码。
GB18030 是对 GBK 编码的进一步扩充,字符集更大,可以存储的汉字更多。
但是针对 Web 开发来说,其实我们也用不到那么多汉字,所以现在很多网站还是在使用 GBK 的编码。
BIG5
这个简称就是繁体中文使用的,主要在台湾,香港地区使用。
BIG5编码又称大五码,是繁体中文字符集编码标准,共收录13060个中文字,其中有二字为重复编码。
BIG5重复地收录了两个相同的字:“兀、兀”(A461及C94A)、“嗀、嗀”(DCD1及DDFC)。
适用于台湾和香港地区的繁体中文系统软件等。不过由于编码本身存在的问题,已经基本改用 Unicode 编码了。
BIG5 目前已经不怎么使用了,我们在这里列出来就是想说明下曾经还有一个这样的编码而已。
Unicode
你的救星来了。
Unicode(统一码、万国码、单一码、标准万国码)编码就是为了表达任意语言的任意字符而设计的。
目前的情况是大部分程序,数据库,通讯协议都会使用 UTF-8 编码。
使用 UTF-8 编码能够适配所有的字符集并且不容易出现乱码问题。
如果你不知道你要什么编码,用 UTF-8 编码就没错的了。
Java 中 String 字符串的存储是使用 UTF-16 编码存储的,在 JDK 9+ 以后的版本,Java 对 String 的存储进行了压缩以增加空间使用率。
如果你是早期的程序员,你一定经历过转码的痛苦,不要想太多,UTF-8 才是你的真爱。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· SQL Server 2025 AI相关能力初探
· 单线程的Redis速度为什么快?
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
2018-07-02 Confluence 6 审查日志的对象
2018-07-02 Confluence 6 审查日志
2018-07-02 Confluence 6 导入一个文本文件
2018-07-02 Confluence 6 数据导入和导出