

Java 中的 String Pool 简介
在 Java 中 String 对象是我们最常用的对象。
在本文章中,我们主要对 String 对象使用的 String Pool 进行一些简单的介绍。
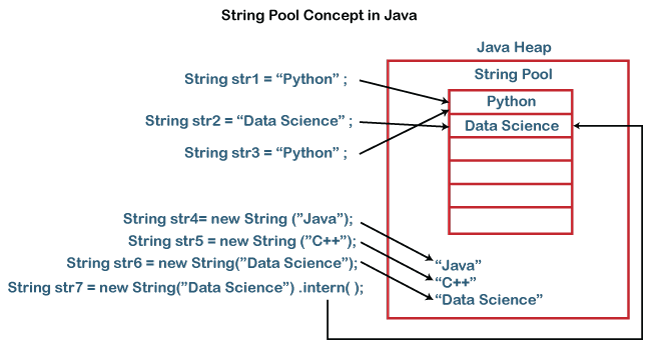
Java 定义 String 后,String 是存储在 String Pool 中的,以便于加快字符串的访问和处理。
正是有这个方面的访问需求,JVM 为 String 对象在内存中特地开辟了一个存储区域来加快对 String 对象的访问,这个特定的内存区域就是我们说的 String Pool 了。
字符串引用(String Interning)
我们都知道 Strings 在 Java 中是不可变的( immutable),因此 JVM 可以通过访问这个字符串的引用,或者我们可以借用指针的这个概念来访问 String 字符串。
通过指针访问字符串值的这个过程就可以称为引用(interning)。
当我们在内存中创建一个字符串的时候,JVM 将会根据你创建字符串的值在内存中进行查找有没有和你创建值相同的 String 对象已经被创建了。
如果,JVM 找到了这个对象的话,JVM 就将会为你创建的对象返回已经存在 String 的地址的引用,而不会继续申请新的内存空间,以便于提高内存的利用率。
如果,JVM 没有找到与创建对象相同的值的话,JVM 将会申请内存空间并且创建这个 String 对象,然后将新创建的这个 String 的对象进行返回,这个过程就称为引用(interned)。
让我们使用下面的方法进行验证:
@Test
public void whenCreatingConstantStrings_thenTheirAddressesAreEqual() {
String constantString1 = "HoneyMoose";
String constantString2 = "HoneyMoose";
assertThat(constantString1).isSameAs(constantString2);
}
上面的方法将会通过,原因是 constantString2 在创建的时候,将会得到的是 constantString1 内存地址的引用。
因此上面 2 个字符串是完全相同的。
String 构造方法中的内存分配
因为构造 String 对象有几种不同的方法,我们可以通过直接赋值的方式构造 String 对象,我们也可以通过 new 的方式来构造一个 String 对象。
在这里我们需要说如果使用 new 这个关键字来构造的 String对象。
简单来说,如果你使用了 new 这个关键字来构造 String 对象的话,不管 String 对象中的值是不是相同,JVM 都会为构造的对象开辟存储空间,这个存储空间在 JVM 的 heap 中。
因此每个使用 new 构造的 String 对象都会有自己的内存地址。
让我们来看看下面的代码:
@Test
public void whenCreatingStringsWithTheNewOperator_thenTheirAddressesAreDifferent() {
String newString1 = new String("HoneyMoose");
String newString2 = new String("HoneyMoose");
assertThat(newString1).isNotSameAs(newString2);
logger.info("newString1 Address: {}", System.identityHashCode(newString1));
logger.info("newString2 Address: {}", System.identityHashCode(newString2));
}
上面的代码将会输出:
16:03:38.916 [main] INFO c.o.stringpool.StringPoolUnitTest - newString1 Address: 429075478
16:03:38.919 [main] INFO c.o.stringpool.StringPoolUnitTest - newString2 Address: 1802066694
我们可以看到使用 new 以后的 String 的地址空间是不一样的。
String 文字(Literal)和 对象(Object)
当我们创建 String 对象的时候,如果使用 new() 的方式来创建一个 String 对象,JVM 将会每次都会在 heap 内存中为我们创建的 String 对象开辟一个存储空间来进行存储。
但是,如果我们使用赋值方式创建 String 对象的话,JVM 首先将会对我们赋的值到 String Pool 中进行查找,如果找到的话,就返回已经存在这个值的引用。
如果没有找到,就创建一个新的 String 对象并且返回这个创建对象的引用。
例如,我们如果使用赋值方式将值 “HoneyMoose” 创建的话,我们有可能会得到的是已经存在值的内存地址让我们能够来重新利用已经划分的内存,也有可能是一个全新的内存地址。
简单来说,这 2 种方式创建的 String 字符串都是 String 对象,唯一不同的是 new 操作每次都会给出新的地址,另外的操作则不能每次都是新的内存地址。
要解释这种情况,我们可以用一个数据基本面试问题的题目来进行解释,就是为什么使用 == 进行字符串比较的时候有时候会得到 False 的值。
因为,我们都知道 == 比较的是地址,而不是 String 中存储的值。
考察下面的代码:
String first = "HoneyMoose";
String second = "HoneyMoose";
System.out.println(first == second); // True
在上面的初始化后比较中,我们会得到 True 的值,因为上面 2 个 String 的地址是相同的。
下面,我们再使用 new 关键字来创建 2 个新的 String 对象,然后再来比较 String 对象的引用:
String third = new String("HoneyMoose");
String fourth = new String("HoneyMoose");
System.out.println(third == fourth); // False
相同的,我们使用 new 的方式来创建对象,我们可以看到上面创建的 String 的地址是不相同的。
因此使用 == 计算的结果是 False。
String fifth = "HoneyMoose";
String sixth = new String("HoneyMoose");
System.out.println(fifth == sixth); // False
通常来说,我们建议对 String 对象初始化的时候,使用文字方式对 String 对象初始化,这样的话我们能够让 JVM 有机会对 String 初始化之前进行判断来完成内存优化而不需要重复创建相同的对象。
手工引用
手工修改引用的意思就是通过程序来手工修改 String 字符串使用的指针来获得我们需要的值。
手工修改指针的方法为 intern()。
手工修改 String 在 String 存储池中的引用,JVM 将会在我们需要的时候返回这个引用。
让我们来创建一个测试用例:
String constantString = "interned HoneyMoose";
String newString = new String("interned HoneyMoose");
assertThat(constantString).isNotSameAs(newString);
String internedString = newString.intern();
assertThat(constantString)
.isSameAs(internedString);
上面代码中的第一次判断是不相同的,后来我们在创建一个新的 String 的对象的时候,使用了一个已经创建的 String 字符串的引用,那么我们的后面再进行判断的时候就是相同的了。
垃圾清理
在 Java 7 之前,JVM 是将 String Pool 存储在 PermGen 存储空间的,这个存储空间的大小是固定的。
因此我们没有办法通过 JVM 的垃圾清理程序来扩展运行时候的内存。
相对将 String Pool 设置到 Heap 内存空间,如果我们将 String 放置到 PermGen 中,但是我们又创建了很多 String 对象的话,我们可能会遇到 OutOfMemory 错误。
从 Java 7 开始,String Pool 将会放置到 Heap 内存空间了,因为 Heap 内存空间是可以使用 JVM 的垃圾清理程序来进行清理的。
这样的话能够降低我们遇到 OutOfMemory 错误的风险,因为对不使用的 String 对象,将会从内存中删除,内存将会被释放以便于后续创建 String 对象。
性能和优化
在 Java 6 中,我们唯一可以做的优化就是通过增加 PermGen 内存空间来提供更多的存储。
可以通过在 JVM 中使用参数来实现:
-XX:MaxPermSize=1G
从 Java 7 开始,我们可以为 String Pool 指定更多的参数来扩展和减少 String Pool 的大小。
让我们来看看下面使用的 2 个参数:
-XX:+PrintFlagsFinal
-XX:+PrintStringTableStatistics
如果我们希望增加 String Pool 的 buckets 大小,我们可以使用 JVM 提供的 StringTableSize 参数选项:
-XX:StringTableSize=4901
在 Java 7u40,默认的 String Pool 大小为 1009 buckets。
但是这个值在最近的一些 Java 版本更新中有了改变,从 7u40 到 Java 11 String Pool 的大小为 60013 buckets,在 Java 11 的后续版本中,这个值增加到了 65536 buckets。
需要注意的是,增加 String Pool 的大小将会增加 JVM 的内存消耗,但是也会降低在我们对 String 进行赋值的时候 JVM 对 String 表的处理时间。
有关 Java 9 的 String
一直到 Java 8,Strings 在 Java 中使用字符数组进行存储的,同时使用的是 UTF-16 字符集,因此每一个字符将会使用 2 字节的内存。
从 Java 9 开始,Java 提供了一个叫做压缩字符(Compact Strings)的存储概念。
这个存储将会针对字符串使用 char[] 和 byte[] 中字符编码,这个将会与你需要存储的内容有关。
简单来说就是从 Java 9 开始,String 将会根据存储内容的不同来使用不同的存储格式,只会在必要的时候才会使用 UTF-16 编码,这种设计将会显著降低 String 对内存的使用,并且能够让来让垃圾清理程序(Garbage Collector)更有效率的工作。
结论
在本文章中,我们对 JVM 中的 String 是如何存储的和 String Pool 的概念进行一些简单的说明。
同时,我们对如何对 String 是如何初始化和内存中的使用情况,以及如何进行 String 的优化进行了一些说明。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)
2018-06-27 Confluence 6 整合到支持的附件存储选项
2018-06-27 Confluence 6 附件存储选项
2018-06-27 Confluence 6 附件存储配置
2018-06-27 Confluence 6 "net.sf.hibernate.PropertyValueException: not-null" 相关问题解决
2018-06-27 Confluence 6 "Duplicate Key" 相关问题解决
2018-06-27 Confluence 6 针对 key "cp_" 或 "cps_" 的 "Duplicate Entry" 问题解决
2018-06-27 Confluence 6 尝试从 XML 备份中恢复时解决错误