
天津东软实训第九天——MapReduce实战
案例:有一万条某网站的用户日志信息,例如:
211.162.33.31 - - [10/Nov/2016:00:01:02 +0800] "GET /u/card HTTP/1.1" 200 331 "www.neusoft.com" "http://www.neusoft.com/code/2053" - "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36" "-" 10.100.136.65:80 200 0.371 0.371
分析一下日志信息:
211.162.33.31(IP地址)
10/Nov/2016:00:01:02 +0800(访问日期和时区)
Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36(浏览器信息)
有一万这样的日志信息,现在需要统计用户使用各种浏览器所占的比例,通过MapReduce计算出结果。
这里有个写好的获取浏览器信息的项目,我们只要把它下载下来打成jar包就能使用里面的方法了:
首先,访问https://github.com/LeeKemp/UserAgentParser
复制里面的URL,在桌面新建一个文件夹UserAgent,在文件夹内右键,选择Git Bash Here(注:没有这个自己去下载Git,安装配置好),在弹出框中输入:
git clone https://github.com/LeeKemp/UserAgentParser.git
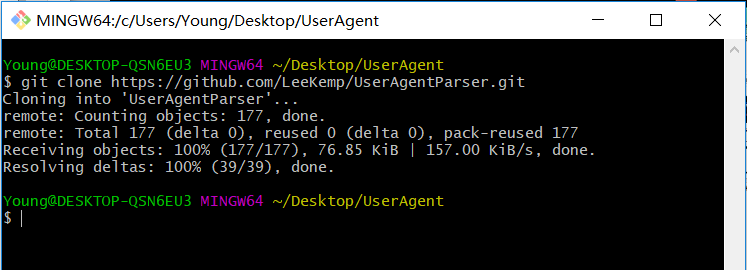
成功之后,UserAgent的文件夹下会有UserAgentParser文件。

打开cmd,对UserAgentParser项目进行maven打包:
首先:输入命令:cd C:\Users\Young\Desktop\UserAgent\UserAgentParser (注:进入UserAgentParser文件夹)
然后:输入命令:mvn clean package (注:进行打包操作,如果出现“mvn不是内部命令什么的错误”,说明你maven的环境变量没有弄好,自己百度)
最后:打包成功后输入命令:mvn install (注:将打包文件放入本地maven仓库,方便在maven项目中引用)
打开IDEA,新建maven项目,添加相应的依赖(导包) pom.xml中添加依赖部分内容如下(注:其中com.kumkee的那个就是刚刚下载完成的项目包):
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>com.kumkee</groupId>
<artifactId>UserAgentParser</artifactId>
<version>0.0.1</version>
</dependency>
</dependencies>
打开App.java:
package com.young;
import com.kumkee.userAgent.UserAgent;
import com.kumkee.userAgent.UserAgentParser;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class App
{
public static class MyMap extends Mapper<LongWritable,Text,Text,DoubleWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line =value.toString();//按行获取文件内容
UserAgentParser userAgentParser = new UserAgentParser();
UserAgent agent = userAgentParser.parse(line);//对每行内容进行解析
context.write(new Text(agent.getBrowser()),new DoubleWritable(1));//获取相应的浏览器信息
}
}
public static class MyReduce extends Reducer<Text,DoubleWritable,Text,DoubleWritable> {
@Override
protected void reduce(Text key, Iterable<DoubleWritable> values, Context context) throws IOException, InterruptedException {
double sum = 0;
for(DoubleWritable value:values)
{
sum+=value.get();//统计每个key值对应的value值
}
context.write(key,new DoubleWritable(sum/10000));//计算每个浏览器的占比
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.131.142:9000");
Job job = Job.getInstance(conf);
job.setJarByClass(App.class);
job.setMapperClass(MyMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DoubleWritable.class);
job.setReducerClass(MyReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DoubleWritable.class);
FileInputFormat.addInputPath(job,new Path("/log/10000_access.log"));//HDFS上要计算的文件地址
FileOutputFormat.setOutputPath(job,new Path("/log/out"));//输出地址
job.waitForCompletion(true);
}
}
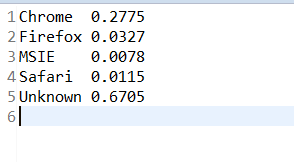
执行结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号