

线上环境应用程序消耗CPU过高问题排查
一、CPU使用率过高的原因一般是:
1、线程空耗,如大量线程获取锁的过程中自旋等待;
2、系统进行密集运算(密集数学运算的AI程序等);
3、内存不足造成JVM频繁fullGC;
4、系统正在进行大量线程上下文切换消耗资源;
线程相关问题使用jstack指令(java虚拟机自带的指令)获取JVM中指定进程的当前所有线程的堆栈跟踪信息。
二、jstack介绍
1、用法: jstack [ options ] pid
2、作用
1)jstack命令用于打印指定Java进程、核心文件或远程调试服务器的Java线程的Java堆栈跟踪信息。
2)jstack命令可以生成JVM当前时刻的线程快照。线程快照是当前JVM内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。
3)如果java程序崩溃生成core文件,jstack工具可以用来获得core文件的java stack和native stack的信息,从而可以轻松地知道java程序是如何崩溃和在程序何处发生问题。
3、jstack生成的线程调用堆栈快照中的线程状态
- NEW 未启动的,不会出现在Dump中;
- RUNNABLE 在虚拟机内执行的;
- BLOCKED 受阻塞并等待监视器锁;
- WATING 无限期等待另一个线程执行特定操作;
- TIMED_WATING 有时限的等待另一个线程的特定操作;
- TERMINATED 已退出的;
4、jstack日志分析要点
1)查看具有相同堆栈跟踪的线程;
当应用程序中存在性能瓶颈时,大多数线程将开始在该有问题的瓶颈区域上累积。这些线程将具有相同的堆栈跟踪。因此,每当大量线程表现出相同/重复的堆栈跟踪时,就应该研究这些堆栈跟踪。这可能存在性能问题。
以下是一些方案:
- 假设外部服务正在变慢,那么大量线程将开始等待其响应。在这种情况下,这些线程将表现出相同的堆栈跟踪。
- 假设一个线程获得了一个锁,它从未被释放过,那么处于相同执行路径的其他几个线程将进入阻塞状态,表现出相同的堆栈跟踪。
- 如果循环(for 循环, while 循环, do..while 循环) 条件不会终止,则执行该循环的多个线程将呈现相同的堆栈跟踪。
eg:
此应用程序运行正常,但突然间变得无响应。获取来自此应用程序的dump。显示400个线程中的225个线程表现出相同的堆栈跟踪:
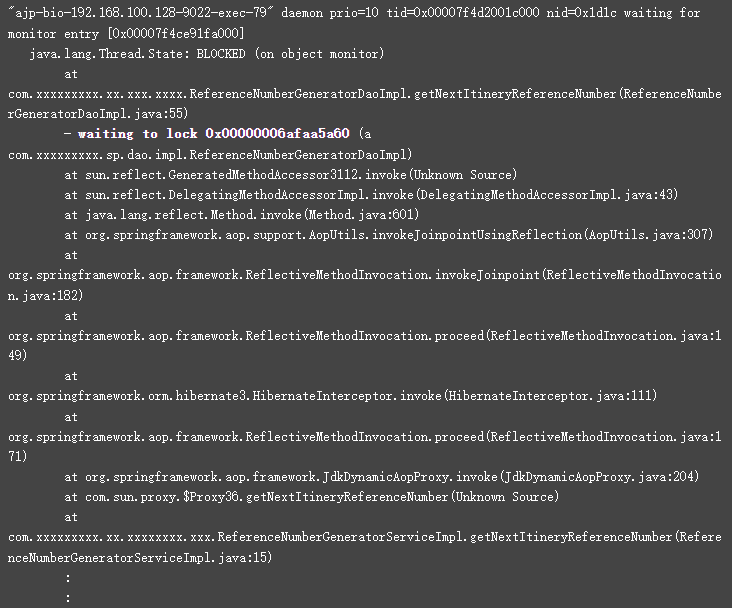
从堆栈跟踪中可以推断出线程被阻止并等待对象上的锁定0x00000006afaa5a60。225 个这样的线程正在等待获得同一对象上的锁定。这绝对是一个不好的迹象,说明线程匮乏。
这个锁是由“ajp-bio-192.168.100.128-9022-exec-84”持有的。下面是堆栈跟踪此线程。此线程0x00000006afaa5a60获取了对象上的锁,但在获取锁后,卡住了等待数据库的响应。对于此应用程序数据库,未设置超时。因此,此线程的数据库调用再也没有返回。由于这个原因,其他225个线程被卡住了。因此,应用程序变得无响应。
设置正确的数据库超时值后,此问题消失了。
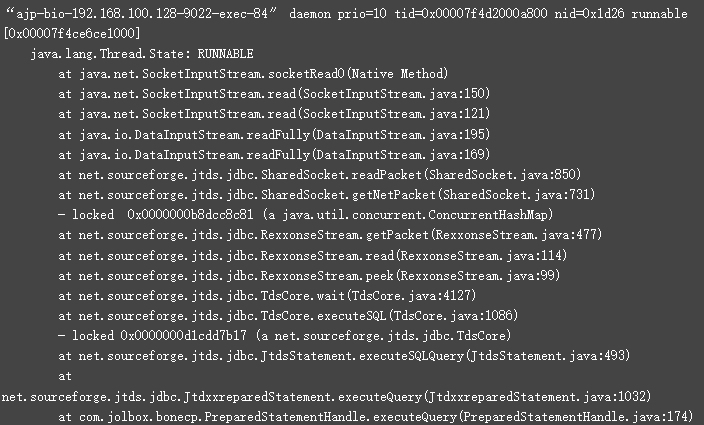
2)如果应用程序占用大量 CPU,重点查看处于 run状态的线程
3)是否存在阻塞线程,阻止其他线程的线程显示在此处。阻塞线程使应用程序无响应。
线程A可能已获取锁 1,但永远不会释放它。线程B可能已获取锁 2 并等待此锁 1。线程C可能正在等待获取锁 2。线程之间的这种传递块可能会使整个应用程序无响应。
补充:Monitor
Monitor是 Java中用以实现线程之间的互斥与协作的主要手段,它可以看成是对象或者 Class的锁。每一个对象都有,也仅有一个 monitor。下 面这个图,描述了线程和 Monitor之间关系,以及线程的状态转换图:
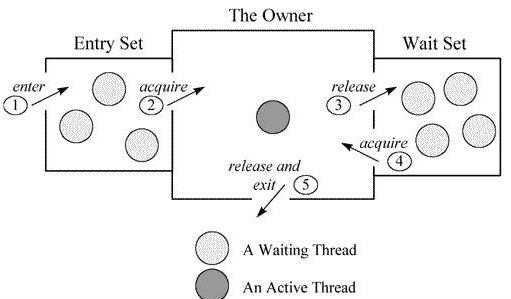
进入区(Entry Set):表示线程通过synchronized要求获取对象的锁。如果对象未被锁住,则进入拥有者,否则则在进入区等待。一旦对象锁被其他线程释放,立即参与竞争。
拥有者(The Owner):表示某一线程成功竞争到对象锁。
等待区(Wait Set):表示线程通过对象的wait方法,释放对象的锁,并在等待区等待被唤醒。
从图中可以看出,一个 Monitor在某个时刻,只能被一个线程拥有,该线程就是 “Active Thread”,而其它线程都是 “Waiting Thread”,分别在两个队列 “ Entry Set”和 “Wait Set”里面等候。在“Entry Set”中等待的线程状态是“Waiting for monitor entry”,而在 “Wait Set”中等待的线程状态是 “in Object.wait()”。 先看 “Entry Set”里面的线程。称被 synchronized保护起来的代码段为临界区。当一个线程申请进入临界区时,它就进入了 “Entry Set”队列。
4)GC垃圾处理器
根据所使用的 GC 算法类型(串行、并行、G1、CMS),将创建默认数量的垃圾回收线程。有时,会根据默认配置创建太多无关的GC线程。太多的 GC 线程也会影响应用程序的性能。因此,应仔细配置GC线程计数。
4.1)并行垃圾处理器
如果使用并行 GC 算法,则 GC 线程数由 -XX:并行 GC 线程属性控制。 Linux/x86 计算机上的 -XX:ParallelGCThreads默认值是根据以下公式派生的:
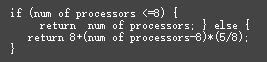
因此,如果JVM在具有32个处理器的服务器上运行,则ParallelGCThread值将为:23(即8 + (32 – 8)*(5/8))。
4.2)CMS垃圾收集器
如果使用 CMS GC 算法,则 GC 线程数由 -XX:并行线程和 -XX:连接线程属性控制。默认值 -XX:康格线程数是根据以下公式派生的:
最大((并行线程+2)/4, 1)因此,如果JVM在具有32个处理器的服务器上运行,那么
- ParallelGCThread值将为:23(即 8 + (32 – 8)*(5/8))
- ConcGCThreads值将是:6。
- 因此,总 GC 线程数为:29(即ParallelGCThread 数 + ConcGCThreads ,即 23 + 6)
4.3)G1垃圾收集器
如果使用 G1 GC 算法,则 GC 线程数由 -XX:并行线程、-XX:连接线程、-XX:G1限制线程属性控制。默认值 -XX:G1组件无限线程是根据以下公式派生的:
并行线程数+1,因此,如果JVM在具有32个处理器的服务器上运行,那么
- ParallelGCThread值将为:23(即 8 + (32 – 8)*(5/8))
- ConcGCThreads值将为:6
- G1ConcRefinementThreads定义线程值将为24(即23 + 1)
- 因此,总 GC 线程数为:53(即ParallelGCThread 数 + ConcGCThreads + G1ConcRefinementThreads,即 23 + 6 + 24)
GC 的 53 个线程是一个相当大的数字。应适当调整。
5)堆栈溢出
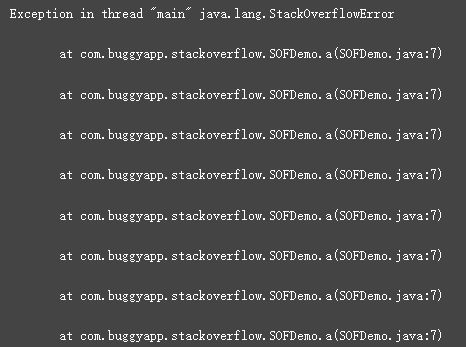
堆栈溢出漏洞的解决方案是什么?
1. 修复代码
由于非终止递归调用等,线程堆栈大小可以增长到很大的大小。在这种情况下,必须修复导致递归循环的源代码。当抛出“堆栈溢出错误”时,它将打印它以递归方式执行的代码的堆栈跟踪。此代码是开始调试和修复问题的良好指针。
2. 增加线程堆栈大小 (-Xs)
可能存在需要增加线程堆栈大小的正当理由。也许线程必须执行大量方法或大量局部变量/在线程一直在执行的方法中创建。在这种情况下,您可以使用 JVM 参数“-Xss”来增加线程的堆栈大小。启动应用程序时需要传递此参数。

6)死锁问题
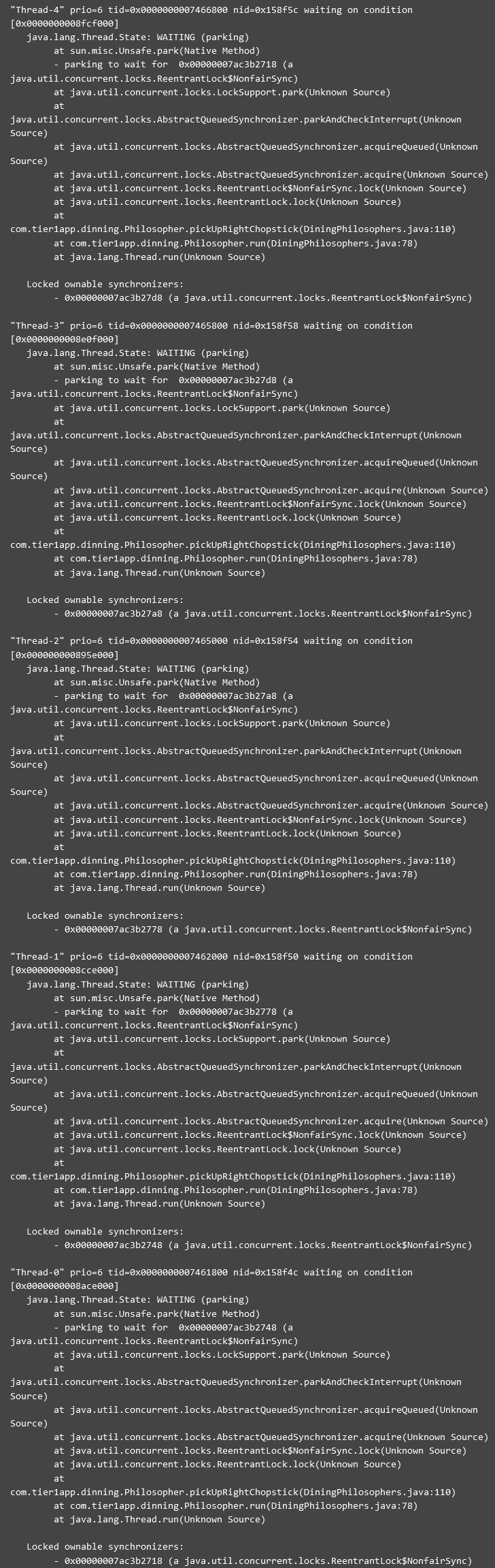
从上面的线程dump中,可以看到
- “线程 4”正在等待由“线程 0”持有的0x00000007ac3b2718
- “线程 0”正在等待由“线程 1”保存0x00000007ac3b2748
- “线程 1”正在等待由“线程 2”保存的0x00000007ac3b2778
- “线程 2”正在等待由“线程 3”持有的0x00000007ac3b27a8
- “线程 3”正在等待由“线程 4”持有的0x00000007ac3b27d8
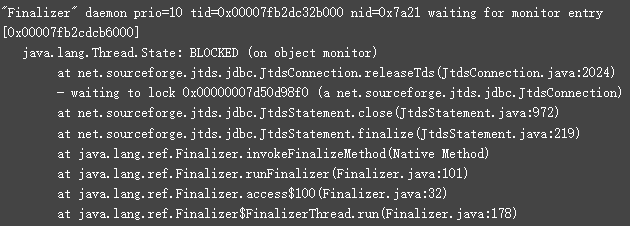
7)、妖精陷阱
在垃圾回收过程中,具有 finalizize()方法的对象与没有它们的对象处理方式不同。在垃圾回收阶段,具有 finalize() 的对象不会立即从内存中逐出。相反,作为第一步,这些对象被添加到 java.lang.ref.终结器对象的内部队列中。有一个名为“Finalizer”的低优先级 JVM 线程,它执行队列中每个对象的 finalize() 方法。只有在执行 finalizize() 方法之后,对象才有资格进行垃圾回收。由于 finalizize()方法的实现不佳,如果Finalizer线程被阻止,将对 JVM 产生严重的级联影响。 java.lang.ref.Finalize 的内部队列将开始增长,导致JVM的内存消耗迅速增长,导致内存不足错误,危及整个JVM的可用性。因此,在分析线程dump时,强烈建议研究Finalizer线程的堆栈跟踪。
eg:在 finalizize() 方法中被阻止的Finalizer线程的示例堆栈跟踪
5、jstack日志日志分析
刷新某个页面造成CPU使用率耗尽的jstack日志如下:
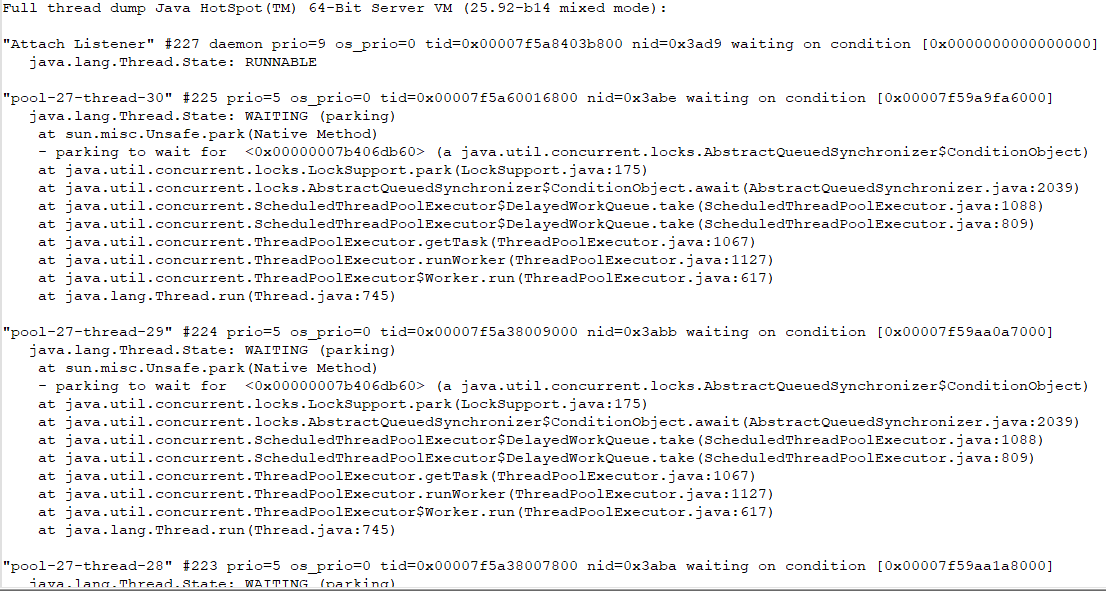
日志分析:
5.1、基础知识点梳理
5.1.1、通过日志可以看到大量线程处于waiting on condition状态,该状态出现在线程等待某个条件的发生;
1)最常见的情况是线程在等待网络的读写数据(即进行网络IO),比如当网络数据没有准备好读时,线程处于这种等待状态。而一旦有数据准备好读之后,线程会重新激活,读取并处理数据;
2)正等待网络读写,这可能是一个网络瓶颈的征兆,因为网络阻塞导致线程无法执行,原因有两种:
一种情况是网络非常忙,几乎消耗了所有的带宽,仍然有大量数据等待网络读写;
另一种情况也可能是网络空闲,但由于路由等问题,导致包无法正常的到达;
3)该线程在 sleep,等待 sleep的时间到了时候,将被唤醒。
推荐阅读https://zhuanlan.zhihu.com/p/475571849
5.1.2、伪运行状态
处于“可运行”状态的线程会消耗 CPU。因此,当分析线程dump以消除高 CPU 消耗时,应彻底检查处于“可运行”状态的线程。通常在线程dump中,多个线程被分类为“RUNNABLE”状态。但实际上,一部分实际上并没有RUN状态,而是在等待。但是,JVM仍然将它们归类为“可运行”状态。
eg:
在这些堆栈跟踪中,线程实际上并不处于“可运行”状态。即没有主动执行任何代码。只是在等待套接字读取或写入。因为JVM并不真正知道线程的native方法中正在做什么,JVM将它们分类为“RUNNABLE”状态。实际运行的线程将消耗 CPU,而这些线程处于 I/O 等待状态,不消耗任何 CPU。
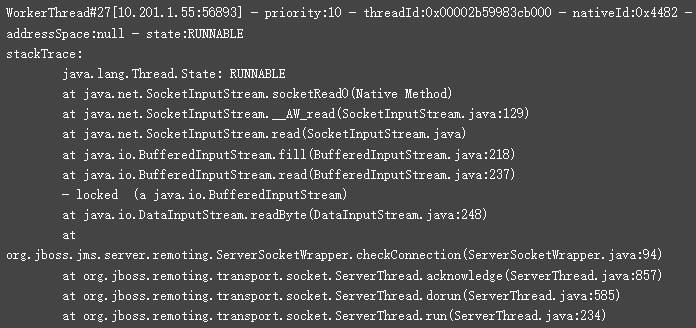
5.2、通过可视化工具分析(推荐在线分析网站https://fastthread.io/ft-index.jsp)
1)使用top指令查看内存正常;
2)分析GC线程状况
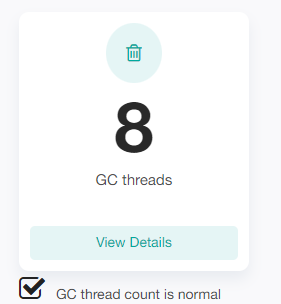
GC线程数正常;
3)查看是否存在阻塞线程
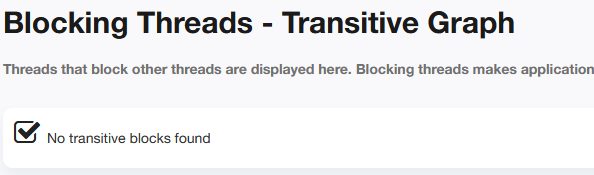
检测结果未发现异常。
4)常见情况下的异常检测(死锁、终结器线程等)
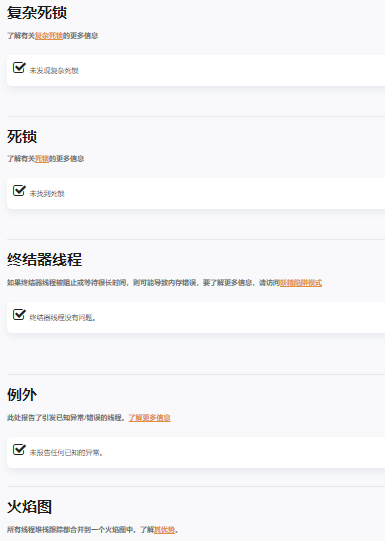
如图可知,并未发现异常情况;
5)排除了以上情况,说明没有明显的代码护或者环境配置异常,对于CPU消耗过高的情况,分析RUN状态的线程

查看cpu占用最高的线程的pid
top -Hp pid
根据进程号查看堆栈信息
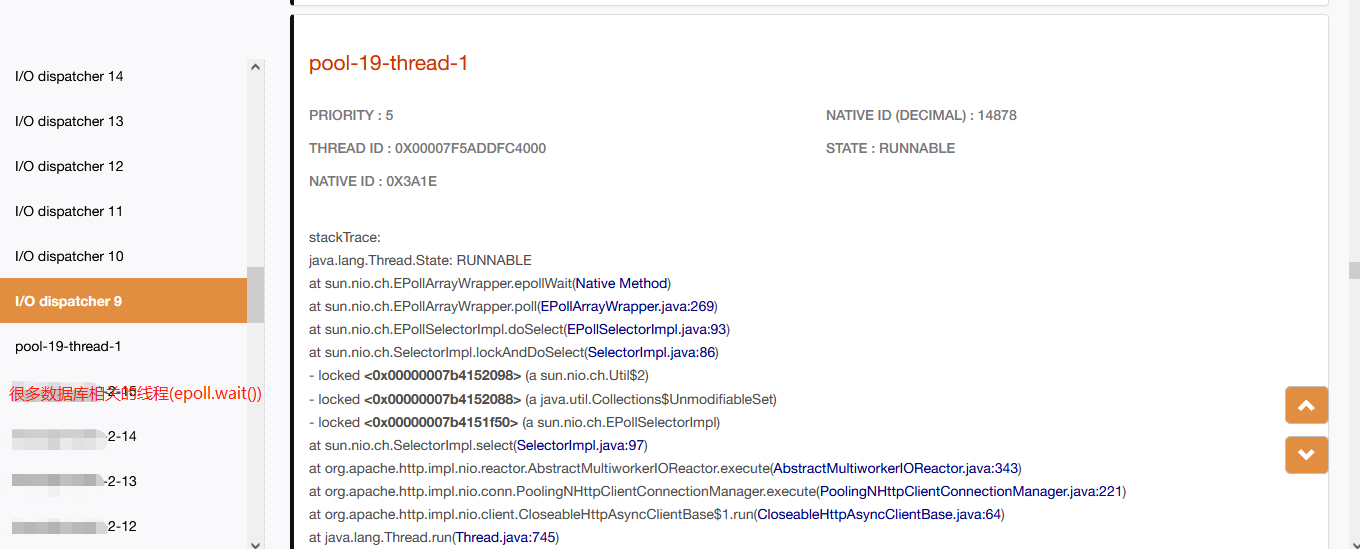
jstack 1 | grep -A 10 "0x88"(线程号转为16进制)
对比两个堆栈日志发现,占用CPU高的线程是数据库进行网络IO线程,线程正在等待系统调用epoll实例事件。
补充:
epoll_wait()系统调用等待文件描述符epfd引用的epoll实例上的事件。事件所指向的存储区域将包含可供调用者使用的事件。 epoll_wait()最多返回最大事件。 maxevents参数必须大于零。 timeout参数指定epoll_wait()将阻止的最小毫秒数。 指定超时值为-1会导致epoll_wait()无限期阻塞,而指定的超时时间等于零导致epoll_wait()立即返回,即使没有可用事件。

火焰图
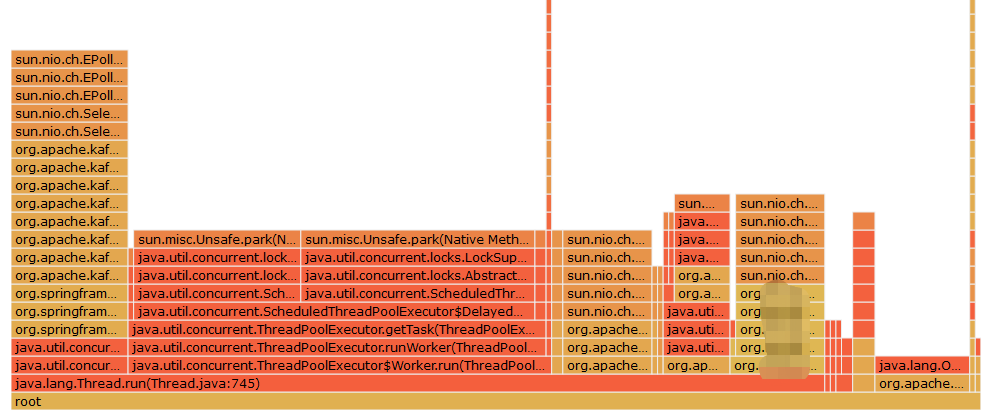
确定问题原因,排查刷新页面时的日志中的sql,从数据库执行发现有脏数据导致的一个sql执行时一直不返回查询结果,数据进行清洗,测试,系统正常。
推荐相关文章:
https://blog.csdn.net/lsz137105/article/details/104644396
https://blog.csdn.net/zhoumuyu_yu/article/details/112476477
感谢阅读,借鉴了不少大佬资料,如需转载,请注明出处,谢谢!https://www.cnblogs.com/huyangshu-fs/p/16718553.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2019-10-05 数据库系统(一)--数据模型