

AI项目实战(基础概念)
一、概念
1、人工智能、机器学习、深度学习
(1)人工智能;
(2)机器学习(从数据中自动分析获得的模型,并利用模型对未知数据进行预测)是人工智能的一个实现途径,即选择合适的算法对模型训练;
(3)深度学习是机器学习的一个方法发展而来。
2、人工智能三要素:数据、算法、计算力;
3、人工智能主要分支
通讯、感知、行动是现代人工智能的三个关键能力,主要应用于以下领域:
(1)计算机视觉(CV);
(2)自然语言处理(NLP);
在NLP领域中,将覆盖文本挖掘/分类、机器翻译和语音识别;
(3)机器人。
4、特征工程
使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程;即数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已;特征工程的目的是把原始的数据转换为模型可用的数据。
5、特征工程内容:
1)、特征提取
又叫作“降维”,指使用映射或变换的方法将维数较高的原始特征转换为维数较低的新的特征,目前线性特征的常用提取方法有主成分分析(Principle ComponentAnalysis,PCA)、线性判别分析(Linear Discriminant Analysis,LDA)和独立成分分析(Independent Component Analysis,ICA)。;
特征工程的目的是把原始的数据转换为模型可用的数据,主要包括三个子问题:
2)、特征构造
特征构造一般是在原有特征的基础上做“组合”操作,例如,对原有特征进行四则运算,从而得到新的特征。
3)、特征选择
即从原始的特征中挑选出一些具有代表性、使模型效果更好的特征。
补充:特征预处理
1)特征预处理定义:通过⼀些转换函数将特征数据转换成更加适合算法模型的特征数据过程;
2)归一化/标准化
特征的单位或者⼤⼩相差较⼤,或者某特征的⽅差相⽐其他的特征要⼤出⼏个数量级,容易影响(⽀配)⽬标结果,使得⼀些算法⽆法学习到其它的特征。
6、样本、特征
在数据集中一般一行数据称为一个样本,一列数据称为一个特征。
有些数据有目标值(标签值),有些数据没有目标值 。
数据类型构成:
数据类型一:特征值+目标值(目标值是连续的和离散的)
数据类型二:只有特征值,没有目标值。
机器学习一般将数据集会划分为两个部分:
训练数据:用于训练.构建模型 ;
测试数据:在模型校验时使用,用于评估模型是否有效。
划分比例:
训练集: 70 % 80 % 75 % ·
测试集: 30 % 20 % 25 %
二、机器学习算法分类
根据数据集组成不同,可以把机器学习算法分为:监督学习、无监督学习、半监督学习、强化学习;(放图,一目了然,有图有真相)
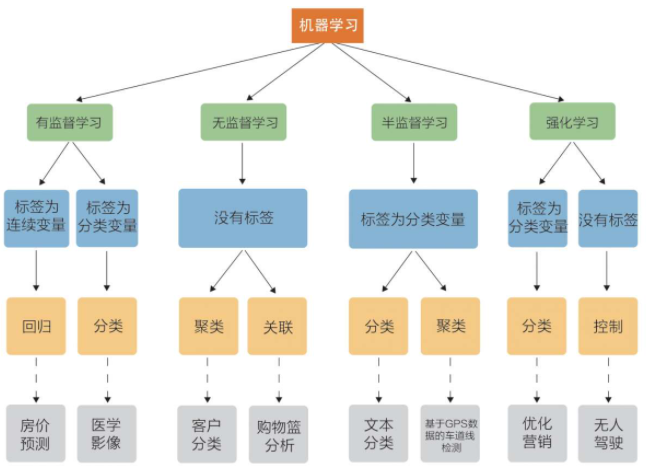
(1)监督学习:输入数据是由输入特征值和目标值所组成的;
详解:当我们已经拥有一些数据及数据对应的类标时,就可以通过这些数据训练出一个模型,再利用这个模型去预测新数据的类标,这种情况称为有监督学习。有监督学习可分为回归问题和分类问题两大类。在回归问题中,我们预测的结果是连续值;而在分类问题中,我们预测的结果是离散值。常见的有监督学习算法包括线性回归、逻辑回归、K-近邻、朴素贝叶斯、决策树、随机森林、支持向量机等。
(1.1)函数的输出可以是一个连续的值(称为回归);
eg:预测房价,根据样本拟合一条连续曲线。
(1.2)输出是有限个离散值(称作分类);
eg:电影根据剧情作分类,得到的结果是离散的。
(2)无监督学习:输入数据是由输入特征值组成,没有目标值;
详解:在无监督学习中是没有给定类标训练样本的,这就需要我们对给定的数据直接建模。常见的无监督学习算法包括K-means、EM算法等
(2.1)输入数据没有被标记,也没有确定的结果,样本数据类别未知;
(2.2)需要根据样本间的相似性对样本集进行类别划分;
eg:根据样本集特征大致划分,无目标值;
(3)半监督学习:训练集同时包含有标记样本数据和未标记样本数据;
详解:半监督学习介于有监督学习和无监督学习之间,给定的数据集既包括有类标的数据,也包括没有类标的数据,需要在工作量(例如数据的打标)和模型的准确率之间取一个平衡点。
监督学习训练方式;
半监督学习训练方式;
(4)强化学习:
从不懂到通过不断学习、总结规律,最终学会的过程便是强化学习。强化学习很依赖于学习的“周围环境”,强调如何基于“周围环境”而做出相应的动作。
(4.1)本质是make decisions即问题自动决策,并且可以做连续决策;
(4.2)强化学习的目标就是获得最多的累计奖励;
(4.3)主要包含5个元素:agent、action、reward、enviroment、observation.
(5)引申:
独立同分布:在概率论理论中,如果变量序列或者其他随机变量有相同的概率分布,并且相互独立,那么这些随机变量是独立同分布(即每次抽样之间独立而且同分布(样本服从同一分布));
三、模型评估
1、按照数据集的目标值不同,可以把模型评估分为分类模型评估和回归模型评估。
1)、分类模型评估
准确度:预测正确的数占样本总数的比例;
其他评价指标:精确度、召回率、AUC指标等。
2)、回归模型评估
均方根误差(RMSE),eg:房价预测准确度。
其他评估指标:相对平方误差、平均绝对误差、相对绝对误差。
2、拟合
模型评估用于评价训练好的模型的表现效果,其表现效果大致可以分为如下两类(常见表现是在训练集中的表现很好,误差也不大,但是在测试集上问题很多);
1)欠拟合:模型学习太过于粗糙,连训练集中的样本数据特征关系都没有学习出来。
2)过拟合:所建的机器学习模型或者是深度学习模型在样本训练中表现得过于优越,导致在测试数据集中表现不佳。
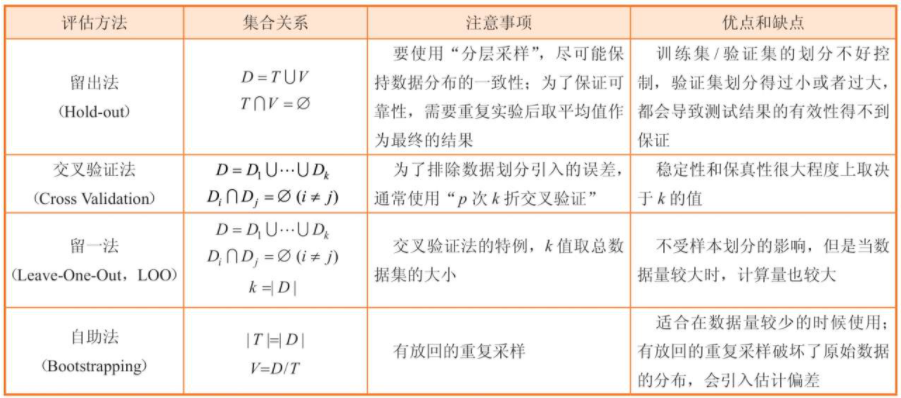
3、模型评估的常见方法:
留出法、交叉验证法、留一法及自助法。
四、机器学习的一般流程
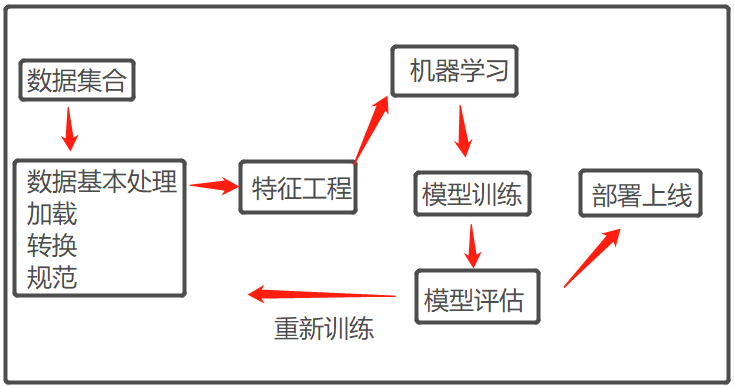
常用数据预处理的方式:
(1)归一化
归一化指将不同变化范围内的值映射到一个固定的范围里,例如,常使用min-max等方法将数值归一化到[0,1]的区间内(有些时候也会归一化到[-1,1]的区间内)。归一化的作用包括无量纲化[插图]、加快模型的收敛速度,以及避免小数值的特征被忽略等。
(2)标准化
标准化指在不改变数据原分布的前提下,将数据按比例缩放,使之落入一个限定的区间,让数据之间具有可比性。需要注意的是,归一化和标准化各有其适用的情况,例如在涉及距离度量或者数据符合正态分布的时候,应该使用标准化而不是归一化。常用的标准化方法有z-score等。
(3)离散化
离散化指把连续的数值型数据进行分段,可采用相等步长或相等频率等方法对落在每一个分段内的数值型数据赋予一个新的统一的符号或数值。离散化是为了适应模型的需要,有助于消除异常数据,提高算法的效率。
(4)二值化
二值化指将数值型数据转换为0和1两个值,例如通过设定一个阈值,当特征的值大于该阈值时转换为1,当特征的值小于或等于该阈值时转换为0。二值化的目的在于简化数据,有些时候还可以消除数据(例如图像数据)中的“杂音”。
(5)哑编码
哑编码,又称为独热编码(One-Hot Encoding),作用是对特征进行量化。例如某个特征有三个类别:“大”“中”和“小”,要将这一特征用于模型中,必须将其数值化,很容易想到直接给它们编号为“1”“2”和“3”,但这种方式引入了额外的关系(例如数值间的大小关系),“误导”模型的优化方向。一个更好的方式就是使用哑编码,例如“大”对应编码“100”,“中”对应编码“010”,“小”对应编码“001”。如果将其对应到一个三维的坐标系中,则每个类别对应一个点,且三个点之间的欧氏距离相等。
四、深度学习
是机器学习的一个分支,也称为深度结构学习、或者深度机器学习,是一类算法集合。
1、深度学习的应用
自然语言处理、语音识别与合成、图像领域
查阅和参考了不少资料,感谢各路大佬分享,如需转载请注明出处,谢谢:https://www.cnblogs.com/huyangshu-fs/p/14722122.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号