一、SQL基本概念:
SQL 已经成为关系数据库的标准语言,是一种数据库查询和程序设计语言,用 于存取数据以及查询、更新和管理关系数据库系统。 功能不仅仅是查询,还包括数据定义、数据操纵和数据控制等于数据库有关的 一系列功能。
四大功能:数据查询、数据定义、数据操纵和数据控制。
1)嵌入式和动态 SQL 规则 规定了 SQL 语句在高级程序设计语言中使用的规范方法,以便适应较为复杂的 应用。
2)SQL 调用和会话规则 调用包括 SQL 例程和调用规则,以便提高 SQL 的灵活性、有效性、共享性以 及使 SQL 具有更多的高级语言的特征。
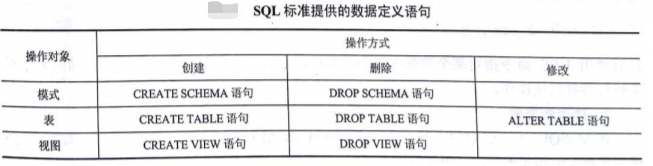
3)关系数据库系统支持三级模式结构,其模式、外模式和内模式中的基本对象有 数据库模式、表、索引、视图等。 SQL 标准提供的数据定义语句如下表:
二、MySQL
1、MySQL基础概念
MySQL 是一个关系数据库管理系统(RDBMS),它具有客户/服务器体系结构。
MySQL 中的 SQL 作为一种关系型数据库管理系统,遵循 SQL 标准,提供了对数据定义语言 DDL、数据操纵语言 DML、数据控制语言 DCL 的支持,同样支持关系数据库的三级模式结构。 MySQL 中一个关系对应一个基本表,一个或多个基本表对应一个存储文件,一 个表可以有若干索引,索引也存放在存储文件中。
MySQL 在 SQL 标准的基础上增加了部分扩展的语言要素:包括常量、变量、 运算符、表达式、函数、流程控制语句和注解等。
1)常量 是指在程序运行过程中值不变的量,也称为字面值或标量值。常量的使用格式 取决于值的数据类型,可分为字符串常量、数值常量、十六进制常量、时间日期常量、位字段值、布尔值和 NULL 值。
字符串常量是指用单引号或双引号括起来的字符序列,分为 ASCII 字符串常量 和 Unicode 字符串常量。
十六进制值通常指定为一个字符串常量,每对十六进制数字被转换为一个 字符,其最前面有一个大写字母 X 或小写字母 x。
日期和时间常量是用单引号将表示日期时间的字符串括起来构成的。 使用 b‘value’格式书写位字段值。Value 是一个用 0 或 1 书写的二进制值。
2)变量 在 MySQL 中,变量分为用户变量和系统变量。用户变量前常添加一个符号 “@”,大多数系统变量前,添加两个“@”符号。
3)运算符 MySQL 几类编程语言中常用的运算符:
算术运算符:+(加)、—(减)、*(乘)、/(除)和%(求模)
位运算符有:&(位与)、|(位或)、^(位异或)、~(位取反)、>>(位右 移)、<<(位左移)。
比较运算符:=(等于)、>(大于)、<(小于)、>=(大于等于)、<=(小 于等于)、<>(不等于)、!=(不等于)、<=>(相等或都等于空)。
逻辑运算符:NOT 或!(逻辑非)、AND 或&&(逻辑与)、OR 或||(逻辑 或)、XOR(逻辑异或)
4)表达式 是常量、变量、列名、复杂计算、运算符和函数的组合。 表达式可分为字符表达式、数值型表达式和日期表达式。
5)内置函数 MySQL 包含了 100 多个函数,基本分类如下:
数学函数,例如 ABS()函数、SORT()函数; 聚合函数,例如 COUNT()函数;
字符串函数,例如 ASCII()函数、CHAR()函数;
日期和时间函数,例如 NOW()函数、YEAR()函数;
加密函数,例如 ENCODE()函数、ENCRYPT()函数;
控制流程函数,例如 IF()函数、IFNULL()函数;
格式化函数,例如 FORMAT()函数;
类型转换函数,例如 CAST()函数;
系统信息函数,例如 USER()函数、VERSION()函数。
2、索引定义
(1)索引是 DBMS 根据表中的一列或若干列按照一定顺序建立的列值与记录行之间的对应关系表,因而索引实质上是一张描述索引列的列值与原表中记录行之间 一一对应关系的有序表。
(2)索引在逻辑上通常包含以下几类:
2.1)普通索引:最基本的索引类型,没有任何限制;
2.2)唯一性索引:索引列中的所有值都只能出现一次,必须是唯一的;
2.3)主键:一种唯一性索引。
(3)索引存在的弊端如下:
3.1)索引是以文件的形式存储的,DBMS 会将一个表的所有索引保存在同一个索引文件中,索引文件需要占用磁盘空间。
3.2)索引在提高查询速度的同时,却会降低更新表的速度。
(4)相关SQL
查询已创建的索引 show {index|indexes} {in|from} test_table;
创建索引 create index index_name on test_table(s_name,s_age);
创建索引(使用alter table的方式) alter table test_table add index index_name(s_name,s_age)
删除索引 drop index index_name on test_table;
删除索引(使用alter table的方式) alter table test_table drop index index_name;
3、视图
(1)视图是数据库中的一个对象,它是数据库管理系统提供给用户的以多种角度观察数据库中数据的一种重要机制。外模式对应到数据库中的概念就是视图。
(2)视图仍不同于数据库中真实存在的基本表,它们存在以下区别:
1)视图不是数据库中真实的表,而是一张虚拟表。
2)视图的内容是由存储在数据库中进行查询操作的 SQL 语句来定义的,它的列数据与行数据均来自于定义视图的查询所引用的真实表,并且这些数据是在引用视图时动态生成的。
3)视图不是以数据集的形式存储在数据库中,它所对应的数据实际上是存储在视图所引用的真实表中。
4)视图是用来查看存储在别处的数据的一种虚拟表,而其自身并不存储数据。
(3)使用视图有如下优点:
1)集中分散数据;
2)简化查询语句;
3)重用 SQL 语句:保护数据安全;共享所需数据;更改数据格式。
(4)相关SQL示例
创建视图 create or replace view cus_view as select * from test_table where s_age = 19 with check option;
删除视图 drop view cus_view;
查询创建的视图 show create view cus_view;
数据操作
-- 添加 insert into customers_view values(0,'ww',1,'ww','ww');
-- 更新 update customers_view set cust_name='qq' where cust_id=5;
-- 删除 delete from customers_view where cust_id=5;
-- 查询 select * from cus_view;
4、触发器
(1)触发器是用户定义在关系表上的一类由事件驱动的数据库对象,也是一种保证数据完整性的方法。触发器一旦定义,无须用户调用,任何对表的修改操作均为数据库服务器自动激活相应的触发器。触发器与表的关系十分密切,其主要作用是实现主键和外键不能保证的复杂的参照完整性和数据的一致性,从而有效地保护表中的数据。
(2)SQL示例
创建触发器 create trigger trigger_name trigger_time trigger_event on table_name for each row trigger_body;
5、封锁
封锁是最常用的并发控制技术,它的基本思想是:需要时,事务通过向系统请求对它所希望的数据对象加锁,以确保它不被非预期改变。
(1) 锁
一个锁实际上就是允许或组织一个事务对一个数据对象的存取特权。基本的封锁类型有两种:排他锁(X锁)和共享锁(S锁)。
(2)用封锁进行并发控制
工作原理是:
(1) 若事务 T 对数据 D 加了 X 锁,则所有别的事务对数据 D 的锁请求都必须等待直到事务 T 释放锁。
(2) 若事务 T 对数据 D 加了 S 锁,则别的事务还可对数据 D 请求 S 锁,而对数据 D 的 X 锁请求必须等待直到事务 T 释放锁。
(3) 事务执行数据库操作时都要先请求相应的锁,即对读请求 S 锁,对更新(插入、删除、修改)请求 X 锁。这个过程一般是由 DBMS 在执行操作时自动隐含地进行。
(4) 事务一直占有获得的锁直到结束(COMMIT 或 ROLLBACK)时释放。因此,利用封锁机制可以解决并发操作所带来的三个不一致问题。
(3)封锁的粒度
以粒度来描述封锁的数据单元的大小。DBMS 可以决定不同粒度的锁。由最底层的数据元素到最高层的整个数据库,粒度越细,并发性就越大,但软件复杂性和系统开销也就越大。
(4)封锁的级别
封锁的级别又称为一致性级别或隔离度。由各种锁的类型与其封锁期限组合可形成不同的封锁级别:
(1)0 级封锁
(2)1 级封锁
(3)2 级封锁
(4)3 级封锁
(5)”活锁”与“死锁”现象分析
在并发事务处理过程中,由于锁会使一事务处于等待状态而调度其他事务处理,因而该事务可能会因优先级低而永远等待下去,这种现象称为“活锁”。活锁问题的解决与调度算法有关,一种最简单的办法是“先来先服务”。两个以上事务循环等待被同组中另一事务锁住的数据单元的情形,称为“死锁”。DBMS 需要提供死锁预防、死锁检测和死锁发生后的处理技术与方法。预防死锁的办法在操作系统中已普遍讨论,其中主要有如下几种:
(1) 一次性锁请求
(2) 锁请求排序
(3) 序列化处理
(4) 资源剥夺
(6)可串行性
一组事务的一个调度就是它们的基本操作的一种排序。若在一个调度中,对于任意两个事务 T1 和 T2,要么 T1 的所有操作都在 T2 所有操作之前,要么反之,则该调度室串行的,因而是正确的。通常,在数据库系统中,可串行性就是并发执行的正确性准则,即当且仅当一组事务的并发执行调度是可串行化,才认为它们是正确的。
(7)两段封锁法
采用两段封锁法是一种最简单而有效的保障封锁其调度是可串行性的方法。两段锁协议规定在任何一个事务中,所有加锁操作都必须在所有释放锁操作之前。其中,事务划分成如下两个阶段。
(1) 发展(Growing)或加锁阶段
(2) 收缩(Shrinking)或释放锁阶段
定理:遵循两段锁协议的事务的任何并发调度都是可串行化的。
非常感谢您的阅读,如需转载请注明出处,本文链接https://www.cnblogs.com/huyangshu-fs/p/11782784.html




