

hadoop 中 datanode 与 那么浓的
数据量越来越多,在一台PC的范围存不下了,那么就分配到更多的PC中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。分布式文件管理系统很多,Hadoop的HDFS只是其中一种。 HDFS主要分为两大角色,NameNode与DataNode,NameNode主要负责管理元数据,DataNode主要负责存储文件块。NameNode来管理datanode与文件块的映射关系。
一、NameNode的工作机制
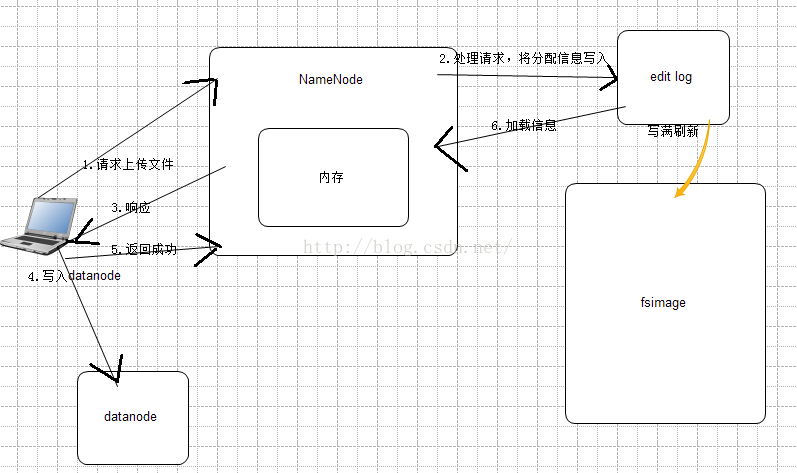
当客户端想HDFS请求,上传的文件的时候,NameNode会先去检查,要上传文件的目录是否存在,不存在,则允许上传。得到允许和NameNode返回的DataNode信息后,客户端开始向DataNode写入block,而block的副本的复制(NameNode管理),与客户端上传是异步进行的。
HDFS为了快速的响应客户端的请求,也为了安全性的考虑(NameNode管理所有datanode,namenode宕机或者损坏,内存中的数据丢失,datanode中的所有数据就会无效),为了防止这种情况的发生,NameNode是如何实现的?
当客户端请求namenode时,namenode会将客户端的数据进行分析,分配好datanode,并将信息记录在一个editslog的文件中,并将datanode信息返回给客户端,客户端得到信息后,开始写入,每完成一个block,客户端会发发送成功信息给namenode,namenode就会把editlog中的信息,加载进内存,这样即使断电或者宕机,namenode中内存的数据也可以恢复,其他客户端想要下载数据,也可以从内存中加载,实现了快速响应。
editlog的空间是有限的,集群运行时间编边长的时候,editlog写满后,hdfs会将editlog的数据写入fsimage,也就是fsimage中的数据是最全,而editlog是最近最新更新的数据,为了保证fsimage中的数据与内存中的数据保证一致性,当editlog写满时,editlog中数据就会与fsimage的信息做合并,刷到fsimage中。
editlog与fsimage的合并工作由secondnamenode来完成的。
当editlog与fsimage合并时,secondnamenode会进行checkpoint操作(合并),namenode产生新的editlognew,而停止向老editlog写入。secondnamenode会从namenode中下载editlog与faimage,进行合并,产生新的合并文件。合并完成后,上传到Namenode上,namenode就会把新的镜像文件替换老的fsimage,经editlognew重命名为editlog,一切恢复初始。

什么时候checkpoint?
1.fs.checkpoint.period 指定两次checkpoint的最大时间间隔,默认3600秒。
2.fs.checkpoint.size 指定edits log文件的最大值,一旦超过这个值则进行checkpoint,不管是否到达最大时间间隔。默认大小是64M。(配置参数写在hdfs-site.xml中)
元数据的存储形式:
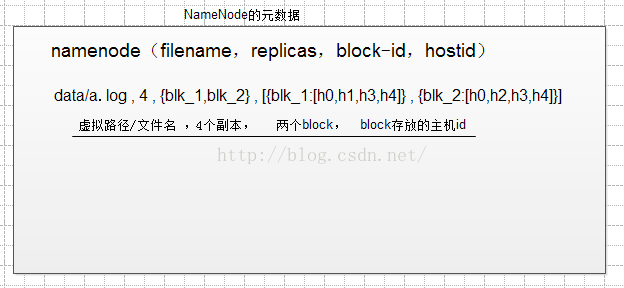
所以,多小文件往HDFS中存,会浪费NameNode的元数据空间。
namenode宕机了,在恢复正常之前。hadoop集群还能正常提供服务吗?
hadoop2.x提供了高可用机制,可以有效解决这个问题。
二、DataNode的工作机制
datanode的工作机制相对简单,提供文件数据的存储服务,存储单位是文件块(block),对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block。HDFS默认Block大小是128MB。dfs.block.size可以配置block的大小。
如果一个文件小于一个数据块的大小仍然占用一个block,并不占用整个数据块存储空间,但是在namenode中占用一条元数据。
dfs.replication参数配置副本数,默认3个。
block的存储位置:
/hadoop-2.4.1/data/dfs/data/current/BP-980638925-127.0.0.1-1460262510326/current/finalized
在HDFS中有两种节点,分别是NameNode和DataNode。NameNode负责集群中与存储相关的调度,DataNode负责具体的存储任务。具体来说NameNode维护了整个文件系统的元数据信息, 这些信息以两种形式的文件存储,一种是镜像文件(image文件),另一种是编辑日志(edit log)。NameNode会在文件系统启动时,动态地加载这些文件到内存中以响应客户端的读写请求。
DataNode用来执行具体的存储任务:存储文件块。另外它也会定时的通过心跳向NameNode报告自己的状态(包括存储的文件块的信息)。
NameNode的安全模式:在启动NameNode后,它会进入安全模式,所谓“安全模式”是指,在此期间它会接收DataNode的心跳包及块的状态信息,以此来判断块的副本安全性。在达到一定比例的块副本安全性时,NameNode将退出安全模式。
NameNode的安全保障:
NameNode的作用在HDFS的集群中显而易见。一般而言,有两种机制来保证其自身及其上数据的安全。一种是同步转储其上的元数据文件,另一种是采用Secondary NameNode,具体机制前文已分析过了。
————————————————
版权声明:本文为CSDN博主「别等时光染了梦想」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wangxueqing52/article/details/79866177

