

es 部署
部署操作
1 环境准备
1.1 修改host 主机名,加入hosts解析
# hostnamectl set-hostname es1
# cat >> /etc/hosts << EOF
192.168.234.160 es1
EOF
1.2 关闭防火墙
# systemctl stop firewalld
# systemctl disable firewalld
1.3 禁用selinux
# sed -ri 's#(SELINUX=)enforcing#\1disabled#' /etc/selinux/config
# grep ^SELINUX= /etc/selinux/config
# setenforce 0
1.4 配置免密登录
# ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa -q
# for ((i=160;i<=162;i++));do ssh-copy-id 192.168.234.${i};done
1.5 安装数据同步工具rsync , 用于之后实验的数据快速同步
# yum install rsync -y
# rsync -az filename ip:/path/
1.6 时间同步
#yum install -y ntpdate chrony
这里同步aliyun的时间服务器
# vim /etc/chrony.conf
server ntp.aliyun.com iburst
server ntp1.aliyun.com iburst
server ntp2.aliyun.com iburst
server ntp3.aliyun.com iburst
server ntp4.aliyun.com iburst
# systemctl start chronyd
2 es 部署
2.1 下载地址:# https://www.elastic.co/cn/downloads/elasticsearch
rpm包安装
# yum localinstall elasticsearch-7.17.3-x86_64.rpm -y
启动服务
systemctl start elasticsearch.service
默认监控在9200和9300端口,9200是服务对外提供服务, 9300是集群之间通信的
配置修改
#vim /etc/elasticsearch/elasticsearch.yml
cluster.name: my-application 集群名称
node.name: es1 节点名称
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch 日志路径
network.host: 0.0.0.0 监控地址
http.port: 9200 监听端口
discovery.seed_hosts: ["host1", "host2"] 集群节点发现列表这里域名如果报错的话可以用ip代替
cluster.initial_master_nodes: ["es1"] 集群节点列表
查看服务状态
#curl 192.168.234.160:9200/_cat/nodes?v
3 kibana 部署
3.1 下载部署包,注意要与es 版本一直
# yum localinstall kibana-7.17.3-x86_64.rpm -y
修改配置文件
# vim /etc/kibana/kibana.yml
server.host: 0.0.0.0 绑定所有ip地址
elasticsearch.hosts : ["http://ip:9200"] 配置es 节点的ip端口,如果是集群,这写多个节点的
i18n.locale: "zh-CN" 设定语言中文
启动服务 监听端口默认5601
#systemctl start kibana
3.2 kibana使用
页面通过堆栈检测 可以获取es 集群状态检测数据,
通过stack Management - 索引管理 可以看到所有的索引数据
4 logstash 部署
下载对应版本安装包
# yum localinstall logstash-7.17.3-x86_64.rpm -y
# ln -s /usr/share/logstash/bin/logstash /usr/local/bin/ 做一个软连接,可以直接生效logstash命令
4.2 配置修改
input { 输入
tcp { 如tcp的999端口监听
type => "name" 写一个标记名, 用于后面输出匹配不同的索引
pront => 9999
}
}
output { 输出
stdout {}
if [type] == "name" { # 根据标记分配不同的索引,输出到es
elasticsearch {
hosts => ["127.0.0.1:9200"]
指定的索引
index => "name-%{+YYYY.MM.dd}"
}
}else if [type] == "" {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => ""
}
}else {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => ""
}
}
#如输出到redis
redis {
host => "127.0.0.1"
port => "6379"
db => 10 数据库编号
password => "1232" 密码
data_type => “list” 写入的数据类型
key => “name” 指定key的名称
}
file {} 输出到文件
elasticsearch { # 输出到es
hosts => ["127.0.0.1:9200"]
index => "" #定义索引
}
}
# logstash -tf **.conf 测试配置文件是否正常
配置参考:https://www.elastic.co/guide/en/logstash/8.5/index.html
5 filebeat 组件配置
#指定输入类型
filebeart.inputs:
- type : stdin # 指定输入的类型为标准输入
enabled : false # 禁用这个type类型 , 默认是true
- type :log # 指定输入类型为log类型
paths : # 指定路径
- /var/log/*.log # 收集此目录下的所有日志文件
tags : ["json"] # 打标签 后面在输出到不通的索引可以根据此做判断
json.keys_under_root: true # 根据日志的json格式定义,对日子进行字段的拆分,方便直接查看对应字段的值
fields: # 自定义数据信息
school :“北京”
# 指定输出的类型
output.console:
pretty : true #打印漂亮的格式
output.elasticsearch: # 输出到es
hosts: ["http://ip:port"]
index : “%{[fields.log_type]}-%{[agent-version]}-%{+yyyt.MM.dd}” # 指定索引, 若不指定默认是filebeat-开头, 索引是es的存储单元
index: "oldboy-%{+yyyy.MM.dd}"
#定义多个索引
indices:
- index : “oldboy”
when.contains : # 根据tag的不同分配到不同的索引
tags : "oldby"
- index : “python”
when.contains : # 根据tag的不同分配到不同的索引
tags : "pyhon"
setup.ilm.enabled : false # 禁用索引管理, 这样自定义索引才科生效
setup.template.name : "oldboy" # 创建一个索引模板
setup.template.pattern : "oldboy*" # 模板的匹配规则
#覆盖已有的索引模板
setup.template.overwrite : false
#配置模板
setup.template.settings :
index.number_of_shards : 3 #设定分片数 默认1
index.number_of_replicas : 3 # 设定副本数 默认1 , 设定副本的数量要小于集群节点的数量 , 否则es集群状态时yellow , 副本是只读
运行filebeat :
# filebeat -e -c /etc/filebeat/conf.yml
./filebaeat/log.json 这个文件放置了收集日志文件的位置, 这个与偏移量有关, 如收集数据时候会根据这个文件来标识上次到什么地址, 这次接着取收集
es集群节点状态颜色:
红色 : 表示集群的部分主分片未正常工作
黄色:表示集群的副本未正常使用
绿色: 表示集群的主分片和副本 均正常
配置操作
对收集的日志进行拆分 这样方便查看 ,获取关键信息 如收集nginx的日志并对其拆分:
方法一:
通过修改nignx原生的日志格式为json
# vim /etc/nginx/nginx.conf
http {
log_format nginx_json '{"@timestamp":"$time_iso8601",'
'"host": "$server_addr",'
'"client": "$remote_addr",'
'"size": $body_bytes_sent,'
'"responsetime": $request_time,'
'"domain": "$host",'
'"url":"$request_uri",'
'"referer": "$http_referer",'
'"agent": "$http_user_agent",'
'"status":"$status",'
'"x_forwarded_for":"$http_x_forwarded_for"}';
access_log /var/log/nginx/access.log nginx_json;
}
# vim /etc/filebeat/filbeat.yml
filebeart.inputs:
- type :log # 指定输入类型为log类型
paths : # 指定路径
- /var/log/nginx/*.log # 收集此目录下的所有日志文件
json.keys_under_root: true # 根据日志的json格式定义,对日子进行字段的拆分,方便直接查看对应字段的值
日志输出格式
![]()
修改tomcat 日志的json格式
#vim /etc/tomcat/conf/server.xml
<host name="tomcat.com" appBase="webapps"
unpackWARs="true" autoDeploy="true">
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="access" suffix=".log"
pattern="{"requestTime":"%t","clientIP":"%h","threadID":"%I","protocol":"%H","requestMethod":"%r","requestStatus":"%s","sendBytes":"%b","queryString":"%q","responseTime":"%Dms","partner":"%{Referer}i","agentVersion":"%{User-Agent}i"}"
/>
</host>
# vim /etc/filebeat/filebeat.yml # filebeat配置文件
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/tomcar/*.log
json.keys_under_root: true # 对json日志进行拆分,显示
方法二:
通过filebeat 的模块取处理
# vim /etc/filebeat/filebeat.yml
filebeat.config.modules: # 取代input定义字段 , 利用模块会自己进行日志的拆分 path : ${path.config}/modules.d/*.yml # 加载这个安装目录下的所有yml结尾文件 reload.enabled: true # 是否开启热加载功能,默认false
# 修改modes.d 下的nginx.yml配置文件
# vim .../modes.d/nginx.yml
- module : nginx
access:
enabled : true # 启用
var.paths: ["/var/log/nginx/access.log*"] # 日志路径
# filebeat -c /etc/filebeat/filebeat.yml modules list # 查看启动的模块和禁用的模块
# filebeat -c /etc/filebeat/filebeat.yml modules enable nginx # 启用nginx 模块
模块管理收集tomcat的日志:
# filebeat -c /etc/filebeat/filebeat.yml modules enable tomcat # 启动tomcat 模块
#修改tomcat 模块配置文件
# vim 。。。/modules.d/tomcat.yml
- module tomcat
log:
enabled: true
var.input: file #指定读取文件的数据, 不指定默认是取读取udp的数据 ,有三种获取的类型, tcp , udp , file
var.paths:
- /var/log/tomcat/*.log
方法三:
通过logstash 的filter插件取处理
filebeat 多行匹配配置
#vim /etc/filabeat/filebeat.yml
filebeat.inputs:
- type:log
enabled: true
paths:
- /var/log/tomcat/*.log
multiline.type: pattern # 匹配类型,匹配到进行换行处理
multiline.pattern: '^\d{2}' #以匹配数据开头
multiline.negate: true # 可设定false 和true 两个值
multiline.match: after #可设定after 和before 两个值
# 数据过滤,只有包含指定内容才会采集,区分大小写
include_lines: ['ERR','^WARN','\[error\]']
# 排除, 包含指定内容的不采集
exclude_lines: ['DBG','^linux']
negate 和match 值介绍:
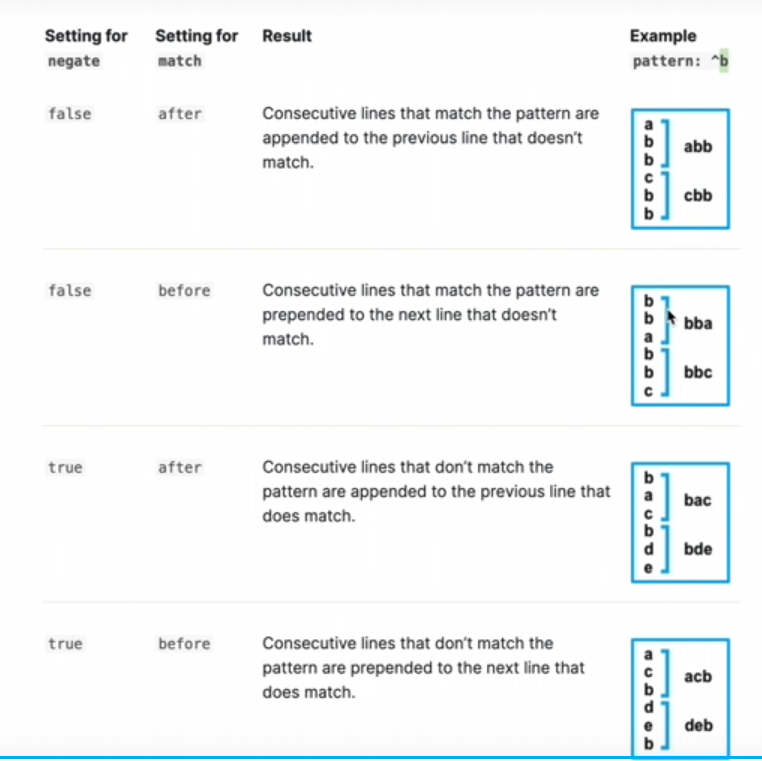
filestream 的配置
#vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: filestream # filestream 类型 与log类型相似只是写法不一样
paths:[]
parsers: #需要配置解析器
- ndjson: # json格式日志显示
keys_under_root: true
message_key: msg
- multiline: # 多行匹配设定
type: pattern
pattern: '^\d{2}'
negate: true
match: after

