hadoop之shuffle详解
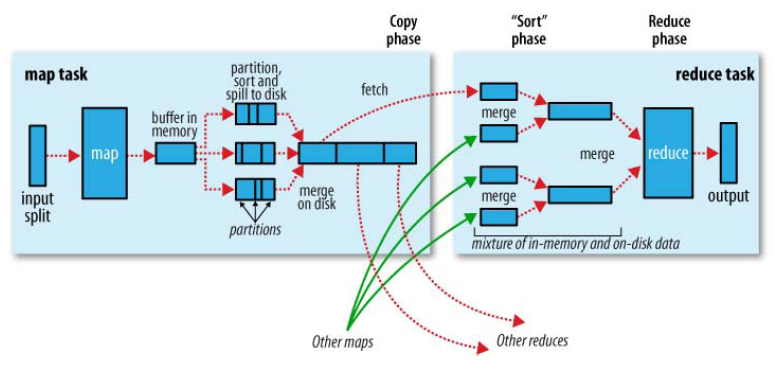
Shuffle描述着数据从map task输出到reduce task输入的这段过程。
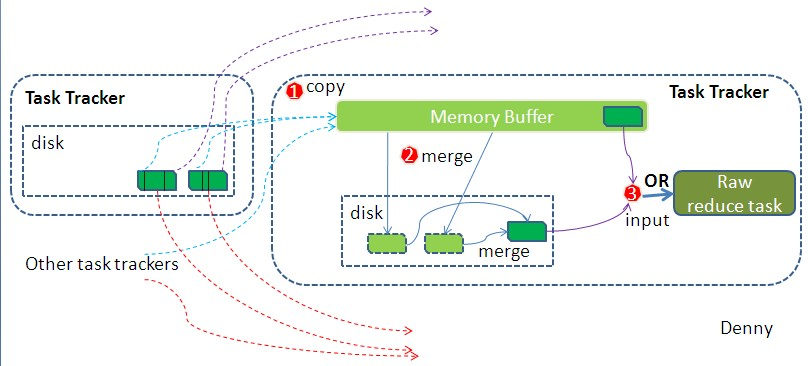
如map 端的细节图,Shuffle在reduce端的过程也能用图上标明的三点来概括。当前reduce copy数据的前提是它要从JobTracker获得有哪些map task已执行结束,这段过程不表,有兴趣的朋友可以关注下。Reducer真正运行之前,所有的时间都是在拉取数据,做merge,且不断重复地在做。下面分段地描述reduce 端的Shuffle细节:
1. Copy过程,简单地拉取数据。Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。因为map task早已结束,这些文件就归TaskTracker管理在本地磁盘中。
2. Merge(合并)阶段。这里的merge如map端的merge动作,只是数组中存放的是不同map端copy来的数值。Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置,因为Shuffle阶段Reducer不运行,所以应该把绝大部分的内存都给Shuffle用。这里需要强调的是,merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。默认情况下第一种形式不启用,让人比较困惑,是吧。当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的那个文件。
3. Reducer的输入文件。不断地merge后,最后会生成一个“最终文件”。为什么加引号?因为这个文件可能存在于磁盘上,也可能存在于内存中。对我们来说,当然希望它存放于内存中,直接作为Reducer的输入,但默认情况下,这个文件是存放于磁盘中的。当Reducer的输入文件已定,整个Shuffle才最终结束。然后就是Reducer执行,把结果放到HDFS上。
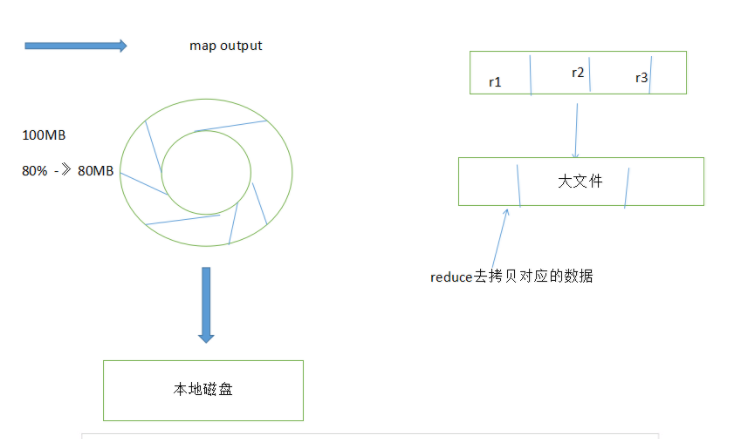
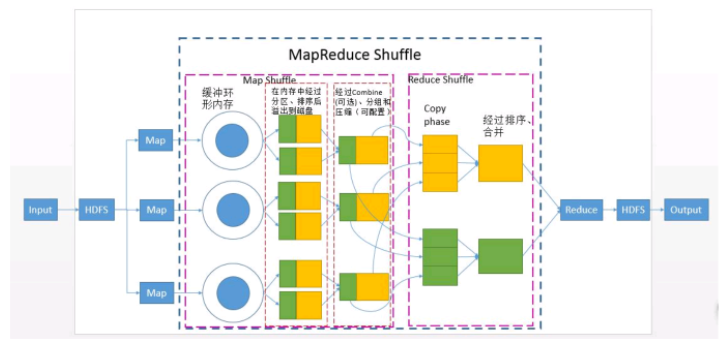
共可分为6个详细的阶段:
1).Collect阶段:将MapTask的结果输出到默认大小为100M的MapOutputBuffer内部环形内存缓冲区,保存
的是key/value,Partition分区
2).Spill阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘
之前需要对数据进行一次排序的操作,先是对partition分区号进行排序,再对key排序,如果配置了
combiner,还会将有相同分区号和key的数据进行排序,如果有压缩设置,则还会对数据进行压缩操作。
3).Combiner阶段:等MapTask任务的数据处理完成之后,会对所有map产生的数据结果进行一次合并操作,
以确保一个MapTask最终只产生一个中间数据文件。
4).Copy阶段:当整个MapReduce作业的MapTask所完成的任务数据占到MapTask总数的5%时,JobTracker就会
调用ReduceTask启动,此时ReduceTask就会默认的启动5个线程到已经完成MapTask的节点上复制一份属于自
己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写
到磁盘之上。
5).Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存中和本地中的数据文件进行
合并操作。
6).Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序,
ReduceTask只需做一次归并排序就可以保证Copy的数据的整体有效性。
文章来源:http://langyu.iteye.com/blog/992916
http://blog.csdn.net/haoyuexihuai/article/details/53037374

 浙公网安备 33010602011771号
浙公网安备 33010602011771号