JanusGraph基于Gremlin使用总结
1,查询label为'document'的点
g.V().hasLabel('document')
2,查询对应属性的点是否存在
g.V().hasLabel("document").has("doc_id","2019-09-23 17:45:26.0_00845569-a566-4270-afa7-aacc00140451")
3,删除点
1 | g.V('600').drop() //id |
4,从顶点开始单步遍历到某层(不返回单步步数超过途径的点和边)
g.V().hasLabel("document").has("doc_id","0007e43b-b3ac-4e6c-9f87-a85100a712cd_2019-10-08 09:46:04.0")
.inE()
.outV()
.inE()
.outV()
.path()
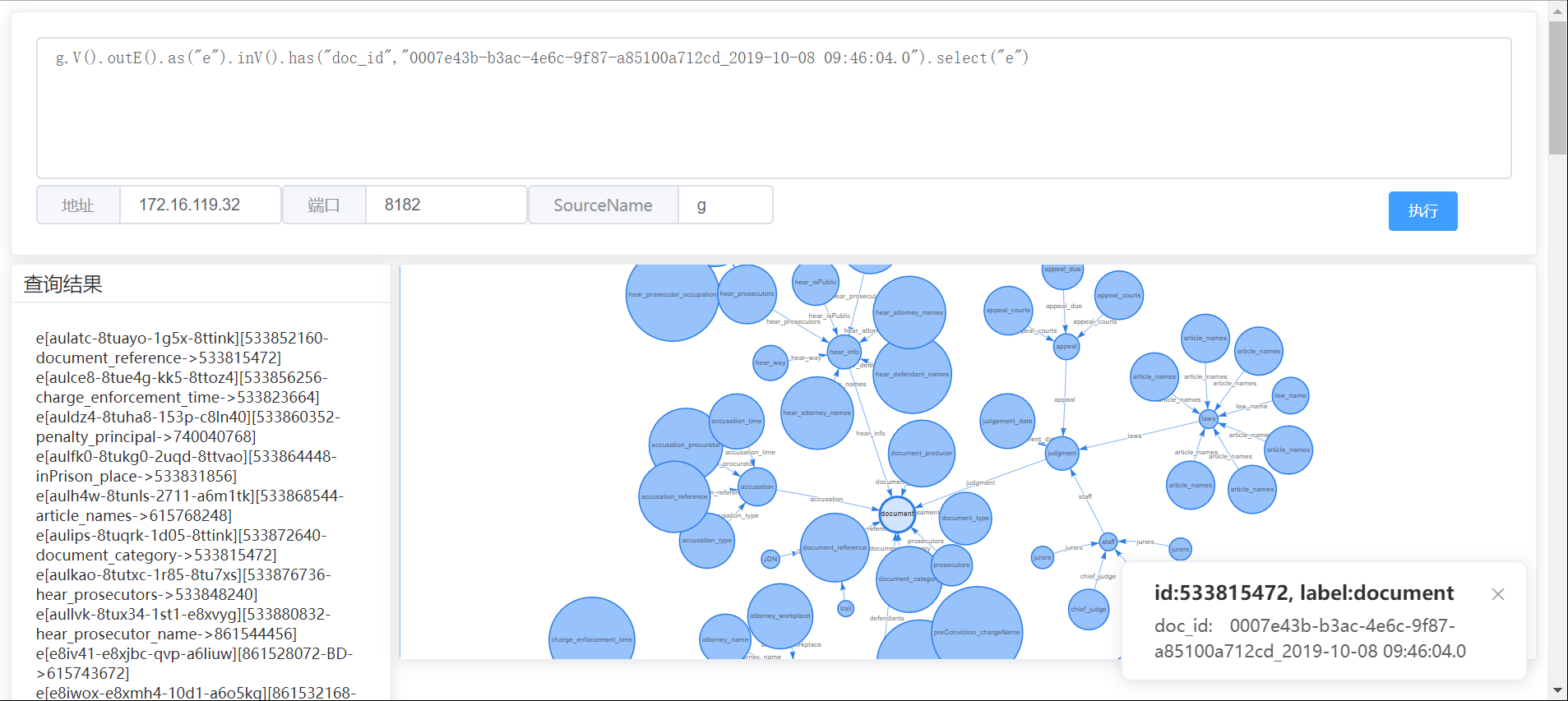
5,查看单个图的整体结构
g.V().outE().as("e").inV().has("doc_id","0007e43b-b3ac-4e6c-9f87-a85100a712cd_2019-10-08 09:46:04.0").select("e")
6,增加点和边,指定属性和label
//非叶子节点 Vertex thisVertex = g.addV(key).property("doc_id", doc_id).next(); g.addE(key).from(thisVertex).to(lastVertex).next(); //叶子节点 vertex = g.addV(key).property("text", text).next(); g.addE(key).from(vertex).to(lastVertex).property("index", index).next();
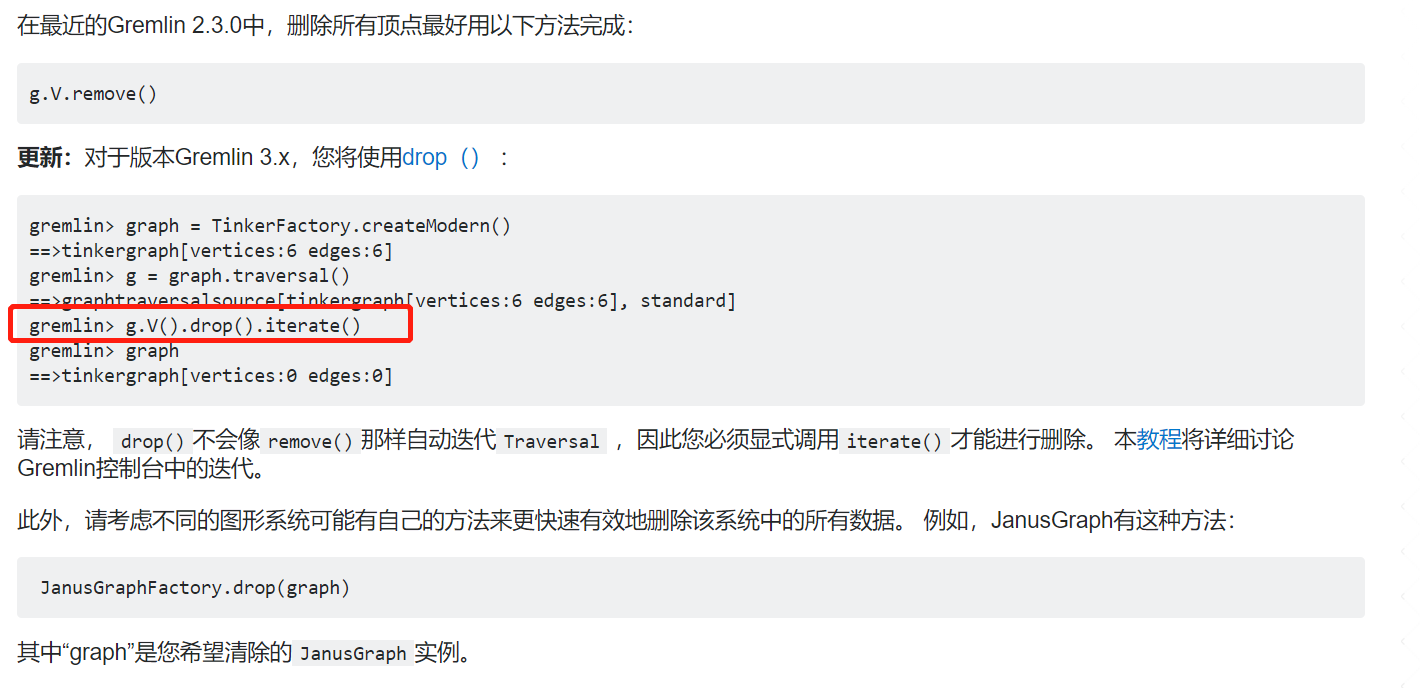
7,清除数据库
g.V().drop().iterate()
参考:https://stackoom.com/question/rlaL/Gremlin%E5%88%A0%E9%99%A4%E6%89%80%E6%9C%89%E9%A1%B6%E7%82%B9
8,查询全表,建索引后不会有warn
g.V().has("doc_id", "ccc_0").inE()
9,启动JN
nohup sh bin/gremlin-server.sh conf/gremlin-server/gremlin-server.yaml &
10,根据点id查询相邻的边id
g.V(12520).outE().id()
11,根据点id查询相邻边的属性
g.V(12520).outE().values()
可以参考连接:https://jiang-anwei.github.io/2019/07/15/JanusGraph%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0/
12,查询顶点个数,是否有无重复节点
g.V().hasLabel("document").has("doc_id", "38020ae26ab87f088d927c8ae604bd01").count()



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?