
Linux九阴真经之大伏魔拳残卷4 nginx(模型,安装配置,模块)
I/O模型
1 .同步/异步:关注的是消息通信机制 (既被调用用者是否返回消息)
同步:synchronous,调用者等待被调用者返回消息,才能继续执行 (被调用者完成任务也不通知调用者,调用者需要时刻检查被调用者是否完成任务,浪费资源)
异步:asynchronous,被调用者通过状态、通知或回调机制主动通知调用者 被调用者的运行状态 (被调用者完成任务后主动发消息通知调用者以完成任务,调用者只需发送指令即可无需时刻去询问被调用者是否完成任务了,节省资源的浪费)
2 . 阻塞/非阻塞:关注调用者在等待结果返回之前所处的状态
阻塞:blocking,指IO操作需要彻底完成后才返回到用户空间,调用结果返回 之前,调用者被挂起 (被调用者未完成任务时,调用者阻塞其他任务。直到等到被调用者完成任务后自己才取消阻塞去干别的事去)
非阻塞:nonblocking,指IO操作被调用后立即返回给用户一个状态值,无需 等到IO操作彻底完成,最终的调用结果返回之前,调用者不会被挂起 。(被调用者未完成任务时,调用者也不会阻塞其他任务,可以去做其他事,等待被调用者完成任务时在去处理)
I/O模型: 阻塞型、非阻塞型、复用型、信号驱动型、异步
下图中的nginx为调用者内核为被调用者:

1 . 同步阻塞IO模型 :
同步阻塞IO模型是最简单的IO模型,被调用者完成任务后也不会发送消息通知调用者已完成任务;调用者的其他任务被阻塞,无法去做其他的任务只能每隔一段时间去查看被调用者是否完成任务,如果完成才可以进行后续任务的调用。对CPU的资源利用率不够 ,浪费资源。
2 . 同步非阻塞IO模型 :
被调用者完成任务后也不会发送消息通知调用者已完成任务;但调用者不阻塞其他任务,此时也可以执行其他任务的调用,但由于被调用者不会发送消息告知调用者已完成任务,所以需要调用者需要不断的重复的发起询问被调用者是否已完成任务,也是浪费cpu的资源。
整个IO请求的过程中,虽然用户线程每次发起IO请求后可以立即返回,但是为 了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源
3 . IO多路复用模型(同步多路阻塞的I/O模型;可以并发的响应多个请求)(常用的类型)
多个连接共用一个等待机制,本模型会阻塞进程,但是进程是阻塞在select或者poll这两 个系统调用上,而不是阻塞在调用者上面。(多个系统调用者。找个代理人去和被调用者内核去打交道;只是一次 可以执行多个任务)
用户首先将需要进行IO操作(调用者)添加到select中,继续执行做其他的工作(异步),同时等 待select系统调用返回。当数据到达时,IO被激活,select函数返回。用户线程正式发起 read请求,读取数据并继续执行。
从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多 了添加监视IO,以及调用select函数的额外操作,效率更差。并且阻塞了两次,但是第 一次阻塞在select上时,select可以监控多个IO上是否已有IO操作准备就绪,即可达到在 同一个线程内同时处理多个IO请求的目的。而不像阻塞IO那种,一次只能监控一个IO
虽然上述方式允许单线程内处理多个IO请求,但是每个IO请求的过程还是阻塞的(在 select函数上阻塞),平均时间甚至比同步阻塞IO模型还要长。如果用户线程只是注册 自己需要的IO请求,然后去做自己的事情,等到数据到来时再进行处理,则可以提高 CPU的利用率
IO多路复用是最常使用的IO模型,但是其异步程度还不够“彻底”,因为它使用了会阻 塞线程的select系统调用。因此IO多路复用只能称为异步阻塞IO模型,而非真正的异步 IO
多路I/O复用的应用场景
IO多路复用是指内核一旦发现进程指定的一个或者多个IO条件准备读取,就通知该进程
IO多路复用适用如下场合:
当客户端处理多个描述符时(一般是交互式输入和网络套接口),必须使用I/O复用
当一个客户端同时处理多个套接字时,此情况可能的但很少出现
当一个TCP服务器既要处理监听套接口,又要处理已连接套接口,一般也要用到I/O 复用 (常用的场景)
当一个服务器即要处理TCP,又要处理UDP,一般要使用I/O复用
当一个服务器要处理多个服务或多个协议,一般要使用I/O复用
4 .信号驱动IO模型(半阻塞状态)
用户进程可以通过sigaction系统调用注册一个信号处理程序,然后主程序可以 继续向下执行,当有IO操作准备就绪时,由内核通知触发一个SIGIO信号处理程 序执行,然后将用户进程所需要的数据从内核空间拷贝到用户空间
此模型的优势在于等待数据报到达期间进程不被阻塞。用户主程序可以继续执 行,只要等待来自信号处理函数的通知
该模型并不常用
5 . 异步IO模型
异步IO与信号驱动IO最主要的区别是信号驱动IO是由内核通知何时可以进行IO 操作,而异步IO则是由内核告诉我们IO操作何时完成了。具体来说就是,信号 驱动IO当内核通知触发信号处理程序时,信号处理程序还需要阻塞在从内核空 间缓冲区拷贝数据到用户空间缓冲区这个阶段,而异步IO直接是在第二个阶段 完成后内核直接通知可以进行后续操作了
相比于IO多路复用模型,异步IO并不十分常用,不少高性能并发服务程序使用 IO多路复用模型+多线程任务处理的架构基本可以满足需求。况且目前操作系统 对异步IO的支持并非特别完善,更多的是采用IO多路复用模型模拟异步IO的方 式(IO事件触发时不直接通知用户线程,而是将数据读写完毕后放到用户指定 的缓冲区中)
I/O模型的具体实现
主要实现方式有以下几种;
Select:Linux实现对应,I/O复用模型,BSD4.2最早实现 (apache上使用的模型)
Poll:Linux实现,对应I/O复用模型,System V unix最早实现
Epoll:Linux实现,对应I/O复用模型,具有信号驱动I/O模型的某些特性 (nginx上使用的模型)
Kqueue:FreeBSD实现,对应I/O复用模型,具有信号驱动I/O模型某些特性
/dev/poll:SUN的Solaris实现,对应I/O复用模型,具有信号驱动I/O模型的 某些特性
Iocp Windows实现,对应第5种(异步I/O)模型
select/poll/epoll三者的相互比较: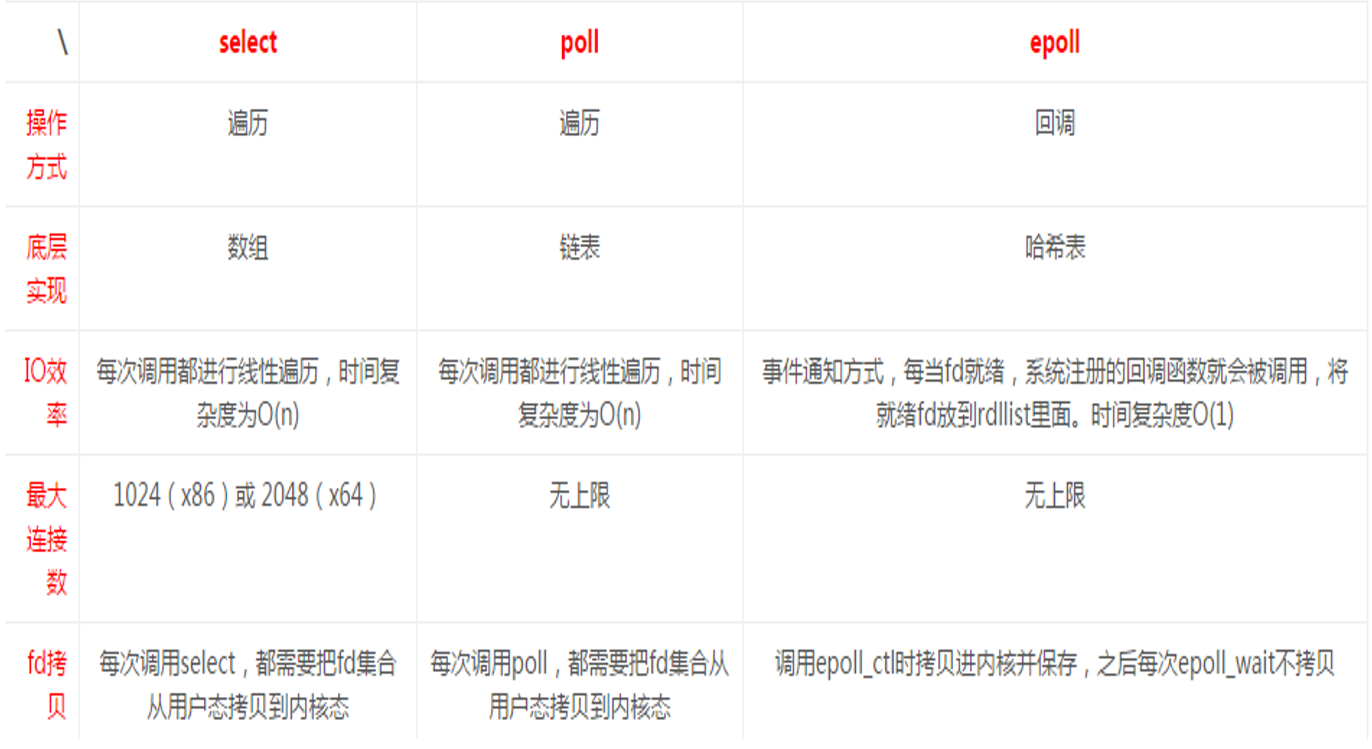
1 . Select:POSIX所规定,目前几乎在所有的平台上支持,其良好跨平台支持也是 它的一个优点,本质上是通过设置或者检查存放fd标志位的数据结构来进行下 一步处理
缺点:
单个进程可监视的fd数量被限制,即能监听端口的数量有限
cat /proc/sys/fs/file-max
对socket是线性扫描,即采用轮询的方法,效率较低
select 采取了内存拷贝方法来实现内核将 FD 消息通知给用户空间,这样一 个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结 构时复制开销大
2 . poll
本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询 每个fd对应的设备状态
其没有最大连接数的限制,原因是它是基于链表来存储的
大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复 制是不是有意义
poll特点是“水平触发”,如果报告了fd后,没有被处理,那么下次poll时 会再次报告该fd
边缘触发:只通知一次
3 . epoll::在Linux 2.6内核中提出的select和poll的增强版本
支持水平触发LT和边缘触发ET,最大的特点在于边缘触发,它只告诉进程哪些fd刚 刚变为就需态,并且只会通知一次
使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采 用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知
优点:
没有最大并发连接的限制:能打开的FD的上限远大于1024(1G的内存能监听约10万 个端口)
效率提升:非轮询的方式,不会随着FD数目的增加而效率下降;只有活跃可用的FD 才会调用callback函数,即epoll最大的优点就在于它只管理“活跃”的连接,而跟 连接总数无关
内存拷贝,利用mmap(Memory Mapping内存映射)加速与内核空间的消息传递;即epoll 使用mmap减少复制开销: 将磁盘里的数据映射到内存的空间上。
Nginx介绍
官网:http://nginx.org
特性:
模块化设计,较好的扩展性
高可靠性
支持热部署:不停机更新配置文件,升级版本,更换日志文件
低内存消耗:10000个keep-alive连接模式下的非活动连接,仅需2.5M内存
event-driven,aio,mmap,sendfile
基本功能:
静态资源的web服务器 (只是静态的,要想运行动态的php程序需要安装对应的php的FastCGI协议)
http协议反向代理服务器
pop3/imap4协议反向代理服务器
FastCGI(LNMP),uWSGI(python)等协议
模块化(非DSO),如zip,SSL模块
nginx的程序架构 (没有线程,一个master带多个worker)
nginx的程序架构:
master/worker结构
一个master进程:
负载加载和分析配置文件、管理worker进程、平滑升级
一个或多个worker进程 (work进程开启的数量时根据服务器的内核数量开启,默认是有个内核就会开启相应个数的work进程数,但在配置文件里可以调整的)
处理并响应用户请求
缓存相关的进程:
cache loader:载入缓存对象
cache manager:管理缓存对象
nginx的模块 :
模块分类:
1 . 核心模块:core module
2 .标准模块:
HTTP 模块: ngx_http_*
HTTP Core modules 默认功能
HTTP Optional modules 需编译时指定 •
Mail 模块 ngx_mail_* • (邮件模块)
Stream 模块 ngx_stream_*
3 . 第三方模块
nginx的安装:
yum install nginx
也可到官网上配的yum仓库来安装最新版的
[nginx]
name=nginx repo
baseurl=http://nginx.org/packages/centos/7/x86_64/
gpgcheck=0
enabled=1
还可以编译安装:
nginx的启动:(两种方法启停服务不能混用)
systemctl start nginx
systemctl stop nginx
还可以不使用systemctl开启服务:
nginx (开启服务)
nginx -s stop (停止服务)
nginx -t (检查配置文件的语法错误)
nginx命令的选项:
-h 查看帮助选项
-V 查看版本和配置选项
-t 测试nginx语法错误
-c filename 指定配置文件(default: /etc/nginx/nginx.conf)
-s signal 发送信号给master进程,signal可为:stop, quit, reopen, reload
示例: -s stop 停止nginx服务 -s reload 加载配置文件当修改配置文件时只需要重新加载以下就可以了
-g directives 在命令行中指明全局指令
nginx配置
帮助文档:http://nginx.org/en/docs/ngx_core_module.html
主配置文件:nginx.conf
子配置文件 include conf.d/*.conf (需要自己新建)
默认主页面路径:/usr/share/nginx/html
日志存放路径:/var/log/nginx/{access.log,error.log} (访问日志和错误日志)
注意:
(1) 指令必须以分号结尾
(2) 支持使用配置变量
nginx的主配置文件里的全局配置:
1 .worker_processes auto; (控制开启的worker进程数量,系统默认是自动的根据内核的个数来开启相应个数的work数,可用lscpu查看CPU个数修改此条命令来设置,例:worker_processes 4;)
2、pid /PATH/TO/PID_FILE 指定存储nginx主进程PID的文件路径 (此文件为nginx运行时生成的临时文件;作用:当执行nginx -s stop命令时会找到此文件里存放的进程编号然后调用kill命令将其终止)
3、include file | mask 指明包含进来的其它配置文件片断
4、load_module file 模块加载配置文件:/usr/share/nginx/modules/*.conf 指明要装载的动态模块路径: /usr/lib64/nginx/modules
nginx常用配置(性能优化相关)
设置worker工作进程数
worker_processes number | auto;
worker进程的数量;通常应该为当前主机的cpu的物理核心数
绑定CPU亲缘性(绑定CPU,指定worker进程运行在第几颗CPU上)
worker_cpu_affinity 0001 0010 0100 1000;
CPU亲缘性,提高缓存命中率
射之前使用 watch 指令动态查看worker进程在工作时间调用的CPU情况,可以看到最后一行的CPU的ID数不断变化
[root@localhost ~]# watch -n 0.5 'ps axo pid,cmd,psr | grep nginx'
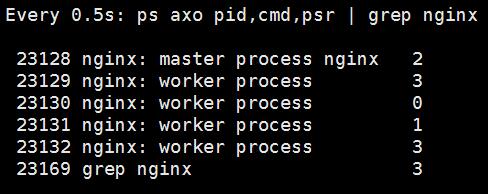
绑定CPU后,执行压力测试 再次查看
[root@localhost ~]# ab -c 1000 -n 100000 http://172.20.107.52/
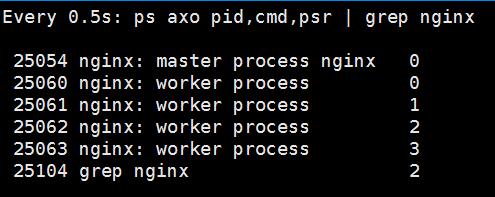
可以看到每个worker进程被固定在单独的CPU上,这样可以加快处理速度
设置worker进程nice值
默认情况下,worker进程的nice值为0,nice值越小,优先级越高
[root@localhost ~]# ps axo pid,cmd,nice | grep nginx 25054 nginx: master process nginx 0 25060 nginx: worker process 0 25061 nginx: worker process 0 #默认为0 25062 nginx: worker process 0 25063 nginx: worker process 0 30663 grep --color=auto nginx 0
修改优先级,-20~19之间
[root@localhost ~]# vim /etc/nginx/nginx.conf user nginx; worker_processes 4; worker_cpu_affinity 0001 0010 0100 1000; worker_priority -5; #设置为-5 error_log /var/log/nginx/error.log; pid /run/nginx.pid; [root@localhost ~]# nginx -s reload [root@localhost ~]# ps axo pid,cmd,nice | grep nginx 25054 nginx: master process nginx 0 30685 nginx: worker process -5 #设置成功 30686 nginx: worker process -5 30687 nginx: worker process -5 30688 nginx: worker process -5 30690 grep --color=auto nginx 0
设置worker进程所能打开的文件数量
worker_rlimit_nofile 65535 (0~65535)
高并发环境要调大该值
用户调试定位问题参数
用户调试定位问题参数 安装时需指定-with-debug
- daemon {on|off}; 是否以守护进程方式运行nginx
- master_process {on | off}; 是否以master或worker模型来运行
- error_log file ; error_log 位置级别,若要使用debug级别,需要编译-with-debug
事件驱动相关的配置: event
设置worker进程最大并发连接数
worker_connections +数量 (系统默认为1024个,高并发环境按需调整该值,要和总数相对应即可)

设置处理新的连接请求方法
accept_mutem on | off;
on指由各个worker轮流处理新的请求,off指每个新请求的到达都会通知(唤醒)所有的worker进程,但只有一个进程可获得连接,造成“惊群”,影响性能。
核心模块参数配置
由 ngx_http_core_module 模块引入
定义主机名
server_name name1 name2...;
虚拟主机的主机名称后可以跟多个由空白字符分割的字符串
tcp_nodelay of | off;
在keepalived模式下的连接是否启用TCP_NODELAY选项
当为off时,延迟发送,合并多个请求后再次发送,默认为on时,不延迟发送,可用于http,server,location
sendfile传输机制
sendfile on | off ;
是否启用sendfile功能,在内核中封装报文直接发送,提高传输性能
设置显示版本信息
server_tokens on | off |build| string
是否在响应报文的Server首部显示nginx版本
指定网站根目录
root /data/www/vhost;
指定网站根目录,用于http,server,location
定义默认页面
index index.php index.html ;
错误页面
error_page
请求页面不存在时,显示指定的页面提示
按顺序检查文件
try_file $uri1 ... uri
按顺序检查文件是否存在,返回第一个找到的文件或文件夹(结尾加斜线表示为文件夹),如果所有的文件或文件夹都找不到,会进行一个内部重定向到最后一个参数。只有最后一个参数可以引起一个内部重定向,之前的参数只设置内部URI的指向。最后一个参数是回退URI且必须存在,否则会出现内部500错误
location /images/ { try_files $uri /images/default.gif; } location / { try_files $uri $uri/index.html $uri.html =404; }
定义location段
location [ = | ~|~*|^~ ] uri {...}
在 一个server中 location配置段可存在多个,用于 实现从uri 到文件系统的路径影射;nginx会根据用户请求的uri 来检查定义的所有location , 并找出一个最佳匹配,而后应用其配置
=:精确匹配 ~:正则表达式模式匹配,匹配时区分大小写 ~*:正则表达式模式匹配,忽略大小写 ^~: url前半部分匹配,不检查正则表达式 匹配优先级: 1,字符字面量最精确匹配, 2,正在表达式检索(由第一个匹配到的所处理) 3,按字符串后续变量比较
在location中可以使用的指令
文件路径定义: root :指定根目录位置 访问路径:从/root/开始匹配 alias路径别名(只用在location中)(不建议使用) index file...; 定义默认页面 error_page 请求页面不存在时,显示指定的页面提示 try_file $uri1... uri 尝试从左向右尝试读取$uri所指定的路径,在第一次找到即停止并返回; 如果所有的path都不存在就回到最后一个uri
定义 status 状态页
location /status { stub_status on; allow 127.0.0.1; }
实例
Active connections: 2 # 当前所有处于打开状态的连接数 server accepts handled requests 615 615 1006 Reading: 0 Writing: 1 Waiting: 1
accepts :已经接收的连接 handled :已经处理过的连接 requests :已经处理过的请求数 ,在保持连接模式下,请求数量可能会大于连接数量 Reading: 正处于接收请求的连接数 Writing: 请求已经接收完成,正处于处理响应过程的连接数 Waiting: 保持连接模式,且处于活动状态的连接数
调试和定位问题
1、daemon on|off 是否以守护进程方式运行nignx,默认是守护进程方式 (所谓的守护进程就是前台执行还是后台执行;此命令必须放到全局配置的语句块里;默认是on的在后台执行的;)
daemon off ; (在前台执行,多用于测试中按ctrl+c就可以关闭nginx服务了)
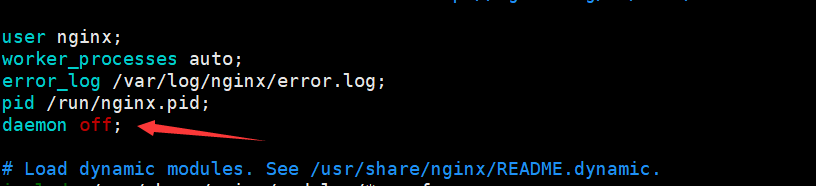
2、master_process on|off 是否以master/worker模型运行nginx;默认为on; 如果设为off 将不启动worker
3、error_log file [level] 错误日志文件及其级别;出于调试需要,可设定为debug;但debug仅在编译时 使用了“–with-debug”选项时才有效
http协议的相关配置:
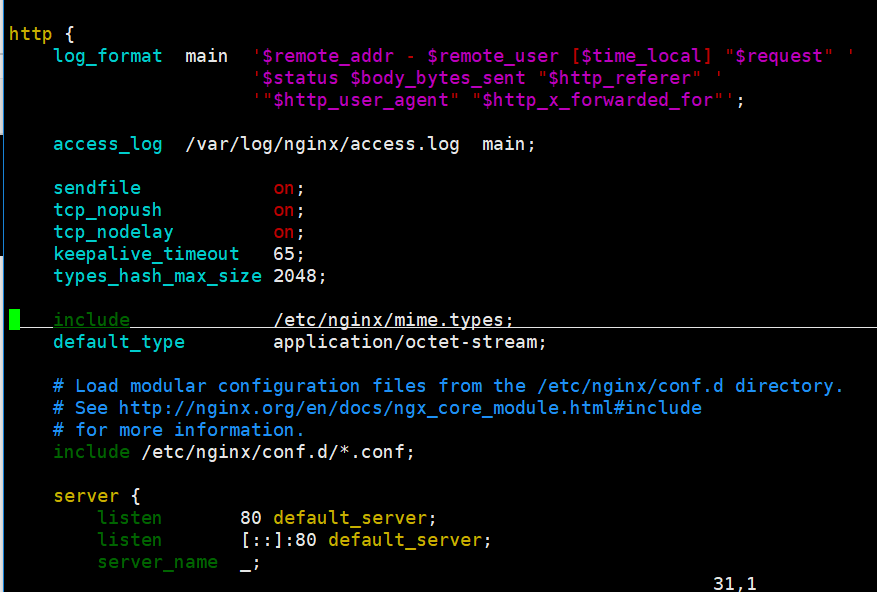
由于在此修改会造成主配置文件的混乱;http服务的设置可以在自定义的配置文件里:/etc/nginx/conf.d/*.conf 里就行了。
配置一个虚拟主机 (基于主机头hostname)

实验
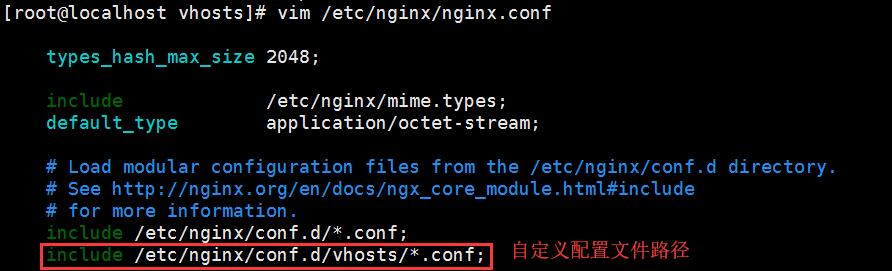
在etc/nginx 目录下创建 vhosts目录 ,用来存放虚拟主机的配置文件;然后创建三台虚拟主机的配置文件 如下
vim /etc/nginx/conf.d/vhosts/a.com.conf (自建的配置文件,参照上述模式来配置搭建三个虚拟主机的各自的配置文件)
server { listen 80; server_name www.a.com; root /data/sitea; }
vim /etc/nginx/conf.d/vhosts/b.com.conf
server { listen 8080; server_name www.b.com; root /data/siteb; }
vim /etc/nginx/conf.d/vhosts/c.com.conf
server { listen 80; server_name www.c.com; root /data/sitec; }
建立三个主机各自的主页面文件:
[root@localhost vhosts]# echo www.a.com >/data/sitea/index.html [root@localhost vhosts]# echo www.b.com >/data/siteb/index.html [root@localhost vhosts]# echo www.c.com >/data/sitec/index.html
nginx -s reload :重新读取配置文件
在另一台主机上访问:由于涉及到dns解析的问题可以临时在客户端将下面命令写到里面:
vim /etc/hosts

此时访问curl www.a.com 返回结果如下

如果访问主机的IP会显示什么?
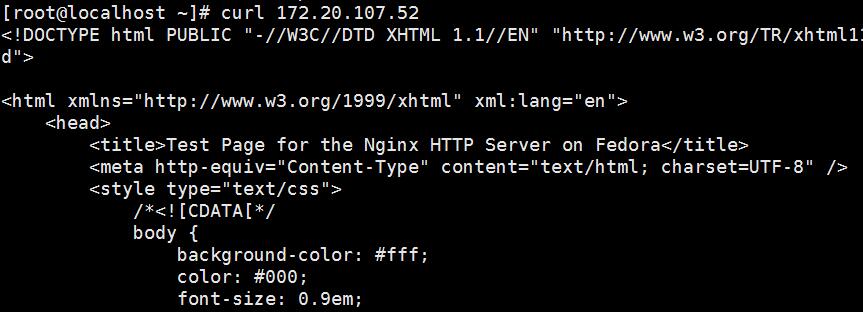
curl 192.168.60.4 此时会出现默认的本机的nginx服务的默认路径:因为前面主配置文件里写了:listen 80 default_server;(为默认)如果想设置其他主机未默认,则需要将主配置文件里的listen 80 后面的default_server删除,保存后在新建的主机配置文件里添加 default_server
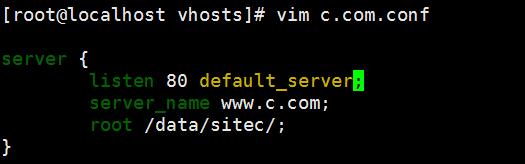
我们从新访问 nginx服务器的IP地址时,默认服务器就发生改变了

ssl 限制仅能够通过ssl连接提供服务
backlog=number 超过并发连接数后,新请求进入后援队列的长度 (既访问数到达上限后,设置一个排队的数目,在后面排队)
rcvbuf=size 接收缓冲区大小
sndbuf=size 发送缓冲区大小
也可以实现基于以下方式来创建虚拟机
基于port; listen PORT; 指令监听在不同的端口
基于ip的虚拟主机 listen IP:PORT; IP 地址不同
3、server_name
虚拟主机的主机名称后可跟多个由空白字符分隔的字符串
支持*通配任意长度的任意字符 server_name *.magedu.com www.magedu.*
支持~起始的字符做正则表达式模式匹配,性能原因慎用 server_name ~^www\d+\.magedu\.com$
匹配优先级机制从高到低:
(1) 首先是字符串精确匹配 如:www.magedu.com
(2) 左侧*通配符 如:*.magedu.com
(3) 右侧*通配符 如:www.magedu.*
(4) 正则表达式 如: ~^.*\.magedu\.com$
(5) default_server
4、tcp_nodelay on | off;
在keepalived模式下的连接是否启用TCP_NODELAY选项
当为off时,延迟发送,合并多个请求后一起发送 请求
默认On时,不延迟发送
可用于:http, server, location (在此语句块里添加)
5、sendfile on | off;
是否启用sendfile功能,在内核中封装报文直接发送
默认Off
6、server_tokens on | off | build | string
是否在响应报文的Server首部显示nginx版本 (默认是启用的)
server_tokens off (此设置在主配置文件的http的语句块里添加)
7、root 定义路径相关的配置
设置web资源的路径映射;用于指明请求的URL所对应的文档的目录路径,可 用于http, server, location, if in location
示例:
定义路径:root /data/www/vhost1;
http://www.magedu.com/images/logo.jpg (访问时输入的路径)
–> /data/www/vhosts/images/logo.jpg (真实文件存放的路径)
本质:当访问//www.magedu.com/时真实的路径就是/data/www/vhost1;
8、location
在一个server中location配置段可存在多个,用于实现从uri到文件系统的路 径映射;ngnix会根据用户请求的URI来检查定义的所有location,并找出一个最 佳匹配,而后应用其配置
示例:
server {…
server_name www.magedu.com;
root /data/www/
location /images/ {
root /app/test/;
}
}
当访问 http://www.magedu.com/images/
–> /app/test/images/
但当访问http://www.magedu.com/时不添加子路径时又会访问/data/www/下的文件
location /images/ {
root /app/test/; (此种做法相当于重新指定了images子路径的真实文件存放的路径;当用户去访问www. magedu.com/images时images目录下的真实问价被指定到了/app/test/; 里面)
使用此种方法可以将多个url的子路径指向不同的路径下:
www.magedu.com/test1——->/data/test1/
www.magedu.com/news1——->/app/news1/
www.magedu.com/hello1——->/root/hello1/
总结:如果将location / 定义为根的话当访问www.magedu.com/时会和系统默认的路径冲突;此时location的优先级比系统默认的根的优先级要高。
9、alias path; 路径别名,文档映射的另一种机制;仅能用于location上下文
location /bbs/ {
alias /web/forum/;
当访问www.magedu.com/bbs/时其真实访问的路径应该是 /web/forum/下的文件
10、index file …; 指定默认网页文件,注意:ngx_http_index_module模块
11、error_page (报错界面)
模块:ngx_http_core_module
可用位置:http, server, location, if in location
自定义错误界面:
server{
error_page 404 /404.html;
location /404.html {
root /data/error/; (错误界面定义的路径)
}
}
然后再/data/error/新建一个404的界面
vim 404.html (新建的错误界面的文件名必须以此为文件名成,因为location /404.html已经定义了错误界面的名称)
<h1>error</h1>
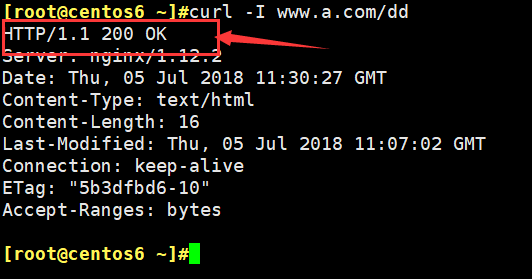
error_page 404 =200 /404.html (将错误的404信息等于200的正确信息不会被浏览器劫持,看到的响应码为200,不是404了,但看到的还是自定义的错误界面)如下图所示:
12、try_files file … uri;
按顺序检查文件是否存在,返回第一个找到的文件或文件夹(结尾加斜线表示 为文件夹),如果所有的文件或文件夹都找不到,会进行一个内部重定向到最 后一个参数。只有最后一个参数可以引起一个内部重定向,之前的参数只设置 内部URI的指向。最后一个参数是回退URI且必须存在,否则会出现内部500错 误
定义客户端请求的相关配置
13、keepalive_timeout timeout [header_timeout]; (长连接;一般情况下为了更多的用户访问可以考虑将长连接关上或者时间设置较短)
设定保持连接超时时长,0表示禁止长连接,默认为75s (如果是游戏业务则需要持续连接)
keepalive_timeout 0
14、keepalive_requests number; 然后就断开连接
在一次长连接上所允许请求的资源的最大数量, 默认为100
15、keepalive_disable none | browser …
对哪种浏览器禁用长连接
16、send_timeout time; (超过规定时间就断开连接)
向客户端发送响应报文的超时时长,此处是指两次写操作之间的间隔时长, 而非整个响应过程的传输时长
17、client_body_buffer_size size;
用于接收每个客户端请求报文的body部分的缓冲区大小;默认为16k;超 出此大小时,其将被暂存到磁盘上的由下面client_body_temp_path指令所定义 的位置
18、client_body_temp_path path [level1 [level2 [level3]]];
设定存储客户端请求报文的body部分的临时存储路径及子目录结构和数量
目录名为16进制的数字; (对文件进行哈希值计算)
client_body_temp_path /var/tmp/client_body 1 2 2 (取 哈希值的第一个第2,3个第4,5个创建文件夹)
1 1级目录占1位16进制,即2^4=16个目录 0-f
2 2级目录占2位16进制,即2^8=256个目录 00-ff
2 3级目录占2位16进制,即2^8=256个目录 00-ff
对客户端进行限制的相关配置
19、limit_rate rate;
限制响应给客户端的传输速率,单位是bytes/second 默认值0表示无限制
limit_rate 1048576(为1M的下载速度)是以字节为单位的
20、limit_except method … { … },仅用于location
限制客户端使用除了指定的请求方法之外的其它方法
method:GET, HEAD, POST, PUT, DELETE , MKCOL, COPY, MOVE, OPTIONS, PROPFIND, PROPPATCH, LOCK, UNLOCK, PATCH
location
limit_except
GET {
allow 192.168.1.0/24;
deny all;
此代码用在location里面
除了GET和HEAD 之外其它方法仅允许192.168.1.0/24网段主机使用
GET包含HEAD(看头部信息的)
文件操作优化的配置
21、aio on | off | threads[=pool];
是否启用aio功能 (系统默认是off的)
22、directio size | off;
directio 4m
当文件大于等于给定大小时,例如directio 4m,同步(直接)写磁盘,而非写缓存
directio off (立即写磁盘而不写入缓存里)
23、open_file_cache off;
open_file_cache max=N [inactive=time];
nginx可以缓存以下三种信息:
(1) 文件元数据:文件的描述符、文件大小和最近一次的修改时间
(2) 打开的目录结构
(3) 没有找到的或者没有权限访问的文件的相关信息
max=N:可缓存的缓存项上限;达到上限后会使用LRU算法实现管理(LRU算法:用的最少的淘汰算法)
inactive=time:缓存项的时间,如果超过此时间还没有人访问此缓存项就将其删除。
open_file_cache_min_uses指令所指定的次数的缓存项即为非活动项,将被删除
24、open_file_cache_errors on | off;
是否缓存查找时发生错误的文件一类的信息 默认值为off
25、open_file_cache_min_uses number;
open_file_cache指令的inactive参数指定的时长内,至少被命中此处指定 的次数方可被归类为活动项
默认值为1
26、open_file_cache_valid time;
缓存项有效性的检查频率 默认值为60s
ngx_http_access_module (允许和拒绝访问的列表)
默认站点搭建起来是不限制用户的访问的
规则:自上而下检查,一旦匹配,将生效,所以要将条件严格的置前
location / {
deny 192.168.1.1; (拒绝此IP的访问)
allow 192.168.1.0/24; (允许此网段的访问)
allow 10.1.1.0/16; (允许此网段的访问)
allow 2001:0db8::/32; (支持IPV6地址段)
deny all; (拒绝所有的访问,即使自己访问自己也被拒绝)
}
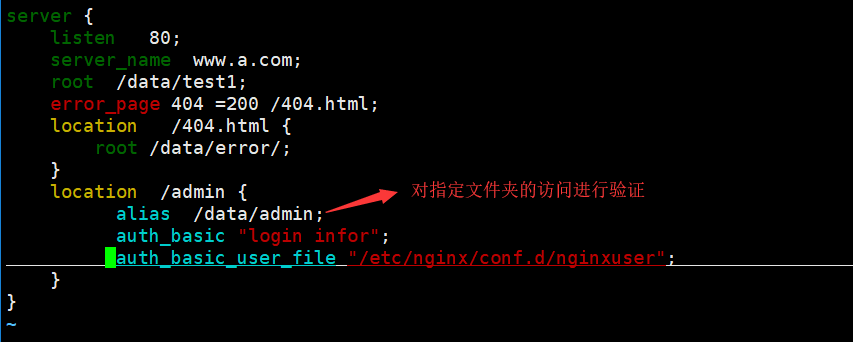
ngx_http_auth_basic_module (实现用户加密码访问)
cd /etc/nginx/conf.d/
htpasswd -cm nginxuser httpuer1(nginxuser:存放用户名及密码的文件;httpuer1:为创建的用户名)
(使用htppasswd命令需要安装httpd-tools包)
htpasswd -cm nginxuser httpuer2 (创建第二个用户账号及密码)
将生成的文件告诉配置文件路径:
此语句需要写在server{}语句块下。
ngx_http_stub_status_module (可以检查服务器的运行状态)
用于输出nginx的基本状态信息
要启用的话需要将以下代码写进去:
location /status {
stub_status;
allow 172.16.0.0/16; (允许那些主机可以看到本机的nginx的状态信息)
deny all; (剩余的全部都拒绝)
}
在客户端访问:http://192.168.60.66/status/ (就可以查看到访问的状态信息)
server accepts handled requests
1 1 1 (访问之后可以发现如上的描述:为服务器的接收了几个;处理了几个;请求的有几个)
accepts:统计总值,已经接受的客户端请求的总数
handled:统计总值,已经处理完成的客户端请求的总数
requests:统计总值,客户端发来的总的请求数
Reading:当前状态,正在读取客户端请求报文首部的连接的连接数
Writing:当前状态,正在向客户端发送响应报文过程中的连接数
Waiting:当前状态,正在等待客户端发出请求的空闲连接数
ngx_http_log_module (日志模块)
在主配置文件下的http语句块下写:
access_log off; (关掉日志记录默认是开启的)
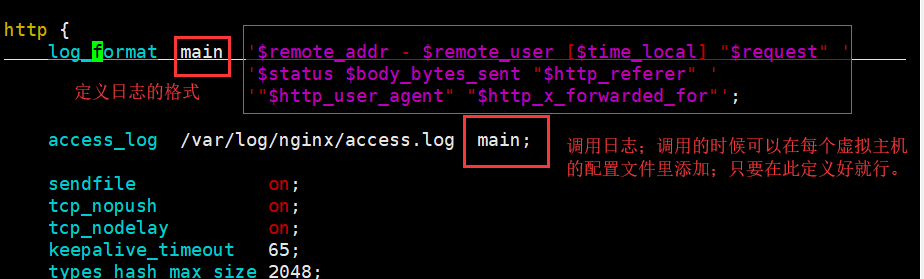
上图中的时间格式可以更改为[$time_iso8601](此模式下月份也会显示成数字而不是英文字母了)
上述定义的变量可以在官网上的变量上查询具体的使用方法及参数。
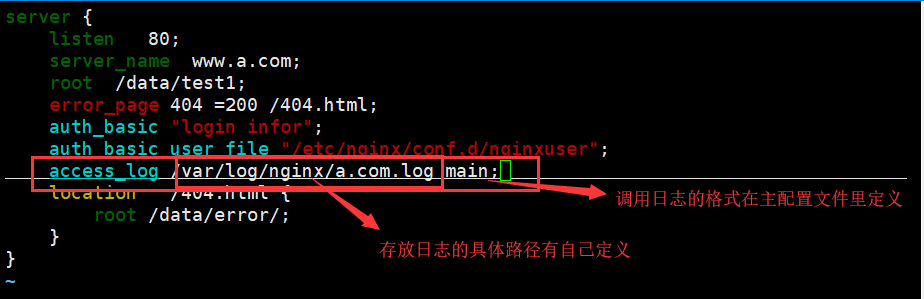
对每个虚拟主机配置日志格式:(日志文件会自动生成的)
ngx_http_gzip_module (压缩文件模块)
1、gzip on | off;
启用或禁用gzip压缩
2、gzip_comp_level level;
压缩比由低到高:1 到 9 默认:1
3、gzip_disable regex …;
匹配到客户端浏览器不执行压缩
4、gzip_min_length length;
启用压缩功能的响应报文大小阈值
5、gzip_http_version 1.0 | 1.1;
设定启用压缩功能时,协议的最小版本 默认:1.1
6、gzip_buffers number size;
支持实现压缩功能时缓冲区数量及每个缓存区的大小 默认:32 4k 或 16 8k
7、gzip_types mime-type …;
指明仅对哪些类型的资源执行压缩操作;即压缩过滤器 默认包含有text/html,不用显示指定,否则出错
8、gzip_vary on | off;
如果启用压缩,是否在响应报文首部插入“Vary: Accept-Encoding”
ngx_http_ssl_module (实现https的访问数据加密 )
1、ssl on | off; 为指定虚拟机启用HTTPS protocol, 建议用listen指令代替 (直接写成这样就可以了:listen 443 ssl; )
2、ssl_certificate file;
当前虚拟主机使用PEM格式的证书文件
3、ssl_certificate_key file;
当前虚拟主机上与其证书匹配的私钥文件
4、ssl_protocols [SSLv2] [SSLv3] [TLSv1] [TLSv1.1] [TLSv1.2];
支持ssl协议版本,默 认为后三个
5、ssl_session_cache off | none | [builtin[:size]] [shared:name:size];
none: 通知客户端支持ssl session cache,但实际不支持
builtin[:size]:使用OpenSSL内建缓存,为每worker进程私有
[shared:name:size]: 在多个worker进程之间共享一个缓存。(用的时候起个名并指定大小)
6、ssl_session_timeout time;
客户端连接可以复用ssl session cache中缓存的ssl参数的有效时长,默认5m (五分钟)
具体实现步骤:
1 .cd /etc/pki/tls/certs/ (进入此文件夹下生成自签名的证书文件)
make a.crt (输入口令3编;开始自签名了输入;国家;省;市;公司;组织;)
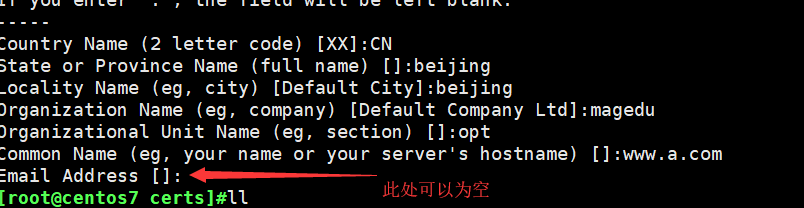
openssl rsa -in a.key -out aa.key (将生成的私钥文件解密生成新的文件aa.key)
cp aa.key a.crt /etc/nginx/conf.d/ (将刚生成的两个文件复制到nginx目录下)
mv aa.key a.key (改一下名称为了好看)
填写虚主机的配置文件:
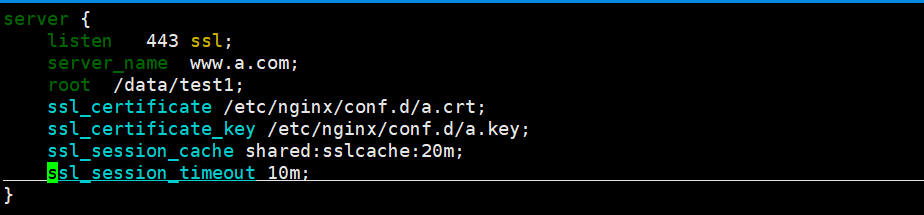
最后开始启动服务;会发现80和443端口应该开启了。
curl -k https://www.a.com (-k 忽略证书检查访问)
https://192.168.60.4/ (在浏览器上也可以访问了)
在实际工作中只需将申请下来的两个证书文件放到指定的路径下就可以了。
对多个虚拟主机的不同网站实现不同的https加密。只需要执行上述相同的步骤就可以了,在各自的配置文件里写上自己的证书文件路径就可以了。(在apache上是不可以实现两个加密的虚拟主机两个网站https)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号