关于Kafka __consumer_offests的讨论
众所周知,__consumer__offsets是一个内部topic,对用户而言是透明的,除了它的数据文件以及偶尔在日志中出现这两点之外,用户一般是感觉不到这个topic的。不过我们的确知道它保存的是Kafka新版本consumer的位移信息。本文我们简单梳理一下这个内部topic(以1.0.0代码为分析对象)
一、何时被创建?
首先,我们先来看下 它是何时被创建的?__consumer_offsets创建的时机有很多种,主要包括:
- broker响应FindCoordinatorRequest请求时
- broker响应MetadataRequest显式请求__consumer_offsets元数据时
其中以第一种最为常见,而第一种时机的表现形式可能有很多,比如用户启动了一个消费者组(下称consumer group)进行消费或调用kafka-consumer-groups --describe等
二、消息种类
__consumer_offsets中保存的记录是普通的Kafka消息,只是它的格式完全由Kafka来维护,用户不能干预。严格来说,__consumer_offsets中保存三类消息,分别是:
- Consumer group组元数据消息
- Consumer group位移消息
- Tombstone消息
2.1 Consumer group组元数据消息
我们都知道__consumer_offsets是保存位移的,但实际上每个消费者组的元数据信息也保存在这个topic。这些元数据包括:
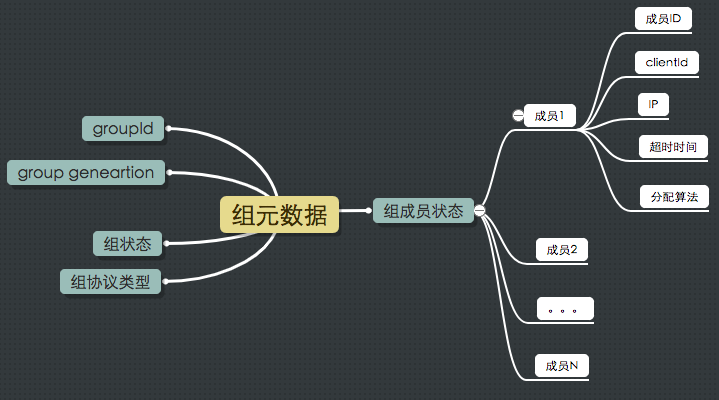
这里不详细展开组元数据各个字段的含义。我们只需要知道组元数据消息也是保存在__consumer_offsets中即可。值得一提的是, 如果用户使用standalone consumer(即consumer.assign(****)方法),那么就不会写入这类消息,毕竟我们使用的是独立的消费者,而没有使用消费者组。
这类消息的key是一个二元组,格式是【版本+groupId】,这里的版本表征这类消息的版本号,无实际用途;而value就是上图所有这些信息打包而成的字节数组。
2.2 Consumer group组位移提交消息
如果只允许说出__consumer_offsets的一个功能,那么我们就记住这个好了:__consumer_offsets保存consumer提交到Kafka的位移数据。这句话有两个要点:1. 只有当consumer group向Kafka提交位移时才会向__consumer_offsets写入这类消息。如果你的consumer压根就不提交位移,或者你将位移保存到了外部存储中(比如Apache Flink的检查点机制或老版本的Storm Kafka Spout),那么__consumer_offsets中就是无位移数据;2. 这句话中的consumer既包含consumer group也包含standalone consumer。也就是说,只要你向Kafka提交位移,不论使用哪种java consumer,它都是向__consumer_offsets写消息。
这类消息的key是一个三元组,格式是【groupId + topic + 分区号】,value则是要提交的位移信息,如下图所示:
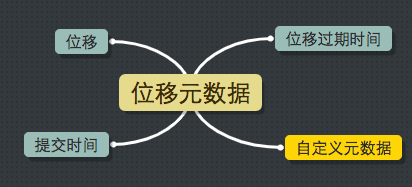
位移就是待提交的位移,提交时间是提交位移时的时间戳,而过期时间则是用户指定的过期时间。由于目前consumer代码在提交位移时并没有明确指定过期间隔,故broker端默认设置过期时间为提交时间+offsets.retention.minutes参数值,即提交1天之后自动过期。Kafka会定期扫描__consumer_offsets中的位移消息并删除掉那些过期的位移数据。
上图中还有个“自定义元数据”,实际上consumer允许用户在提交位移时指定一些特殊的自定义信息。我们不对此进行详细展开,因为java consumer根本就没有使用到它。相反地,Kafka Streams利用该字段来完成某些定制任务。
2.3 tombstone消息或Delete Mark消息
第三类消息成为tombstone消息或delete mark消息。这类消息只出现在源码中而不暴露给用户。它和第一类消息很像,key都是二元组【版本+groupId】,唯一的区别在于这类消息的消息体是null,即空消息体。何时写入这类消息?前面说过了,Kafka会定期扫描过期位移消息并删除之。一旦某个consumer group下已没有任何active成员且所有的位移数据都已被删除时,Kafka会将该group的状态置为Dead并向__consumer__offsets对应分区写入tombstone消息,表明要彻底删除这个group的信息。简单来说,这类消息就是用于彻底删除group信息的。
三、何时写入?
第一类消息是在组rebalance时写入的;第二类消息是在提交位移时写入的;第三类消息是在Kafka后台线程扫描并删除过期位移或者__consumer_offsets分区副本重分配时写入的。
四、消息留存策略
__consumer_offsets目前的留存策略是compact,__consumer_offsets会定期对消息内容进行compact操作——用户也可以同时启用两种留存策略来减少该topic所占的磁盘空间,不过要承担可能丢失位移数据的风险。
五、副本因子
__consumer_offest不受server.properties中num.partitions和default.replication.factor参数的制约。相反地,它的分区数和备份因子分别由offsets.topic.num.partitions和offsets.topic.replication.factor参数决定。这两个参数的默认值分别是50和1,表示该topic有50个分区,副本因子是1。鉴于位移和group元数据等信息都保存在该topic中,实际使用过程中很多用户都会将offsets.topic.replication.factor设置成大于1的数以增加可靠性,这是推荐的做法。不过在0.11.0.0之前,这个设置是有缺陷的:假设你设置了offsets.topic.replication.factor = 3,只要Kafka创建该topic时可用broker数<3,那么创建出来的__consumer_offsets的备份因子就是2。也就是说Kafka并没有尊重我们设置的offsets.topic.replication.factor参数。好在这个问题在0.11.0.0版本得到了解决,现在用户在使用时,一旦需要创建__consumer_offsets了Kafka一定会保证凑齐足量的broker才会开始创建,否则就抛出异常给用户。
日常使用中,另一个常见的问题是如何扩展该topic的副本因子。由于它依然是一个Kafka topic,因此我们可以调用bin/kafka-reassign-partitions.sh(bat)脚本来扩展replication factor。做法如下:
1. 构造一个json文件,如下所示,其中1,2,3表示3台broker的ID
{"version":1, "partitions":[
{"topic":"__consumer_offsets","partition":0,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":1,"replicas":[2,3,1]},
{"topic":"__consumer_offsets","partition":2,"replicas":[3,1,2]},
{"topic":"__consumer_offsets","partition":3,"replicas":[1,2,3]},
...
{"topic":"__consumer_offsets","partition":49,"replicas":[2,3,1]}
]}
2. 运行bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file reassign.json --execute
如果一切正常,你会发现__consumer_offsets的replication factor已然被扩展为3。
六、如何删除group信息
首先明确一点,Kafka是会删除consumer group信息的,既包括位移信息,也包括组元数据信息。对于位移信息而言,前面提到过每条位移消息都设置了过期时间。每个Kafka broker在后台会启动一个线程,定期(由offsets.retention.check.interval.ms确定,默认10分钟)扫描过期位移,并删除之。而对组元数据而言,删除它们的条件有两个:1. 这个group下不能存在active成员,即所有成员都已经退出了group;2. 这个group的所有位移信息都已经被删除了。当满足了这两个条件后,Kafka后台线程会删除group运输局信息。
好了, 我们总说删除,那么Kafka到底是怎么删除的呢——正是通过写入具有相同key的tombstone消息。我们举个例子,假设__consumer_offsets当前保存有一条位移消息,key是【testGroupid,test, 0】(三元组),value是待提交的位移信息。无论何时,只要我们向__consumer_offsets相同分区写入一条key=【testGroupid,test, 0】,value=null的消息,那么Kafka就会认为之前的那条位移信息是可以删除的了——即相当于我们向__consumer_offsets中插入了一个delete mark。
再次强调一下,向__consumer_offsets写入tombstone消息仅仅是标记它之前的具有相同key的消息是可以被删除的,但删除操作通常不会立即开始。真正的删除操作是由log cleaner的Cleaner线程来执行的。
鉴于目前水平有限,能想到的就这么多。有相关问题的读者可以将问题发动评论区,如果具有较大的共性,我会添加到本文的末尾~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号