【原创】Kakfa message包源代码分析
笔者最近在研究Kafka的message包代码,有了一些心得,特此记录一下。其实研究的目的从来都不是只是看源代码,更多地是想借这个机会思考几个问题:为什么是这么实现的?你自己实现方式是什么?比起人家的实现方式,你的方案有哪些优缺点?
任何消息引擎系统最重要的都是定义消息,使用什么数据结构来保存消息和消息队列?刚刚思考这个问题的时候,我自己尝试实现了一下Message的定义:
public class Message implements Serializable {
private CRC32 crc;
private short magic;
private boolean codecEnabled;
private short codecClassOrdinal;
private String key;
private String body;
}
可以看出,实现的方式是非常朴素和简单的,基本上就是由一个CRC32校验码、一个magic域、2个表明压缩类的字段以及两个表明消息的键值和消息本身的字符串组成。当与源代码中的实现方式做了比较时才发现自己的实现方式实在是too simple, sometimes naive了。在Java的内存模型中,对象保存的开销其实相当大,通常都要花费至少2倍以上的空间来保存数据(甚至更糟)。另外,随着堆数据越来越大,GC的性能下降得很多,将会变得非常缓慢。
在上面的实现中JMM会为字段进行重排以减少内存使用:
1 public class Message implements Serializable {
2 private short magic;
3 private short codecKlassOrdinal;
4 private boolean codecEnabled;
5 private CRC32 crc;
6 private String key;
7 private String body;
8 }
即使是这样,上面朴素的实现仍然需要40字节,而其中有7个字节只是为了补齐(padding)。Kafka实现的方式是使用nio.ByteBuffer来保存消息,同时依赖文件系统提供的页缓存机制,而不是依靠堆缓存。毕竟通常情况下,堆上保存的对象很有可能在os的页缓存中还保存一份,造成了资源的浪费。ByteBuffer是二进制的紧凑字节结构,而不是独立的对象,因此我们至少能够访问多一倍的可用内存。按照Kafka官网的说法,在一台32GB内存的机器上,Kafka几乎能用到28~30GB的物理内存同时还不比担心GC的糟糕性能。如果使用ByteBuffer来保存同样的消息,只需要24个字节,比起纯Java堆的实现减少了40%的空间占用,好处不言而喻。这种设计的好处还有加入了扩展的可能性。下图就是Kafka中Message的实现方式:
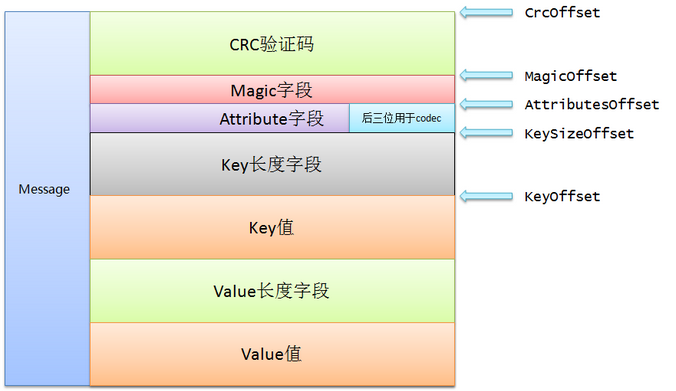
message包中的Message.scala中定义了Message,以伴生对象的方式实现了Message的定义。首先定义了object Message,里面有很多目前Message定义的常量。不过
基本思想就是为每个域提供2个字段:offset和长度,这样就可以很容易地定位该域中的任何一个字节处。
具体的域有: crc + magic + attribute + key + value,其中key + value 称为message overhead。虽然代码中起的名字都是offset,位移,但其实你可以理解为对应域在bytebuffer中的起始位移位置。由于个人是不太主张通篇把源代码贴上来的,毕竟大家都能下载到,所以这里就不全篇贴代码了。 值得注意的是,消息中的attributes字段。attributes用了一个字节来表示,总共有8位可以使用,目前使用了后三位作为codec类,其实从目前的代码来看,完全可以采用2位来表示是否启用压缩,目前3位的做法可能也是以后扩展方便。
0:无压缩
1:GZIP,也是默认的压缩方法
2:Snappy
3:LZ4
在定义了message的一些常量之后,一个Message class被创建,它的主构造器函数接收一个BufferByte作为对象,即将这段BufferByte缓冲区中的数据封装成一个Message对象,并提供了很多方法。比如:
computeCheckSum ——根据消息内容计算crc值
checksum——返回该消息头部的crc值
isValid——比较前两个方法中得到的crc值是否相同,
ensureValid——如果isValid不等的话报错
size——消息总的字节数
keySize/hasKey——消息中key的长度.如果长度>=0,即视为有key
payloadSizeOffset ---- value size保存的起始位移
isNull --- 判断payloadSize < 0
sliceDelimited——从给定位移处读取4个字节的内容并创建一个新的bytebuffer返回
equals——过Bytebuffer的equals方法比较Message包含的ByteBuffer
目前Message的定义支持压缩,attributes属性字节中的最后三位被用作表示codec。而目前Kafka支持的codec是由CompressionCodec和CompressionFactory两个scala文件定义的。CompressionCodec通过创建了sealed trait CompressionCodecde的方式,使得所有实现(因为trait类似于java中的接口,我们这里也就顺着接口实现的方式称之为实现)它的子类也必须在这个文件中。每个codec都有一个编号和一个名字。目前编号为0表示无压缩,支持的压缩格式有GZIP, Snappy和LZ4。
Kafka还提供了CompressionCodecFactory object提供工厂方法分别建立带压缩解压缩功能的输入流、输出流。值得注意的是在clients工程中org.apache.kafka.common.message包中提供了2个v1.4.1 LZ4 Frame format的部分实现: KafkaLZ4BlockInputStream和KafkaLZ4BlockOutputStream。由于压缩算法不在我们讨论的范围,故不做深入讨论。
okay!说完了Message.scala和两个codec支持类:CompressionFactory和CompressionCodec,我们再看看哪个文件还没说过

先找软柿子捏! InvalidMessageException和MessageLengthException就不说了,一个是crc校验码不匹配,一个是消息长度超过最大限度,不过貌似后者也没用上。另外,我们先跳过ByteBufferBackedInputStream和ByteBufferMessageSet这两个scala文件。先看MessageAndMetadata:这个case类是一个带泛型类:接收一个topic,分区号和原始的消息Message,位移信息,并提供了2个方法:key()和value():分别返回消息的key和value。其实笔者这里并没有弄明白为什么接收offset,而且貌似在代码中也没有用到。从调用这个类的方法给定的参数来看,这个offset应该是指某个分区log的位移。
MessageAndOffset就比较简单了,给定一个Message和位移。它提供了nextOffset方法,另外因为是case class,也提供了2个构造器参数的reader方法。
说完MessageAndOffset,我们就可以说说MessageSet了。这个包第二重要的(至少我是这么认为的)就是MessageSet了:MessageSet就是消息的集合,以抽象类的方式实现。这个集合保存的就是消息的字节形式,类似于字节容器的作用,可能在内存中也有可能在磁盘上。kafka代码中有不同的类继承这个类,分别实现了on-disk和in-memory. 注意的是集合中的对象并不单纯地是Message,而是offset field + message size field + Message field的组合。目前还没有弄明白为什么需要中间的那个字段值,毕竟message.size也能获得message的字节数,这样岂不是能节省4个字节? 也许后面能告诉我答案吧。这个抽象类提供了三个抽象方法供它的子类实现:
writeTo——将消息集合写入到指定的channel中,从offset开始写,最多不能超过maxSize
iterator——迭代器方法,用于遍历MessageSet
sizeInBytes——计算MessageSet中总的字节数
而ByteBufferMessageSet就比较复杂了,至少代码很长。从全局来看,实现还是伴生对象的方式,一个object,一个class。ByteBufferMessageSet class接收一个ByteBuffer,创建一个message set。有2种方式创建方式:一种是从bytebuffer中创建(消费者进程使用的这种模式);还有一种方式是给定一个消息列表以及相对应的序列化格式——消费者进程使用这种方式。另外还提供了3个辅助构造函数,都是调用了ByteBufferMessageSet object的create方法创建一个ByteBuffer传给ByteBufferMessageSet。其他方法包括:
sizeInBytes方法:返回这个消息集合总的字节数,包括那些不完整的尾部消息,这也是实现了抽象类MessageSet的方法
writeTo方法:将消息集合中的消息写入指定的channel,并返回写入的字节数,这也是实现了抽象类MessageSet的方法
internalIterator方法:其实实现的是父类MessageSet的iterator方法,返回消息集合的迭代器,用于遍历消息集合。该迭代器有个boolean类型的开关。如果设置为true,就是遍历第一级的消息,也就是说不考虑其元素是压缩过的消息集合的情况;如果是true,则外层遍历时候还需要解压压缩过的消息集合并执行内部遍历——即将包含消息集合的消息集合扁平化遍历
assignOffsets——更新位移信息。如果没有压缩情况,直接原地更新;如果存在压缩的情况,使用internalIterator方法重新拷贝一份新的ByteBufferMessageSet并指定了offset返回
总之,Kafka的message定义了消息和消息队列或消息集合的数据结构供其他的组件使用,在Kafka的其他核心组件的源代码中我们会陆续看到它的使用。

