【译】使用Kafka、DynamoDB和Rockset设计实时ETA预测系统
原文:https://dzone.com/articles/designing-a-real-time-eta-prediction-system-using
总有些奇怪的时刻,城市处于封锁状态,很少人敢于走出去冒险。此时像外卖这样的物流服务兴起就不足为怪了。
当用户下单后,大多数的此类应用都提供了准实时的订单送达时间(ETA)追踪功能。构建一个高伸缩性、分布式的实时ETA预测系统不是一件容易的事情,但如果我们能够简化这类系统的设计,是否情况会变得好一些呢?本文我们将对这类系统进行分解,将其拆解成几部分使得每一部分对应于一个独立的任务。
现在,我们看下构成这类系统的几大组件。
- 发送骑手app:安装到外卖员手机上的Android/iOS应用
- 用户app:安装在用户手机上的Android/iOS应用
- Rockset:支持任意模型和服务的查询引擎
- 消息队列:用于组件之间的数据传输。本文使用Kafka
- KV存储:用于保存订单和模型参数。本文使用DynamoDB
模型输入

骑手位置
为了获得准确的ETA估计,你要获取到外卖人员的位置,尤其是纬度和经度。这可以通过手机中的GPS轻松获取。调用设备GPS服务能够返回经纬度以及米级别的精确定位信息。你能够在应用中启动一个后台服务每10秒获取一次GPS坐标。这些坐标间隔太密了以至于无法用它们来预测ETA。为了增加GPS的精度,我们使用geohash算法来增加GPS精度。geohash是一个地址信息的标准化N字符哈希值。每个geohash表示了M平方英里的面积。N和M成反比例,所以N越大,M越小。若要了解geohash,请戳这里。
目前有很超多的库都支持将经纬度转换成geohash。这里我们使用一个github第三方库来获取geohash。待拿到geohash之后我们将它连同坐标信息写入到Kafka。Rockset会从Kafka读取对应的数据,并更新到一个名为locations的集合中。
订单
用户下的订单存储在DynamoDB中用于后续处理。一个订单通常有很多状态。所有状态都在DynamoDB中更新,连同保存一些额外的数据,比如源地址、目标地址、订单详情等。一旦订单被送达,到达的实际时间也要被保存在数据库中。Rockset也需要从DynamoD的订单表中读取这些更新数据,然后将它们更新到名为orders的集合中。
ML模型
指数平滑法
我们从订单表中能够获取到订单实际到达时间以及源地址和目标地址。我们将其称为TA。这样,我们可以将外卖员的最新位置作为源地址,用户地址作为目标地址,然后对所有这些TA统计平均值来计算大致的ETA。但是,这样做不一定很精确,因为它并未考虑到哪些变化的因素,比如该地区存在的新施工情况或者是到目标地址存在更短的新路线。
为此,我们需要一个简单,易于调试且具有良好准确性的预测模型。这就是引入指数平滑法的原因。一个指数平滑值的计算公式如下:
St = Alpha * Xt + (1 - Alpha) * St-1
其中,
St表示时刻t的平滑值
Xt表示时刻t的实际值
Alpha表示平滑因子
在我们的环境中,St表示ETA,Xt表示订单表源-目标地址对的最近实际到达时间。那么,
ETAt = Alpha * TAt + (1 - Alpha) * ETAt-1
Rockset
当前系统的服务层需要满足三个主要标准:
- 每分钟可处理数百万次写入的能力。每个外卖人员手机上的应用程序将会以每5-10秒发送一次GPS坐标的速率进行坐标推送,从而每次都会产生一个新的ETA。一个大规模食品外送企业可能有将近10万个外送人员。
- 这些数据获取的延时要最低。如果要有非常棒的用户交互体验,我们必须要能够在这些数据变更后及时地反映在用户应用。
- 能够实时处理schema的变更。未来我们可能需要保存额外的元数据,比如ETA预测准确度和模型版本等。我们可不想到时候再创建一个新的数据源只是为了应对增加新字段之用。
Rockset满足以上所有的这些要求。它具有:
- 动态伸缩能力:通过增加资源来实现处理更大容量数据的能力
- 分布式查询处理:多个计算节点并行查询以最小化延时
- 无schema抽取:实时支持schema的变更
Rockset提供了内置的Kafka连接器。我们使用这个连接器来提取外送人员的位置数据。
若要在Rockset中实现指数平滑法,我们创建两个查询Lambda。Rockset中的查询Lambda是具有名字的泛型化SQL,能够从一个专属的REST endpoint中被执行。
1. calculate_ETA:这个查询Labmda接收alpha,源地址和目标地址作为参数,返回一个指数平滑后的ETA。它运行的结果如下:
SELECT
(:alpha * SUM(term)) + (POW((1 - :alpha), MAX(idx))* MIN_BY(ta_i, time_i)) as ans
FROM
(
(
SELECT
order_id,
ta_i,
(ta_i * POW((1 - :alpha), (idx - 1))) AS term,
time_i,
idx
FROM
(
SELECT
order_id,
CAST(ta AS int) as ta_i,
time_i,
ROW_NUMBER() OVER(
ORDER BY
time_i DESC, order_id ASC
) AS idx
FROM
commons.orders_fixed
WHERE
source_geohash = :source
AND
destination_geohash = :destination
ORDER BY
time_i DESC, order_id ASC
) AS idx
) AS terms
)
2. calculate_speed:这个查询Lambda接收order_id作为参数,然后返回外送人员的平均运输速度。它执行以下的查询:
SELECT Sum(St_distance(prev_geo, geo) / ( ts - prev_ts )) / Count(*) AS speed
FROM (SELECT geo,
Lead(geo, 1)
OVER(
ORDER BY ts DESC ) AS prev_geo,
ts,
Lead(ts, 1)
OVER(
ORDER BY ts DESC ) AS prev_ts
FROM (SELECT St_geogpoint(Cast(lng AS DOUBLE), Cast(lat AS DOUBLE)) AS
geo,
order_id,
Cast(timestamp AS INT) AS
ts
FROM commons.locations
WHERE order_id = :order_id) AS ts) AS speed
预测ETA
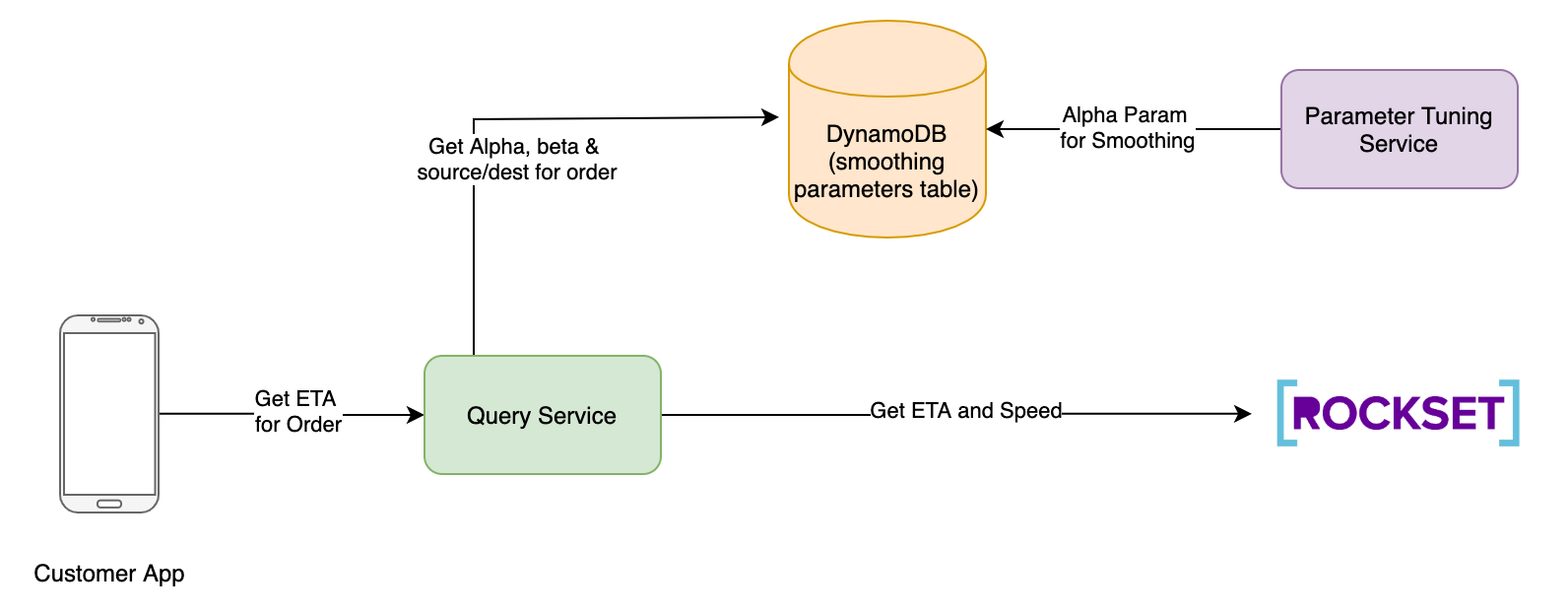
用户应用程序发起请求来预测ETA。它需要在API调用时传入订单号。这个请求被发送到查询服务那里。之后查询服务执行以下动作:
- 从DynamoDB获取最新的平滑因子Alpha和Beta。这里,Alpha是平滑参数,Beta是在计算最终ETA时分配给历史ETA的权重。有关更多详细信息,请参阅步骤6
- 获取订单ID的目标geohash。
- 从locations集合中获取骑手当前的geohash
- 使用前两步获取到的平滑因子alpha和骑手geohash数据触发calculate_ETA查询Lambda。我们把这个ETA称为历史ETA。
curl --request POST \
--url https://api.rs2.usw2.rockset.com/v1/orgs/self/ws/commons/lambdas/calculateETA/versions/f7d73fb5a786076c \
-H 'Authorization: YOUR ROCKSET API KEY' \
-H 'Content-Type: application/json' \
-d '{
"parameters": [
{
"name": "alpha",
"type": "float",
"value": "0.7"
},
{
"name": "destination",
"type": "string",
"value": "tdr38d"
},
{
"name": "source",
"type": "string",
"value": "tdr706"
}
]
}'
5. 使用当前订单号触发calulate_speed
curl --request POST \
--url https://api.rs2.usw2.rockset.com/v1/orgs/self/ws/commons/lambdas/calculate_speed/versions/cadaf89cba111c06 \
-H 'Authorization: YOUR ROCKSET API KEY' \
-H 'Content-Type: application/json' \
-d '{
"parameters": [
{
"name": "order_id",
"type": "string",
"value": "abc"
}
]
}
6. 最后,计算待预测的ETA,公式如下:
预测ETA = Beta * (历史ETA) + (1 - Beta) * 距离(骑手, 目的地)/速度
之后,将计算得出的ETA返回给用户手机的应用程序上。
反馈回路
ML模型需要不断训练以提升预测准确性。 在我们的场景中,我们有必要重新训练ML模型,以应对不断变化的天气情况,节日等问题。这是参数调整服务发挥作用的地方。
参数调整服务
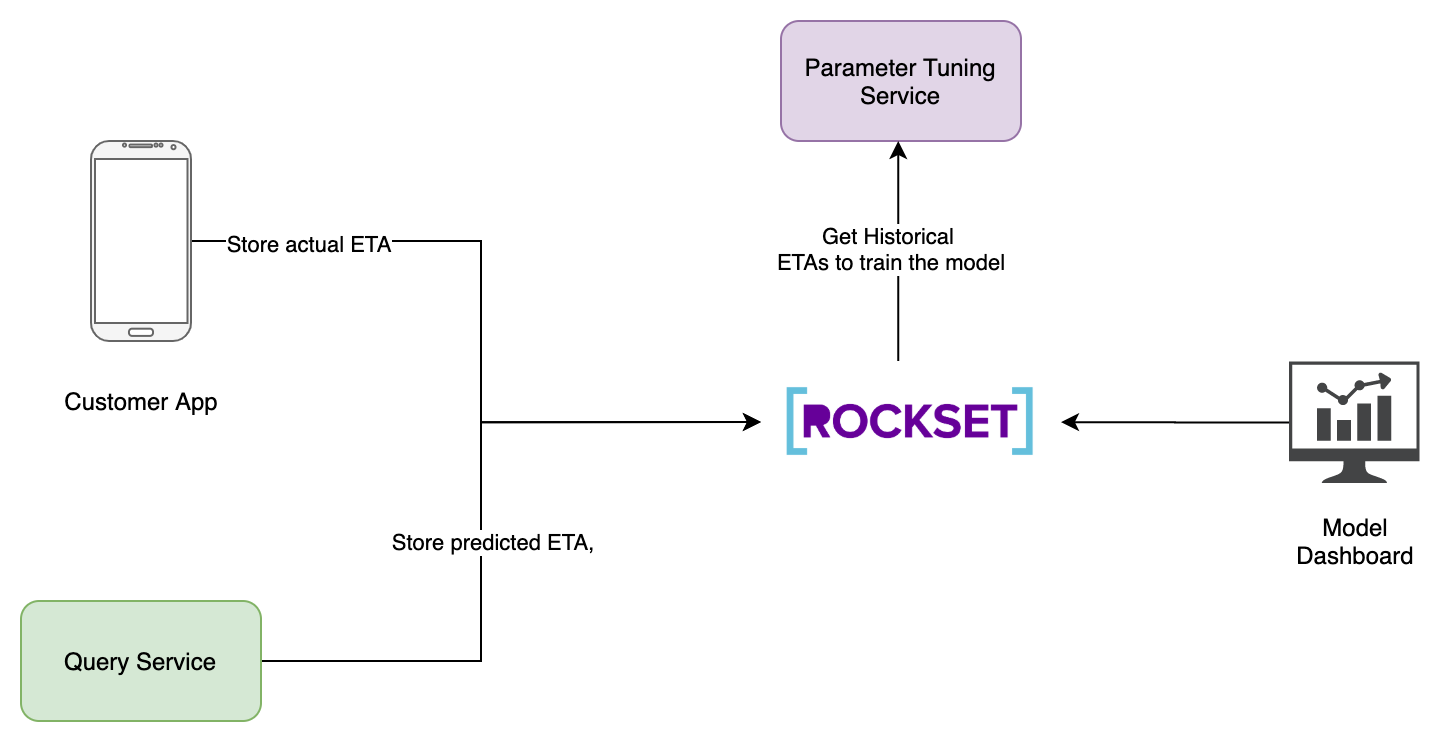
一旦计算出预测ETA,我们要把它与实际ETA放入到一个名为predictions的集合中。要在Rockset中保存这部分数据的主要目的是创建一个实时仪表盘能够监控模型准确度。这是确保用户在应用程序上不会看到荒谬离谱ETA的关键保证。
这些做完之后,下一个问题是如何确定平滑因子Alpha。为此,我们创建了一个参数调优服务,它就是一个Flink批处理任务。我们获取过去7~30天所有订单的所有历史ETA和TA数据,并利用它们的差值来计算Alpha和Beta。这可以使用诸如逻辑回归的模型来完成。
一旦计算出Alpha和Beta,它们就会存储在DynamoDB中名为smoothing_parameters的表中。查询服务从消费者应用程序接收请求时,将从该表中获取参数。
我们可以使用locations集合中的ETA数据每周训练一次参数调优模型。
总结
本文的架构旨在设计一个每分钟能够处理1百万请求切具有足够灵活性以支持动态扩展的应用程序。这个架构同时允许开发人员切换或插入组件,比如添加新的特性(天气因素)或添加一个过滤层来优化ETA的预测。这里,Rockset可以帮助我们解决三个首要的需求:
- 低延时复杂查询:Rockset允许我们仅仅使用API调用的方式执行复杂查询,比如指数平滑。这是通过查询Lambda来完成的。Lambda同时还支持参数以允许我们查询不同位置的参数。
- 实时、高伸缩性的数据抽取:如果平台上注册有10万个骑手且每个骑手手机上的应用程序每5秒发送一次GPS位置,那么每分钟就需要处理120万个请求。Rockset可以让我们在事件发生的几秒钟内查询到此数据。
- 多数据源:Rockset允许我们使用需要最少配置的完全托管的连接器从多个来源(例如Kafka和DynamoDB)提取数据。

