Apache Kafka是数据库吗?
最近思路有些枯竭,找些务虚的话题来凑。本文内容完全来自于Martin Kelppmann在2019年Kafka伦敦峰会上的演讲。顺便提一句,Kelppmann是《Designing Data-Intensive Applications》的作者。提起DDIA的大名想必各位应该是有所耳闻的。
Apache Kafka是数据库吗?你可能会觉得奇怪,Kafka怎么可能是数据库呢?它没有schema,也没有表,更没有索引。它仅仅是生产消息流、消费消息流而已。从这个角度来说Kafka的确不像数据库,至少不像我们熟知的关系型数据库。那么到底什么是数据库呢?或者说什么特性使得一个系统可以被称为数据库?经典的教科书是这么说的:数据库是提供 ACID 特性的,即atomicity、consistency、isolation和durability。好了,现在问题演变成了Apache Kafka支持ACID吗?如果它支持,Kafka又是怎么支持的呢?要回答这些问题,我们依次讨论下ACID。
1、持久性(durability)
我们先从最容易的持久性开始说起,因为持久性最容易理解。在80年代持久性指的是把数据写入到磁带中,这是一种很古老的存储设备,现在应该已经绝迹了。目前实现持久性更常见的做法是将数据写入到物理磁盘上,而这也只能实现单机的持久性。当演进到分布式系统时代后,持久性指的是将数据通过备份机制拷贝到多台机器的磁盘上。很多数据库厂商都有自己的分布式系统解决方案,如GreenPlum和Oracle RAC。它们都提供了这种多机备份的持久性。和它们类似,Apache Kafka天然也是支持这种持久性的,它提供的副本机制在实现原理上几乎和数据库厂商的方案是一样的。
2、原子性(atomicity)
数据库中的原子性和多线程领域内的原子性不是一回事。我们知道在Java中有AtomicInteger这样的类能够提供线程安全的整数操作服务,这里的atomicity关心的是在多个线程并发的情况下如何保证正确性的问题。而在数据库领域,原子性关心的是如何应对错误或异常情况,特别是对于事务的处理。如果服务发生故障,之前提交的事务要保证已经持久化,而当前运行的事务要终止(abort),它执行的所有操作都要回滚,最终的状态就好像该事务从未运行过那样。举个实际的例子,比如下面这张图:
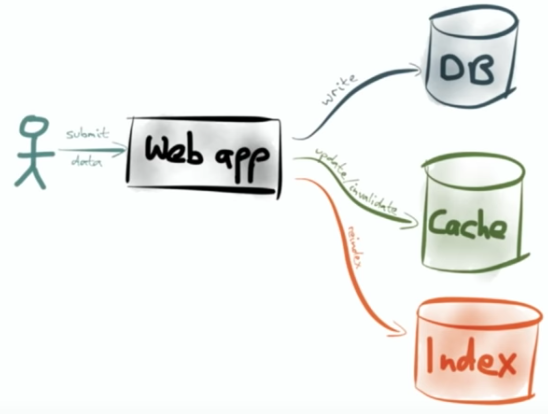
在异质分布式系统中一个比较经典的问题就是如何确保不同系统之间的数据同步。比如这个图中如何确保数据库、缓存和搜索索引之间的数据一致性就是一个关于原子性的问题:app写入数据库的写更新如何同步到cache和Index中,更关键的是如何确保这些写更新与之前写数据库是原子性的,要么它们全部写入成功,要么全部写入失败。我之前在知乎上也回答过一个类似的帖子,是关于“如何保持mysql和redis中数据一致性”的。令人意外地收获了近100个赞,感觉比我回答10个Kafka问题得到的赞还要多,这也足见这种一致性问题是多么地受欢迎。
显然,要实现这种分布式场景下的数据一致性并不容易。一个典型的异常场景就是当发生cache写入成功,而Index写入失败时,应用程序应该如何处理?如下图所示:

让app重试似乎是一个可行的选择,但重试的频率该怎么设定呢?更要命的是,如果因为网络的问题使得Index其实写入成功,但response返回失败,此时app重试有可能发生重复生产数据的问题,这还需要Index端有数据去重的能力。如果是撤销数据库和cache之前的写入呢? 如下图所示:
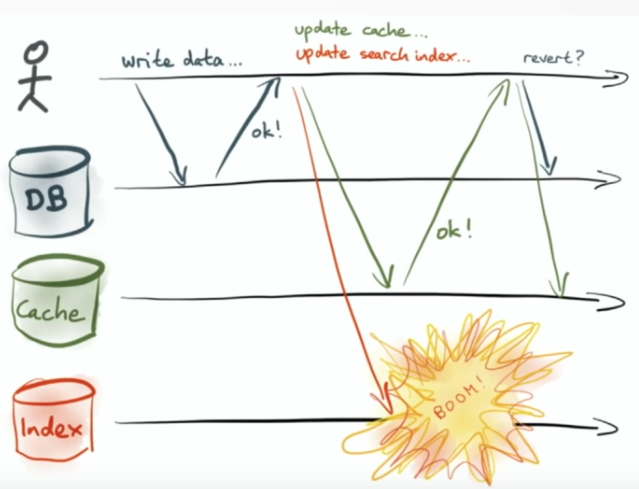
似乎这个方法也是可行的,但这就有了linearizability的问题了:即用户在某个时刻T看到了这个写入带来的新值,但在之后的某个时刻T1该值又变回了之前的老值,这必然造成用户的困扰,因此也不是一个好办法。
实际上,解决这个问题的常见做法是采用两阶段提交(2PC)这样分布式事务。不过2PC是出了名的慢,而且存在单点故障的隐患(coordinator),更重要的是它要求所有系统都要支持XA,但像Redis和ElasticSearch这样的系统本质上是不支持XA的,因此也就不能使用2PC来保证原子性。
第三个方法是采用基于日志结构的消息队列来实现,比如使用Kafka来做,如下图所示:

在这个架构中app仅仅是向Kafka写入消息,而下面的数据库、cache和index作为独立的consumer消费这个日志——Kafka分区的顺序性保证了app端更新操作的顺序性。如果某个consumer消费速度慢于其他consumer也没关系,毕竟消息依然在Kafka中保存着。总而言之,有了Kafka所有的异质系统都能以相同的顺序应用app端的更新操作,从而实现了数据的最终一致性。这种方法有个专属的名字,叫capture data change,也称CDC。
3、隔离性(isolation)
在传统的关系型数据库中最强的隔离级别通常是指serializability,国内一般翻译成可串行化或串行化。表达的思想就是连接数据库的每个客户端在执行各自的事务时数据库会给它们一个假象:仿佛每个客户端的事务都顺序执行的,即执行完一个事务之后再开始执行下一个事务。其实数据库端同时会处理多个事务,但serializability保证了它们就像单独执行一样。举个例子,在一个论坛系统中,每个新用户都需要注册一个唯一的用户名。一个简单的app实现逻辑大概是这样的:
1) 首先,发起SQL查询:select count(*) from user_accounts where username = 'jane',查看是否存在名为jane的用户;
2. 如果返回0, 则执行 insert into user_accounts(username, ...) values("janes", ...) 注册用户
显然存在某个特殊的时刻,使得两个新用户同时发现某个用户名可用,从而最终注册了相同的用户名,如下图所示:

这种就不是serializability级别的隔离,如果要实现这种唯一性,你就需要提高数据库的隔离级别到serializability。针对这个需求,我们可以使用Kafka来帮助实现吗?当然是可以的!如下图所示:

如果把用户名作为key,那么显然请求同一个用户名的用户必然访问Kafka主题的同一个分区上,此时根据Kafka分区消息写入前后顺序来确定谁先谁后就是一个自然的选择。数据库读取Kafka分区中的注册消息,发现红色标识的用户最先写入了key=jane的消息,那么当它再次读到key=jane的消息时就能明确拒绝绿色用户发起的请求,因为jane用户名已经被注册了。当然要实现这一整套的流程,你需要的不仅是Kafka,更要是一套相应的流处理管道,比如使用Kafka Streams。但无论如何,Kafka可以被用来实现这种事务的隔离性。依托Kafka的好处在于它不仅实现了serializability,而且依靠Kafka的分区机制,它能处理多个不同的用户名注册,因而也实现了scalability。
4、一致性(consistency)
最后说说一致性。按照Kelppmann大神的原话,这是一个很奇怪的属性:在所有ACID特性中,其他三项特性的确属于数据库层面需要实现或保证的,但只有一致性是由用户来保证的。严格来说,它不属于数据库的特性,而应该属于使用数据库的一种方式。坦率说第一次听到这句话时我本人还是有点震惊的,因为从没有往这个方面考虑过,但仔细想想还真是这么回事。比如刚才的注册用户名的例子中我们要求每个用户名是唯一的。这种一致性约束是由我们用户做出的,而不是数据库本身。数据库本身并不关心或并不知道用户名是否应该是唯一的。针对Kafka而言,这种一致性又意味着什么呢?Kelppmann没有具体展开,但我个人认为他应该指的是linearizability、消息顺序之间的一致性以及分布式事务。幸运的是,Kafka的备份机制实现了linearizability和total order broadcast,而且在Kafka 0.11开始也支持分布式事务了。
至此,我们说完了经典数据库中的ACID特性以及在Kafka中是如何支持它们的。现在你觉得Kafka是数据库了吗:) 这是个开放的问题,我们可以一起讨论下~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号