【计算机视觉】Objectness算法(一)---总体理解,整理及总结
1.源码下载及转换为VS2012 WIN32版本。
http://www.cnblogs.com/larch18/p/4560690.html
2.原文:
http://wenku.baidu.com/link?url=ls5vmcYnsUdC-ynKdBzWgxMX9WomZH2sDRvnQ634UlN8p7oJm_ATFWrLlTQ3H_Co3y-7fL8Jt0MbHu800RWJtSABPKRxrtZvkjkXiFzdLLG
3.原文翻译:
http://www.cnblogs.com/larch18/p/4569543.html
4.程序说明
5.总结:
能够在识别一个对象之前察觉它,非常接近自底向上的视觉显著性。根据显著性定义,广义的将相关领域的研究氛围三个类别:局部区域预测、显著性对象检测,对象状态建议。
局部区域检测: 该模型旨在预测人眼移动的显著点。启发于神经生物学研究早期的视觉系统,Itti等人提出了第一个用于显著性检测的计算模型,此模型利用了多尺度图像特征的中心-周围的差异。Ma和Zhang提出了另一种局部对比度分析方法来产生显著性图像,并用模糊增长模型对其进行扩展。Harel等人提出了归一化中心分布特征来突出显著部分。 尽管局部区域检测模型已经取得了卓越的发展,但其倾向于在边缘部分产生高显著性值,而不是均匀地突出整个对象,因此,这种方法不适合用于对象检测。
显著性对象检测: 该模型旨在检测当前视野中最引人注意的对象,然后分割提取整个部分。Liu等人通过在CRF框架中引入局部,区域的,全局显著性测量。Achanta等人提出了频率调谐方法。Cheng等人提出了基于全局对比度分析和迭代图分割的显著性对象检测。更多的最新研究也试着基于过滤框架产生一些高分辨的显著性图,采用一些效果比较好的数据,或者是使用分层结构。这些显著性对象分割在简单的情景图像分析、内容感知编辑中可以达到很好的效果。而且可以作为一个便宜的工具处理大规模的网络图像或者是通过自动筛选结果构建鲁棒性好的应用程序然而,这些方法很少能够运用于包含多对象的复杂图像,但现实生活中,这样的图片确实最有意义的。
对象状态建议: 该方法并不做决定,而是提供一定数量(例如:1000)包含所有类别对象的窗口。通过产生粗糙分割集,作为对象状态建议已经被证实为一个减少分类器搜索空间的有效方式,而且可以采用强分类器提高准确率。然后,这两种方法计算量大,平均一张图片需要2-7分钟。Alexe等提出了一个线索综合性的方法来达到更好、更有效的预测效果。Zhang等人采用方向梯度特征提出了一个级联的排序SVM方法。Uijlings等人提出了一个可选择性的搜索方法老获得更好的预测效果。作者提出了一个简单直观的方法,相对于其他方法,达到了更好的检测效果,而且快于其他流行的方法1000多倍。
另外,对于一个有效的滑动窗口对象检测方法,保证计算量可控是非常重要的。Lampert等人提出了一个优雅的分支定界方法用于检测。但是,这些方法只能用于加速分类器,而且是用户已经提供了一个好的边框。一些其他有效的分类器和近似核方法也已经被提出。这些方法旨在减小估计单个窗口的计算量,自然也能结合对象性建议进而减小损失。
对象状态通常表示一个图像窗口包含任意类别对象的概率值。一个通用类别的检测方法可以很方便的用于改善预处理过程:1)减少了搜索空间;2)通过使用强分类器来提高检测准确度.然而,设计一个好的通用类别的方法是非常困难的,需要:
-
具备很好的检测率,找到所有前景对象;
-
提出一些建议,用于减少对象检测的计算时间;
-
达到很高的计算效率,很容易拓展到其他实时以及大规模的应用程序中;
-
具备很好的通用性,方便用于各个类别的检测器中,这样可以减少计算量
暂时还没有任何方法可以同时满足以上全部要求。
认知心理学以及神经生物学研究表明,人拥有强大的能力感知对象。通过对认知反应时间和信号在生物途径中的传输速度进行深入的研究和推理,形成了人类注意力理论假定,该假定认为人类视觉系统只详细处理图像的某些局部,而对图像的其余部分几 乎视而不见,这也意味着,在识别对象之前,人类视觉系统中会有一些简单的机制来定位可能的对象。
基于以上的考虑,作者提出一个非常简单而且鲁棒性强的特征(BING),通过使用对象状态得分来协助检测对象。动机来自于对象普遍是独立的,而且都具有很好定义的封闭轮廓。观察到将图像归一化到一个相同的尺度(例如:8*8)上,一般对象的封闭轮廓和梯度范数之间具有强联系。为了能够有效量化图像窗口中对象状态,将其重置大小为8*8,组合该窗口的像素梯度的幅值作为为一个64位的特征,通过级联的支持向量机框架学习一个通用的对象检测方法。而且这个二值化赋范特性(BING),它可以很有效的用于一般对象估计。而且只需要一些CPU原子操作(例如加法,按位移动等)。大部分现存的先进方法,一般采用复杂的分类特征,而且需要采用加速方法以至于计算时间是可控的,相对于此,BING特征是简单朴素的。
作者在PASCAL VOC2007数据集上,广义的评价了这个算法。实验结果显示,方法很有效(在一个简单的桌面CPU中达到300fps)的产生了一系列数据驱动,类别独立,高分辨的对象窗口,通过使用1000个窗口(约为整个滑动窗口的0.2%),检测率达到96.2%。使用5000个建议窗口以及3个不同的颜色空间,可以达到99.5%。我们也核实了方法的通用性。我们训练了6个已知类别,然后在14个未知类别上进行测试,得到了很好的效果。相对于其他流行的方法,BING特征能够使我们达到更好的检测率,而且速率提高了1000多倍。实现了之前我们提到的关于一个好的检测器的要求。
6.算法流程图。
基本与算法无关的东西,这里不再赘述,下面开始边熟悉源码,边更新博客。
6.1、生成正样本
算法首先,对每张图像上,可能的所有标注框,采样生成不同尺度(该尺度在一定经验值范围内)的样本位置,并计算新生成的正样本与原始样本重叠率,保留重叠率超过50%的,重新归一化到8*8大小,计算新生成的有效正样本的梯度特征,并在水平方向翻转,最终保存新生成样本8*8的梯度特征与该特征的水平翻转特征作为xP.
6.2.负样本,固定100次随机产生100个备选的负样本窗口,筛选出与每张图片中,与所有目标的重叠率都小于50%的负样本窗,并将该窗口内保存图像作为负样本。
3.尺度处理,在筛选有效正样本时,同时保存了水平,垂直尺度系数,但是实际保存的尺度size是归一化映射后的值,即(h - min) * num + w - min + 1,其中h,w表示筛选出的有效正样本相对原始目标的垂直,水平尺度系数,实际上,还是保存的尺度系数,只是在数据结构上,采用哈希映射存储罢了。
6.4.判定有效样本,程序下一步,会在上面采样生成的所有有效正样本,进行直方图统计,统计出每个尺度下的样本数。例如有2500多个图像文件,计算所有正样本数,统计每个尺度下的正样本数。根据统计结果,剔除掉正样本数少于50的尺度。保存剩下的尺度统计结果,接着,对所有正负样本,统一分配到一个二维矩阵,垂直表示样本数,水平表示样本的8*8梯度特征值,直接保存。
以上,属于该算法的第一个亮点。
算法主要是用来加速传统的滑动窗口对象检测,通过训练通用的对象估计方法来产生候选对象窗口。作者观察到一般对象都会有定义完好的封闭轮廓,而且通过将相关图像窗口重置为固定大小,就可以通过梯度幅值进行区分。基于以上的观察以及复杂度的考虑,为了明确训练方法,将窗口固定为8*8的,并将梯度幅值转化为一个简单的64维的特征来描述这个窗口。这就相当于我们看路上走的人一样,在很远的地方即使我们没看清楚脸,只是看到一个轮廓也能识别出是不是我们认识的人,反而,如果脸贴着脸去看一个人可能会认不出来。
也就是作者发现,在固定窗口的大小下,物体与背景的梯度模式有所不同。如下图所示。图(a)中绿框代表背景,红框代表物体。如果把这些框都resize成固定大小,比如8X8,然后求出8X8这些块中每个点的梯度(Normed Gradient,简称NG特征,叫赋范梯度特征,就是计算梯度范数,即sqrt(gx^2 + gy^),实际就是该点的L2范数梯度,但是作者实现时,采用-1,0,1方式计算gx或者gy,因此,用|gx| + |gy|近似代替梯度的L2范数),可以明显看到物体与背景的梯度模式的差别,如图1(c)所示,物体的梯度分布呈现出较为杂乱的模式,而背景的较为单一和清楚。其实这个道理很浅显,就是图像中背景区域往往呈现出homogeneous的特性,早期的图像区域分割方法就是依靠这种特性来做的。然后我个人觉得这里不一定要用梯度,用其他一些统计特征甚至是图像特征都有可能得到类似的结果。
所以,作者首先将所有的标注样本,用不同尺度缩放采样,将采样出的有效正样本统一缩放到8*8,计算NG特征,也就是下面图中a生成c在过程。这样,通过SVM训练这些NG特征,得到目标和背景的第一次区分模型。
下面是原文的解释
对象一般是具有很好定义封闭轮廓和中心的。重置窗口的时候,就相当于将现实中的对象缩小到一个固定大小,因为在封闭的轮廓中,图像梯度变化很小,所以它是一个很好的可区分特征,就像是图1中,轮船和人在颜色,形状,纹理,光照等方面都有很大的不同,他们在梯度空间都存在共性。为了有效地利用观察结果,我们首先将输入图像重置为不同尺度的,在不同的尺度下计算梯度。然后再重置为取8*8大小的框,作为一个对应图像的64维的NG特征。
我们采用的NG特征,是一个密集的且紧凑的objectness特性,有以下几点优势:首先,由于归一化了支持域,所以无论对象窗口如何改变位置,尺度以及纵横比,它对应的NG特征基本不会改变。也就是说,NG特征是对于位置,尺度,纵横比是不敏感的,这一点是对于任意类别对象检测是很有用的。

图1 尽管对象(红色)和背景(绿色),在图像空间(a)呈现出了很大的不同,通过一个适当的尺度和纵横比,我们将其分别重置为固定大小(b),他们对应的NG特征(c)表现出很大的共性,基于NG特征,我们学习了一个简单的64D线性模型(d),用来筛选对象窗口。
这种不敏感的特性是一个好的对象检测方法应该具备的。第二,NG特征的紧凑性,使得计算和核实更加有效率,而且能够很好的应用在实时应用程序中。
NG特征的缺点就是识别能力不够。但一般而言,会采用检测器来最终缺点结果的误报率。
以上,上部分结束。
-----------------------------------------------------------------------------------------------------------------------
6.5.SVM第一级训练
首先,算法传递进入第一级SVM的样本总数,在超过SVM默认参数值时,采用SVM默认训练总样本数。用所有正样本以及剩下的数量采用随机从原负样本中抽取。即,负样本在这种情况下,不是全部参加SVM第一级训练。而是随机抽取一部分,保证总样本数达到SVM默认训练总样本数。
算法做一些SVM的初始化,涉及到样本标签Y,实际上,正样本默认都为有标签,以及SVM参数初始化等,这个后续另开文说明。这里不说介绍。
通过第一级SVM训练后,算法生成第一级SVM模型,转换成8*8,并归一化到1~255,保存。该模型w是用来下文中投票投票打分的,为第二级SVM学习做准备。
6.6 二值化模型参数w
首先通过上面的训练,我们可以得到分类的模型线性w,第一个要二值化的目标就是它,二值化的思想可以简单想象成找若干个基向量,并用这些基向量的线性组合来记表示w, 而且这些基向量的每一维只能取1或者-1(二值嘛)。那么假设我们用了Nw个基向量,每个基向量为aj, j = 1,...,Nw,那么就有。具体模型的二值化近似可以按如下算法1的步骤进行:
算法1的步骤也很明确,每一个都生成一个基向量,此基向量每一维都是由当前残差的符号决定,然后用当前残差减去残差在这基向量的投影(相当于去掉模型在这一维上的分量)。但在计算中因为二进制位只能为0或者1,所以为了处理方便,取,那么就可以将基向量表示为
。即基向量二进制与该二进制表示的补。
也就是说,αj表示基向量{-1,1},βj表示校准系数,同时,将每个基向量,映射到一个64位类型的数据中。
这里,实际上采用Gram-Schmidt正交化,只取了包含大部分信息的前Nw个正交向量作为输出,目的也是为了降低计算量。二值化的目的在于后期位运算,后面还会把NG特征也二值化。直接采用硬件指令大幅度地提升速度。
增加点自己的体会:
代码中,Nw取2,也就是SVM生成的W 是8*8矩阵,矩阵元素任意值,通过这个二值化过程,生成2个基向量,每个基向量完全覆盖了W中每个元素,但是此时在基向量中,每个元素对应的取值变成0或者1,因此,原w的64个元素,拼接成了一个64位的单个数据,即基向量。同时,对应该基向量的校准系数,算法为了后期加速,只近似处理高4位的数据,因此,校准系数只有保存4个,且都是一样的值,但是由于后期位移运算,这里就把校准值放置到了对应bit位。于是,2个基向量,生成8个校准系数,2个64位的数据。
6.7 打分窗口
为了找到图像中的一般对象,对每张训练图像(注意,这里是原图像,不是标注框),进行上文生成正样本时得到所有尺度的量化,扫描每个尺度定义好的量化窗口(依据尺度或者是纵横比,也就是说,这里只是对原图像依据之前胡尺度系数做缩放,不是缩放到8*8,因此,才有下文的I)。每一个窗口通过上文得到模型w获得得分
sl =<w,gl> (1)
l=(i,x,y) (2)
sl代表过滤器得分,gl表示NG特征,l表示坐标,i表示尺度,(x,y)表示窗口位置。其实就是一个滤波器,向量内积实现。也就是说,SVM第一级训练得到的w作为权值。该w作用于窗口(即NG特征,不是固定8*8大小),打分越高,就约接近目标。
下面引入w与二进制的内积运算公式:
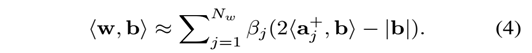 只需要按位与和字节统计操作.下面解释如何得到b.
只需要按位与和字节统计操作.下面解释如何得到b.
因此,为了实现(1)的快速计算,作者先用上面的算法,二值化了w,现在开始二值化NG,即gl参数,得到上面的b.
接下来我们还要对NG特征进行二值化,还记得我们刚才将NG归一化到[0,255]之间吧,那么8X8窗口上的每个点的NG特征值就可以用一个byte来存储,也就是每个值我们都可以用一个8位的二进制串来表示。那么我们就有一个8X8X8的三维矩阵,前两维是窗口位置(行,列),第三维是在二进制串中的位置(页)。举个例子,比如窗口中第1行,第2列的NG特征值是192,换成二进制就是1100 0000,那么矩阵的元素(1,2,1) = (1,2,2)= 1,(1,2,3),…,(1,2,8)= 0;那么我们一页一页地将矩阵元素取出来,再将每页8X8的矩阵元素排成一个64位的二进制串并存进一个int64里。既然思路已经有了,做法也就很简单了:对于每一页,将每一行每个元素取出来,不断加入int64中并左移1位,最后得到那个int64每一位对应的元素坐标排列就应该是(1,1)(1,2)(1,3)…(8,8)。然后作者在这里又玩了一个trick,他说你这样每次移动一位不是要循环64次嘛,如果先将8个拼成一组(就是刚才那样左移1次),那么只需要移动8组就好了啊!而且,这样在相邻的窗口中还能重用重叠的部分(在VS2010
的Debug模式下我试了下,1个数“每次左移1位,移动1万次”和“每次左移100位,移动100次”两种情况,的确是后者速度快)。
最后,为了进一步节省存储空间,还可以只取NG值的高位来作二值化。因为比如192和193、194,它们的二进制表达分别是1100 0000, 1100 0001和 1100 0010,要是我只看前面4位,后面4位忽略(取0)的话,那么它们的取值都是192。也就是我们可以用192来约等于193和194,这样我们就不需要用到8位那么多了!写成公式就是下面的式(2)这样,其中Ng 是我们要用的高位的位数(也就是前面说的三维矩阵的页),bk,l就是对应三维矩阵中的第k页(二值)。
最后将二值化模型w和二值化NG,结合起来对窗口打分的操作由卷积运算变成了大部分是位运算操作,
其中C_j,k是
上面的计算很容易通过位运算和SSE指令(支持8x8=64bit)来完成快速运算。
然后,运用非最大抑制(NMS),做下滤波。
这里,写的比较杂,再次总结一下,
首先,根据第一级SVM得到模型参数w,对每张训练图像,进行所有尺度变换(不是固定8*8大小),然后计算NG特征,接着根据上文的打分系统,计算每个尺度下的sl(实际上,二值化w和二值化NG特征,就是BING特征).并重新排序,利用NMS消除掉高分点附近领域内的打分值。且,这里只选择指定阈值以上的高分点。然后,在原始图像,找到对应打分点对应的方框大小,并保存。这样,针对每张图像,我们计算了不同尺度i下的打分项以及相对应的可能目标匡。然后,针对所有可能的目标匡,我们将其与原始图像中所有有效正样本做重叠率比对,只要有一个正样本框与该可能目标匡重叠与大于0.5,则该可能目标匡作为正样本,否则为负样本。在传入第二级SVM时,作者将可能目标框的打分值,重新根据尺度整合,即不同尺度下下,所有的打分值,作为正负样本。在第二级训练时,针对每个尺度,训练一次。
6.8第二级SVM训练
作者针对每种尺度下的打分值,训练SVM,每种尺度下样本总数不超过10W。超过,则随机在正负样本中抽取。确保先读取正样本,后需剩余的位置随即用负样本填满。训练结束后,生成新的权值vi,ti.
以上,训练程序结束,下面进入测试部分。
--------------------------------------------------------------------------------
测试程序,在读入测试图片后,计算图像的BING特征,跟二级SVM训练预处理一样,对图像进行不同尺度的缩放,计算NG,打分统计得到sl(用的还是第一级模型的w)
然后,为每个尺度提供一些建议窗口。相对于其他窗口(例如:100*100),一些尺度(例如:10*500)的窗口包含对象的可能性是很小的。因此我们定义对象状态得分(校准过滤器得分):ol = vi*sl+ti (3)针对不同尺度i的窗口,得到不同的独立学习系数。使用校准函数(3)是非常快的,通常只需要在最终的建议窗口重排。
这里,打分用的权值是二级模型训练出的,即上文的vi,ti.得到ol重新排序。整个过程,计算时间,给出每个检测图象的平均测试时间。并保存打分结果与对应的目标框。
打分越高,越接近目标。实际上,算法生成的就是打分窗口,也就是所为的对象状态。下面测试的时候,根据打分窗口与标注的测试窗口重叠率大于0.5就认为检测到了。
接着,作者开始绘制结果,根据检测出的候选框与每个测试标注框计算重叠率,大于0.5,就认为检测到了(1),否则score为0未检到。之后,计算平均重叠率和平均检测率.如下图:

这里解释下重叠率:
DRandMABO
上面的精度曲线称为DR-#WIN curves,源自TPAMI 2012的一篇论文:Measuring the objectness of image windows。原文还提出了将窗口数量比如[[0,5000]归一化到[0,1]之间,用曲线下的面积作为目标检测的度量结果,并称之为the area under the curve(AUC),这样AUC的范围就在[0,1]之间了。
检测精度DR的计算
DR的计算是参考The PASCAL Visual Object Classes (VOC) Challenge,目标检测任务中DR的计算的是true/false positive精度,将算法检测目标结果放到groud truth中,将“预测目标区域与groud truth区域的交集”除以“预测目标区域与groud truth区域的并集”作为DR:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号