【机器学习】半监督学习
无监督学习只利用未标记的样本集,而监督学习则只利用标记的样本集进行学习。
但在很多实际问题中,只有少量的带有标记的数据,因为对数据进行标记的代价有时很高,比如在生物学中,对某种蛋白质的结构分析或者功能鉴定,可能会花上生物学家很多年的工作,而大量的未标记的数据却很容易得到。
这就促使能同时利用标记样本和未标记样本的半监督学习技术迅速发展起来。
半监督学习理论简述:
半监督学习有两个样本集,一个有标记,一个没有标记.分别记作
Lable={(xi,yi)},Unlabled={(xi)}.并且数量上,L<<U.
1. 单独使用有标记样本,我们能够生成有监督分类算法
2. 单独使用无标记样本,我们能够生成无监督聚类算法
3. 两者都使用,我们希望在1中加入无标记样本,增强有监督分类的效果;同样的,我们希望在2中加入有标记样本,增强无监督聚类的效果.
一般而言,半监督学习侧重于在有监督的分类算法中加入无标记样本来实现半监督分类.也就是在1中加入无标记样本,增强分类效果.
半监督学习的动力,motivation
某人讨论的时候,总是教导我们的词,motivation.一下午四五遍地强调写论文要有motivation.下面说说半监督学习的motivation.
1. 有标记样本难以获取.
需要专门的人员,特别的设备,额外的开销等等.
2. 无标记的样本相对而言是很廉价的.
3. 还有一点就是机器学习的光辉前景.
半监督学习与直推式学习的区别:
这个网上也有论述.主要就是半监督学习是归纳式的,生成的模型可用做更广泛的样本;而直推式学习仅仅为了当前无标记样本的分类.
简单的说,前者使用无标记样本,为了以后其他样本更好的分类.
后者只是为了分类好这些有限的无标记样本.
下面几个图来生动形象地诠释半监督的好处:
上图中,只有两个标记样本,X,O,剩下绿点是无标记的样本.通过无标记样本的加入,原来的分类界限从0移到了0.5处,更好地拟合了样本的现实分布.
半监督学习算法分类:
1. self-training(自训练算法)
2. generative models生成模型
3. SVMs半监督支持向量机
4. graph-basedmethods图论方法
5. multiview learing多视角算法
6. 其他方法
接着简单介绍上述的几个算法
self-training算法:
还是两个样本集合:Labled={(xi,yi)};Unlabled= {xj}.
执行如下算法
Repeat:
1. 用L生成分类策略F;
2. 用F分类U,计算误差
3. 选取U的子集u,即误差小的,加入标记.L=L+u;
重复上述步骤,直到U为空集.
上面的算法中,L通过不断在U中,选择表现良好的样本加入,并且不断更新子集的算法F,最后得到一个最有的F.
Self-training的一个具体实例:最近邻算法
记d(x1,x2)为两个样本的欧式距离,执行如下算法:
Repeat:
1. 用L生成分类策略F;
2. 选择x = argmin d(x, x0). 其中x∈U,min x0∈L.也就是选择离标记样本最近的无标记样本.
2. 用F给x定一个类别F(x).
3. 把(x,F(x))加入L中
重复上述步骤,直到U为空集.
上面算法中,也就是定义了self-training的”误差最小”,也就是用欧式距离来定义”表现最好的无标记样本”,再用F给个标记,加入L中,并且也动态更新F.
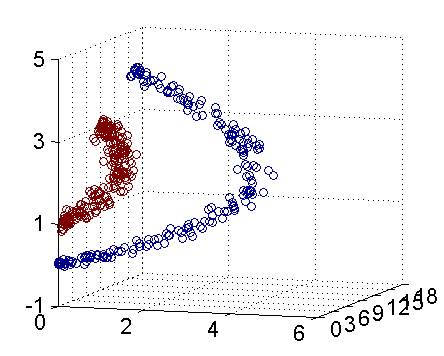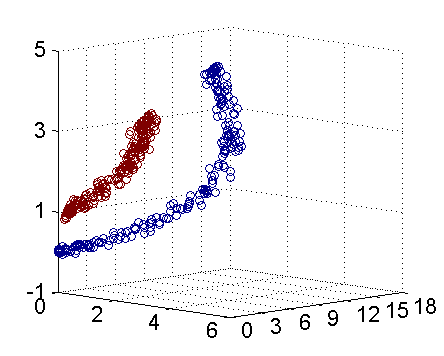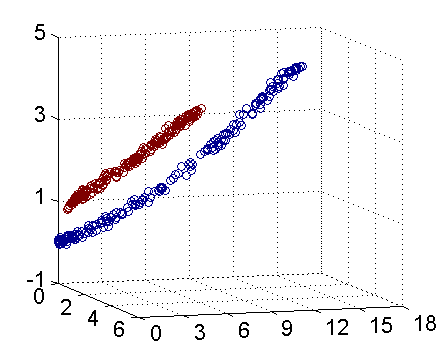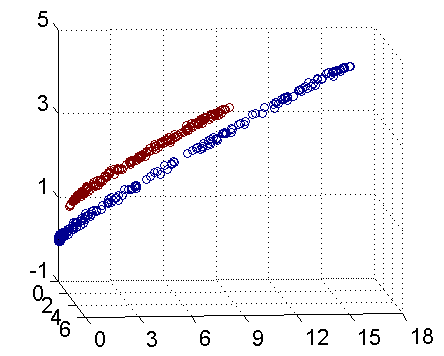
下面是这种算法的效果图:
上图从两个点出发,不断加入最近邻点,不断更新F.
上面的算法表现良好,当然更多的是表现不好.如下:
生成模型
生成算法来源于假设,比如我们假设原样本满足高斯分布,然后用最大释然的概率思想来拟合一个高斯分布,也就是常用的高斯混合模型(GMM).
简单介绍下高斯混合模型:
假设如下的样本分布:
我们假设他们满足高斯分布.
高斯分布的参数有: θ = {w1, w2, µ1, µ2, Σ1, Σ2}
利用最大释然的思想,最大化如下概率:
p(x, y|θ) = p(y|θ)p(x|y, θ).
得到如下的假设分布:
顺便贴一个介绍高斯混合模型日志:
http://blog.csdn.net/zouxy09/article/details/8537620
接着是我们的半监督生成算法:
样本分布如下:
算法过后,得到如下分布:
对比这两个图,说明下高斯混合模型与半监督生成模型的区别:
这两种方法的释然函数不同,前者最大化标记样本出现概率,后者加入了无标记样本出现概率.
算法的具体实现,请参见E-M算法.
这样生成的算法也有许多不良表现,如下:
假设原始的分布式这样的:
通过GMM,它变成了这样:
几个需要注意的地方:
1. 高斯混合的局部收敛性
2. 减少无标记样本的权值
半监督SVM,图算法模型,流行模型等.
SVM的理论不再赘述,就是一个最优超平面:
偷一张很牛逼的SVM图:
这些内容涵盖比较广泛,一篇日志装不下.有兴趣地可以进一步了解.
最后是小结
上两张图:
基于生成式模型的半监督学习方法
该类方法通常是把未标记样本属于每个类别的概率看成一组缺失参数,然后采用EM (expectation-maximization) 算法对生成式模型的参数进行极大似然估计。不同方法的区别在于选择了不同的生成式模型作为基分类器,例如混合高斯(mixture of Gaussians)[3]、混合专家 (mixture of experts)[1]、朴素贝叶斯(na ve Bayes)[4]。虽然基于生成式模型的半监督学习方法简单、直观,并且在训练样本,特别是有标记样本极少时能够取得比判别式模型更好的性能,但是当模型假设与数据分布不一致时,使用大量的未标记数据来估计模型参数反而会降低学得模型的泛化能力[5]。由于寻找合适的生成式模型来为数据建模需要大量领域知识,这使得基于生成式模型的半监督学习在实际问题中的应用有限。
基于低密度划分的半监督学习方法
该类方法要求决策边界尽量通过数据较为稀疏区域,以免把聚类中稠密的数据点分到决策边界两侧。基于该思想,Joachims[6]提出了TSVM算法(如图2所示,其中实线为TSVM的分类边界、虚线为不考虑未标记数据的SVM分类边界)。在训练过程中,TSVM算法首先利用有标记的数据训练一个SVM并估计未标记数据的标记,然后基于最大化间隔准则,迭代式地交换分类边界两侧样本的标记,使得间隔最大化,并以此更新当前预测模型,从而实现在尽量正确分类有标记数据的同时,将决策边界“推”向数据分布相对稀疏的区域。然而,TSVM的损失函数非凸,学习过程会因此陷入局部极小点,从而影响泛化能力。为此,多种TSVM的变体方法被提出,以缓解非凸损失函数对优化过程造成的影响,典型方法包括确定性退火[7]、CCCP直接优化[8]等。此外,低密度划分思想还被用于TSVM以外的半监督学习方法的设计,例如通过使用熵对半监督学习进行正则化,迫使学习到的分类边界避开数据稠密区域[9]。
")
图 2 TSVM算法示意图[6]
基于图的半监督学习方法
该类方法利用有标记和未标记数据构建数据图,并且基于图上的邻接关系将标记从有标记的数据点向未标记数据点传播(如图3所示,其中浅灰色和黑色结点分别为不同类别的有标记样本、空心结点为未标记样本)。根据标记传播方式可将基于图的半监督学习方法分为两大类,一类方法通过定义满足某种性质的标记传播方式来实现显式标记传播,例如基于高斯随机场与谐函数的标记传播[10]、基于全局和局部一致性的标记传播[11]等;另一类方法则是通过定义在图上的正则化项实现隐式标记传播,例如通过定义流形正则化项,强制预测函数对图中的近邻给出相似输出,从而将标记从有标记样本隐式地传播至未标记样本[12]。事实上,标记传播方法对学习性能的影响远比不上数据图构建方法对学习性能的影响大。如果数据图的性质与数据内在规律相背离,无论采用何种标记传播方法,都难以获得满意的学习结果。然而,要构建反映数据内在关系的数据图,往往需要依赖大量领域知识。所幸,在某些情况下,仍可根据数据性质进行处理,以获得鲁棒性更高的数据图,例如当数据图不满足度量性时,可以根据图谱将非度量图分解成多个度量图,分别进行标记传播,从而可克服非度量图对标记传播造成的负面影响[13]。基于图的半监督学习方法有良好的数学基础,但是,由于学习算法的时间复杂度大都为O(n3) ,故难以满足对大规模未标记数据进行半监督学习的应用需求。
")
图 3 标记传播示意图
协同训练(co-training)的半监督算法
他们假设数据集有两个充分冗余(sufficient and redundant)的视图(view),即两个满足下述条件的属性集:第一,每个属性集都足以描述该问题,也就是说,如果训练例足够,在每个属性集上都足以学得一个强学习器;第二,在给定标记时,每个属性集都条件独立于另一个属性集。,然后,在协同训练过程中,每个分类器从未标记示例中挑选出若干标记置信度(即对示例赋予正确标记的置信度)较高的示例进行标记,并把标记后的示例加入另一个分类器的有标记训练集中,以便对方利用这些新标记的示例进行更新。协同训练过程不断迭代进行,直到达到某个停止条件。
此类算法隐含地利用了聚类假设或流形假设,它们使用两个或多个学习器,在学习过程中,这些学习器挑选若干个置信度高的未标记示例进行相互标记,从而使得模型得以更新。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号