00 | 为什么下一个开源项目可能仅是一个接口
We are likely to see more open interfaces and metaframeworks emerge, but they have their drawbacks.
我们也许会看到更多开放接口和原框架出现,但是他们都有各自的缺点。
What do deep learning, serverless functions, and stream processing all have in common? Outside of being big trends in computing, the open source projects backing these movements are being built in a new, and perhaps unique, way. In each domain, an API-only open source interface has emerged that must be used alongside one of many supported separate back ends. The pattern may be a boon to the industry by promising less rewrite, easy adoption, performance improvements, and profitable companies. I’ll describe this pattern, offer first-hand accounts of how it emerged, discuss what it means for open source, and explore how we should nurture it.
深度学习,无服务器功能和流处理有什么共同之处呢?它们除了成为计算领域大趋势之外,支持它们的开源项目也正以一种新的或者是独特的方式被构建。在每一个领域,当一个仅支持API方式的开源接口出现,它就必须伴随着众多受支持的独立后端之一进行使用。这种模式可能会给行业带来好处,因为其承诺较少的重写,易采用,提升性能和公司盈利。我将描述一下这种模式,提供它是怎样出现的第一手资料,讨论它对于开源有怎样的意义,并探索我们该如何去培育它。
Typically, a new open source project provides both a new execution technology and an API that users program against. API definition is, in part, a creative activity, which has historically drawn on analogies (like Storm’s spouts and bolts or Kubernetes’ pods) to help users quickly understand how to wield the new thing. The API is specific to a project’s execution engine; together they make a single stand-alone whole. Users read the project’s documentation to install the software, interact with the interface, and benefit from the execution engine.
通常,一个新的开源项目既提供了一种新的执行技术,也提供了用户编程时所使用的API。API的定义在某种程度上是一个创造性活动,它在历史中借鉴了类似的概念(像Storm的spouts,bolts和Kubernetes的pods)去帮助用户快速的理解怎样去使用新的事物。对于一个项目执行引擎,API是特定的;它们一起就构成了一个单独的整体。用户阅读项目的文档去安装软件,与接口进行交互,并从执行引擎中获利。 [这里的against不知该怎么翻译呢?]
Several important new projects are structured differently. They don’t have an execution engine; instead, they are metaframeworks that provide a common interface to several different execution engines. Keras, the second-most popular deep learning framework, is an example of this trend. As creator François Chollet recently tried to explain, “Keras is meant as an interface rather than as an end-to-end framework.” Similarly, Apache Beam, a large-scale data processing framework, is a self-described “programming model.” What does this mean? What can you do with a programing model on its own? Nothing really. Both of these projects require external back ends. In the case of Beam, users write pipelines that can execute on eight different “runners,” including six open source systems (five from Apache), and three proprietary vender systems. Similarly, Keras touts support for TensorFlow, Microsoft’s Cognitive Toolkit (CNTK), Theano, Apache MxNet, and others. Chollet provides a succinct description of this approach in a recent exchange on GitHub: “In fact, we will even expand the multi-back-end aspect of Keras in the future. ... Keras is a front end for deep learning, not a front end for TensorFlow.”
有些重要的新项目结构是不同的。它们没有执行引擎,取而代之的是元框架,元框架为一些不同的执行引擎提供了一个通用的接口。Keras ,第二大流行的深度学习框架,就是这种趋势的一个例子。正如其创建者 François Chollet 最近试图解释的那样,“Keras是一个接口而非端到端的框架。” 与此类似的是,Apache Beam,一个大规模的数据处理框架,自我描述为“编程模型”。这是什么意思呢?你能用它自身的编程模型做什么呢?事实上并不能做些什么。所有这些项目,都必须要求有一个外部的后端。Apache Beam,用户编写的管道可以在8个不同的运行器上执行,包括6个开源系统(5个来自Apache)和3个专有的供应商系统。类似的,Keras 也支持 TensorFlow、微软认知工具包(Microsoft’s Cognitive Toolkit,CNTK)、Theano、Apache MxNet 等。Chollet 在 GitHub 最近的一次交流中简要描述了这种方法:“事实上,我们将来甚至会扩展 Keras 的多后端的方面。…Keras 是深度学习的前端,而不是 TensorFlow 的前端。”
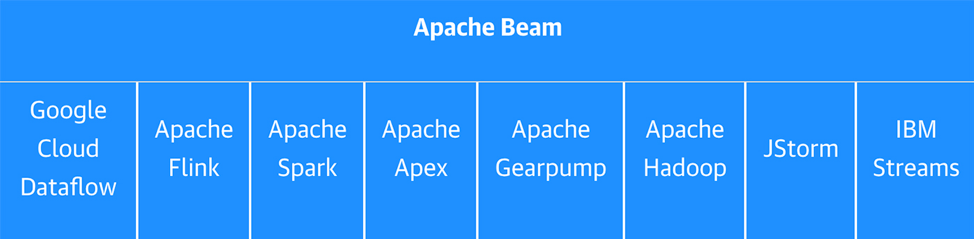

The similarities don’t end there. Both Beam and Keras were originally created by Googlers at the same time (2015) and in related fields (data processing and machine learning). Yet, it appears the two groups arrived at this model independently. How did this happen, and what does that mean for this model?
相似之处不止于此。Beam 和 Keras 最初都是由 Google 员工在同一时间(2015 年)以及相关领域(数据处理和机器学习)创建的。然而,看上去这两个小组都独立地得到了这个模型。这究竟是怎么发生的?这对于这个模型意味着什么呢?
The Beam story
Beam 的故事
In 2015, I was a product manager at Google, focused on Cloud Dataflow. The Dataflow engineering team’s legendary status dates back to Jeff Dean’s and Sanjay Ghemawat’s famous MapReduce paper in 2004. Like most projects, MapReduce defined a method of execution and a programming model to take advantage of it. While the execution model is still state of the art for batch processing, the programming model was not pleasant to work with, so Google soon developed a much easier, abstracted programming model called Flume (step 1, Figure 1). Meanwhile, demand for lower latency processing resulted in a new project, with the usual execution model and programming model, called MillWheel (step 2). Interestingly, these teams came together around the idea that Flume, the abstracted programming model for batch, with some extensions, could also be a programming model for streaming (step 3). This key insight is at the heart of the Beam programming model, which at the time was called The Dataflow Model.
2015 年,当时我还是Google的PM,专注于云数据流。数据流工程团队的传奇地位可以追溯到Jeff Dean和Sanjay Ghemawat于2004年发表的著名的MapReduce论文。像大多数项目一样,MapReduce定义了一种执行方式和编程模型去利用它。虽然执行模型对于批处理而言仍然是最先进的,但使用编程模型却并不那么令人愉快,因此Google很快开发了一个更简单的抽象编程模型—Flume(图一第一步)。同时,对较低延迟处理的需求导致了一个新的项目,该项目使用常见的执行模型和编程模型,这个项目就是MillWheel(第二步)。有趣的是,这些团队围绕着一个想法走到了一起,Flume,这个用于批处理的抽象编程模型,带有一些扩展,也能成为流的编程模型(第三步)。这个关键的见解是Beam编程模型的核心,在当时被称为数据流模型。
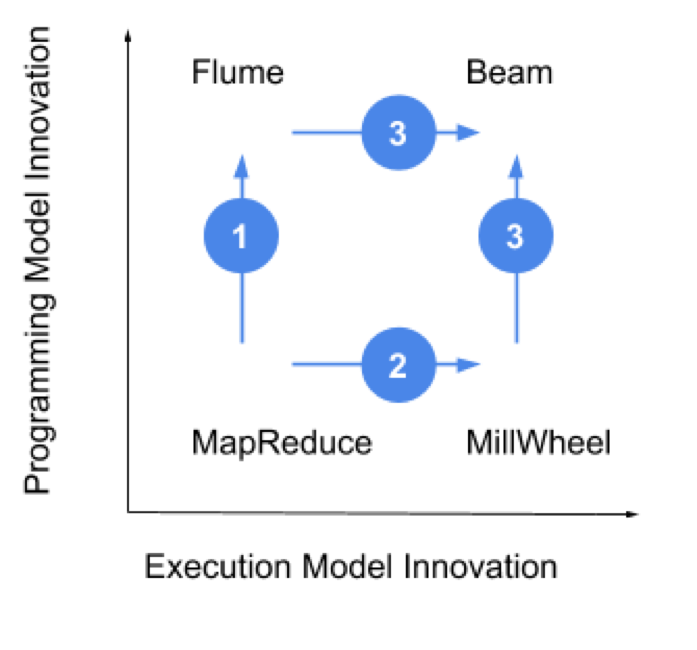
From the story of Beam’s origins emerge a set of principles:
从Beam起源的故事中得出一套原则:
- There are two degrees of innovation: programming model and execution model. Historically, we have assumed they need to be coupled, but open interfaces challenge that assumption.
- By decoupling the code with an abstraction, we also decouple the contributor community into interface designers and execution engine creators.
- Through abstraction and decoupling (technically and organizationally), the speed at which the community can absorb innovation accelerates.
- 这里关于创新有两种角度:编程模型和执行模型。从历史来看,我们假设它们需要耦合,但是开放接口挑战了这种假设。
- 通过抽象去解耦代码,我们也将贡献者社区解耦成接口设计者和执行引擎创建者。
- 通过抽象和解耦(技术和组织的角度),社区吸收创新的速度增加。
Consider these principles in the case of Keras. Despite TensorFlow’s popularity, users quickly realized that its API is not for everyday use. Keras’ easy abstractions, which already had a strong following among Theano users, made it the preferred API for TensorFlow. Since then, Amazon and Microsoft have added MxNet and CNKT, respectively, as back ends. This means that developers who choose the independent open interface Keras can now execute on all four major frameworks without any re-write. Organizations are consuming the latest in technology from all the brightest groups. New projects, like PlaidML, can quickly find an audience; a Keras developer can easily try out PlaidML without learning a new interface.
思考一下Keras的这些原则。尽管TensorFlow很受人欢迎,但用户很快意识到它的API并不适合日常使用。Keras简单的抽象已经在Theano中拥有很强大的跟随者,这也使其成为TensorFlow首选的API。从那时起,Amazon和Microsoft分别推出MxNet和CNKT作为其后端。这意味着那些选择独立开源接口Keras的开发者如今可以不必重写就能在4个主要框架上执行。所有组织正在使用来自所有最聪明群体中最新的技术。像 PlaidML 这个新的项目,能快速找到受众;一个Keras的开发者能轻松的尝试PlaidML而不需学习新的接口。
The Serverless story
无服务器的故事
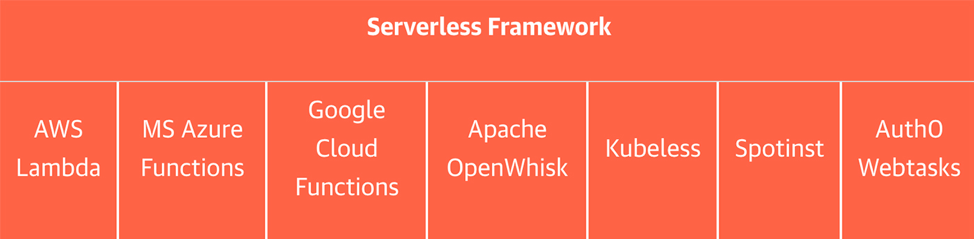
The Serverless Framework’s open interface vision has, like Beam’s, evolved and was not immediately apparent. I remember seeing the announcement of JAWS (Javascript AWS) on Hacker News in 2015, the same year Keras and Beam began. Months later, the JAWS team presented their AWS Lambda-specific framework at Re:Invent. It contained scaffolding, workflow, and best practices for Lambda, Amazon’s function as a service (FaaS) offering. But Lambda was just the first of several proprietary cloud and open source FaaS offerings. The JAWS framework soon rebranded itself as Serverless and supported the newcomers.
无服务器框架的开放接口愿景像Beam一样,在不断进化,并不能立即显现出来。我记得在2015年在《Hacker News》上看到了Javascript AWS 的公告。同年,Keras和Beam创建。几个月后,JAWS团队在 AWS Re:Invent 大会上提出他们的AWS Lambda 特定的框架。它包含了脚手架,工作流以及Lambda最佳实践。这就是 Amazon 的功能即服务(Function as a Service,FaaS)。但是Lambda只是几个专有云和开源FaaS产品中的一个。JAWS框架很快将自己重新命名为serverless并支持新来者。
Serverless still wasn’t a single open API interface until August 2017, when Austen Collins announced Event Gateway, the “missing piece of serverless architecture.” Even today, Serverless doesn’t offer their own execution environment. Gateway specifies a new FaaS API that abstracts and can use any of the popular execution environments. Collins’ value proposition for Event Gateway could have been taken from Keras or Beam: “Any of your events can have multiple subscribers from any other cloud service. Lambda can talk to Azure can talk to OpenWhisk. This makes businesses completely flexible...[it] protects you from lock-in, while also keeping you open for whatever else the future may bring.”
直到2017年8月,当 Austen Collins 宣称 Event Gateway(事件网关)是"无服务架构中缺失一块"时,无服务器仍然不是一个单个开放的API接口。即使在今天,无服务器也不提供他们自己的执行环境。网关指定了一个新的 FaaS API,该API可以抽象并能使用任何受欢迎的执行环境。Collins对于Event Gateway的价值主张可能就来自于Keras和Beam:“用户的任何事件都可能有来自任何云服务上的多个订阅者。Lambda可以和Azure对话,也可以和OpenWhisk对话。这使得企业得到了完全的灵活性,它从保护你免受锁定,同时也能使你对未来可能带来的一切保持开放。”
The driving forces
驱动力
As a venture investor, I find myself asking the skeptical questions: are metaframeworks a real trend? What is behind this trend? Why now? One key factor here is certainly cloud managed services.
作为一个风险投资者,我发现自己在问一些怀疑的问题:元架构是真正的趋势吗?这趋势的背后是什么呢?为什么是现在呢?这里的一个关键因素当然是云托管服务。
Virtually all of Google’s internal managed services employ unique, Google-specific APIs. For example, Google’s Bigtable was the first noSQL database. But because Google was shy about revealing details, the open source community dreamed up their own implementations: HBase, Cassandra, and others. Offering Bigtable as an external service would mean introducing yet another API, and a proprietary one to boot. Instead, Google Cloud Bigtable was released with an HBase-compatible API, meaning any HBase user can adopt Google’s Bigtable technology without any code changes. Offering proprietary services behind open interfaces appears to be the emerging standard for Google Cloud.
谷歌几乎所有的内部托管服务都使用独特的、特定于Google的 API。例如,Google的Bigtable是第一个noSQL数据库。但是由于Google不愿透露细节,开源社区就想了自己的实现方案:HBase,Cassandra等。提供Bigtable作为外部服务将意味着引入另一个API以及一个专有的API去启动。相反,Google Cloud Bigtable 与一个兼容HBase的API一起发布,这就意味着,任何HBase用户可以采取Google的Bigtable技术,而无需修改代码。开放接口的背后提供专有服务看上去好像是Google Cloud的新兴标准。
The other cloud providers are following suit. Microsoft is embracing open source and open interfaces at every turn, while Amazon is reluctantly being pulled into the mix by customers. Together the two have recently launched Gluon, an open API that, like Keras, executes on multiple deep learning frameworks. The trend of cloud providers exposing proprietary services behind open, well-adopted APIs is a win for users, who avoid lock-in and can adopt easily.
其他云厂商也在效仿。Microsoft处处都在拥抱开源以及开放接口,而 Amazon 则不情愿的被客户拉入到了这个圈子中。Microsoft和Amazon两家公司最近共同推出了 Gluon,一个类似Keras的开放API,能够在多个深度学习的框架中执行。云厂商在开放的,被广泛使用的API的背后公开专有服务的趋势,对用户来说是一件幸事,用户能够避免锁定,且更方便使用。
Looking forward
展望未来
With cloud offerings on the rise and the rate of complexity and innovation increasing, we are likely to see more open interfaces and metaframeworks emerge, but they have their drawbacks. Additional layers of abstraction introduce indirection. Debugging may become more difficult. Features may lag or simply go unsupported; an interface may provide access features that the execution engines share, but omit sophisticated or rarely used features that add value. Finally, a new approach to execution may not immediately fit in an existing API. PyTorch and Kafka Streams, for example, have recently grown in popularity and have yet to conform to the open interfaces provided by Keras and Beam. This not only leaves users with a difficult choice, but challenges the concept of the API framework altogether.
随着云服务的增加,复杂性和创新的速度也在增加,我们似乎能看到更多开放接口和元架构出现,但是它们仍然有缺点。额外的抽象层引入了间接性。调试可能会变得更加困难。功能可能会滞后或者根本得不到支持;一个接口可以提供执行引擎共享的访问特性,但省略了增加价值的复杂或很少使用的功能。最后,一种新的执行方法可能不能立即适用于现有的API。例如,像PyTorch和Kafka Streams,最近变得越来越流行,并且还没有符合Keras和Beam提供的开放接口。这不仅给用户留下一个艰难的选择,也给全部API框架的概念带来了挑战。
Considering the above, here are some tips for success in this new world:
综上所述,以下是一些取得成功的建议:
For API developers: The next time you find yourself bikeshedding on an API, consider (1) that it is an innovation vector all its own and (2) work with the entire industry to get it right. This is where the community and governance aspects of open source are critical. Getting consensus in distributed systems is hard, but François Chollet, Tyler Akidau, and Austen Collins have done a masterful job in their respective domains. Collins, for example, has been working with the CNCF’s Serverless Working Group to establish CloudEvents as an industry standard protocol.
对 API 开发者而言:下次当你发现你自己在一个接口上的琐事花费时间的时候,
1)它本身是一个创新载体;
2)与整个行业合作,把这件事情做好;
这就是开源的社区和治理方面的关键所在。在分布式系统上取得一致很难,但是 François Chollet, Tyler Akidau, and Austen Collins 已经在他们各自的领域做出了傲人的工作。例如 Collins,一直与CNCF的无服务器工作组合作,将CloudEvents建立为行业标准协议。
For service developers: Focus on performance. The open interfaces are now your distribution channel, leaving you free to focus on being the best execution framework. There is no longer a risk of great tech stuck behind laggards unwilling to try or adopt. With switching costs low, your improvements can easily be seen. Watch benchmarking become the norm.
对于服务开发者而言:专注于性能。开放接口现在是您的发行渠道,让您可以自由地专注于成为最佳执行框架。伟大的技术,将不会再有被那些不愿尝试或采用的落伍者所束缚的风险。由于转换成本较低,您的改进可以很容易地看到。观察基准测试将成为标准做法。
For users: Become active in the communities around these open interfaces. We need these to become lively town halls to keep the APIs use case driven and relevant. And try the different back ends that are available. It’s a new efficient freedom available to you, and it will incentivize performance and innovation.
对用户而言:在围绕这些开放接口的社区中变得活跃起来。用户需要这些社区保持活跃,以保持 API 用例驱动和相关。还可以尝试不同的可用后端。这是一种新的有效的自由,它将激励性能和创新。
For everyone: Consider helping out the projects that are mentioned in this post. Open interfaces are still new, and their future depends on the success of the pioneers.
对所有人而言:考虑帮助本文提到对项目。开放接口仍然是新的,并且他们的将来取决于先驱者们的成功。
附原文链接:
Why your next open source project may only be an interface
https://www.scalevp.com/blog/why-your-next-open-source-project-may-only-be-an-interface
附InfoQ翻译链接:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号