
别再犯低级错误,带你了解更新缓存的四种Desigh Pattern
在我们使用分布式缓存Redis或者Memcached编写更新缓存数据代码时,我们总是会犯一个逻辑错误。先删除缓存,然后再更新数据库,而后续的操作会把数据再装载的缓存中。试想,两个并发操作,一个是更新操作,另一个是查询操作,更新操作删除缓存后,查询操作没有命中缓存,先把老数据读出来后放到缓存中,然后更新操作更新了数据库。于是,在缓存中的数据还是老的数据,导致缓存中的数据是脏的,而且还一直这样脏下去了。
我不知道为什么这么多人用的都是这个逻辑,所以,我想写这篇文章说一下几个缓存更新的Design Pattern
这里,我们先不讨论更新缓存和更新数据这两个事是一个事务的事,或是会有失败的可能,我们先假设更新数据库和更新缓存都可以成功的情况(我们先把成功的代码逻辑先写对)。
更新缓存的的Design Pattern有四种:Cache aside, Read through, Write through, Write behind caching,我们下面一一来看一下这四种Pattern。
一、Cache Aside Pattern
这是最常用最常用的pattern了。其具体逻辑如下:
失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
命中:应用程序从cache中取数据,取到后返回。
更新:先把数据存到数据库中,成功后,再让缓存失效。
注意,我们的更新是先更新数据库,成功后,让缓存失效。那么,这种方式是否可以没有文章前面提到过的那个问题呢?我们可以脑补一下。
一个是查询操作,一个是更新操作的并发,首先,没有了删除cache数据的操作了,而是先更新了数据库中的数据,此时,缓存依然有效,所以,并发的查询操作拿的是没有更新的数据,但是,更新操作马上让缓存的失效了,后续的查询操作再把数据从数据库中拉出来。而不会像文章开头的那个逻辑产生的问题,后续的查询操作一直都在取老的数据。
二、Read/Write Through Pattern
我们可以看到,在上面的Cache Aside套路中,我们的应用代码需要维护两个数据存储,一个是缓存(Cache),一个是数据库(Repository)。所以,应用程序比较啰嗦。而Read/Write Through套路是把更新数据库(Repository)的操作由缓存自己代理了,所以,对于应用层来说,就简单很多了。可以理解为,应用认为后端就是一个单一的存储,而存储自己维护自己的Cache。
1.Read Through
Read Through 套路就是在查询操作中更新缓存,也就是说,当缓存失效的时候(过期或LRU换出),Cache Aside是由调用方负责把数据加载入缓存,而Read Through则用缓存服务自己来加载,从而对应用方是透明的。
2.Write Through
Write Through 套路和Read Through相仿,不过是在更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后再由Cache自己更新数据库(这是一个同步操作)
下图自来Wikipedia的Cache词条。其中的Memory你可以理解为就是我们例子里的数据库。
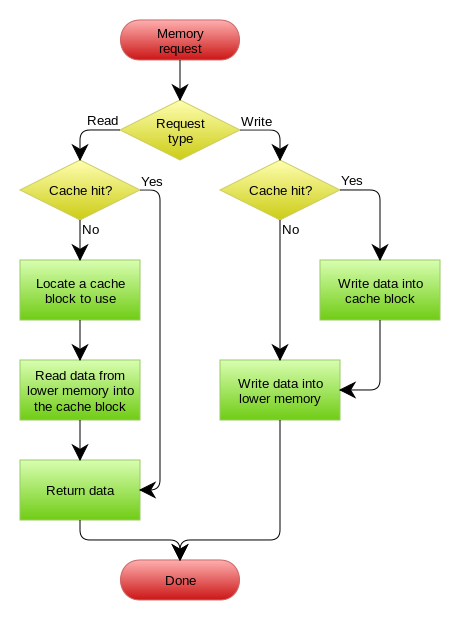
三、Write Behind Caching Pattern
Write Behind 又叫 Write Back。一些了解Linux操作系统内核的同学对write back应该非常熟悉,这不就是Linux文件系统的Page Cache的算法吗?是的,你看基础这玩意全都是相通的。所以,基础很重要,我已经不是一次说过基础很重要这事了。
Write Back套路,一句说就是,在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库。这个设计的好处就是让数据的I/O操作飞快无比(因为直接操作内存嘛 ),因为异步,write backg还可以合并对同一个数据的多次操作,所以性能的提高是相当可观的。
但是,其带来的问题是,数据不是强一致性的,而且可能会丢失(我们知道Unix/Linux非正常关机会导致数据丢失,就是因为这个事)。在软件设计上,我们基本上不可能做出一个没有缺陷的设计,就像算法设计中的时间换空间,空间换时间一个道理,有时候,强一致性和高性能,高可用和高性性是有冲突的。软件设计从来都是取舍Trade-Off。
另外,Write Back实现逻辑比较复杂,因为他需要track有哪数据是被更新了的,需要刷到持久层上。操作系统的write back会在仅当这个cache需要失效的时候,才会被真正持久起来,比如,内存不够了,或是进程退出了等情况,这又叫lazy write。
在wikipedia上有一张write back的流程图,基本逻辑如下:

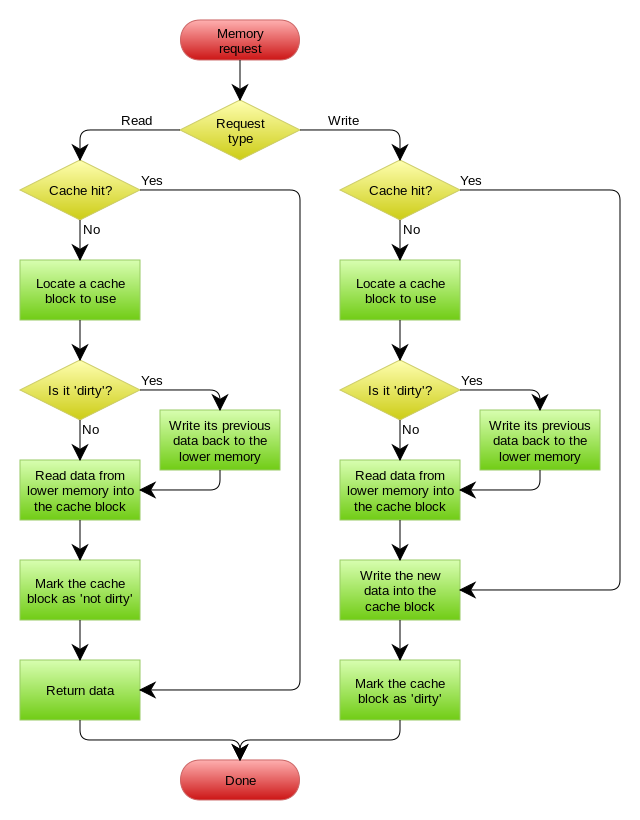
基本上来说,这些缓存更新的设计模式都是非常老古董的,而且历经长时间考验的策略,所以这也就是,工程学上所谓的Best Practice,遵从就好了。
另外,请允许我在这里放句观点鲜明的话——如果你要做好架构,首先你得把计算机体系结构以及很多老古董的基础技术吃透了。
所以,在软件开发或设计中,我非常建议在之前先去参考一下已有的设计和思路,看看相应的guideline,best practice或design pattern,吃透了已有的这些东西,再决定是否要重新发明轮子。千万不要似是而非地,想当然的做软件设计。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号