当我们以Web UI方式使用Heritrix时,点击任务开始(start)按钮时,Heritrix就开始了它的爬取工作.但它的内部
执行流程是怎样的呢?别急,下面将慢慢道来.
(一)CrawlJobHandler
当点击任务开始(start)按钮时,将执行它的startCrawler()方法:
if(sAction.equalsIgnoreCase("start"))
{
// Tell handler to start crawl job
handler.startCrawler();
}
再来看看startCrawler()方法的执行:

 Code
Code
public class CrawlJobHandler implements CrawlStatusListener {
public void startCrawler() {
running = true;
if (pendingCrawlJobs.size() > 0 && isCrawling() == false) {
// Ok, can just start the next job
startNextJob();
}
}
protected final void startNextJob() {
synchronized (this) {
if(startingNextJob != null) {
try {
startingNextJob.join();
} catch (InterruptedException e) {
e.printStackTrace();
return;
}
}
startingNextJob = new Thread(new Runnable() {
public void run() {
startNextJobInternal();
}
}, "StartNextJob");
//当前任务线程开始执行
startingNextJob.start();
}
}
protected void startNextJobInternal() {
if (pendingCrawlJobs.size() == 0 || isCrawling()) {
// No job ready or already crawling.
return;
}
//从待处理的任务列表取出一个任务
this.currentJob = (CrawlJob)pendingCrawlJobs.first();
assert pendingCrawlJobs.contains(currentJob) :
"pendingCrawlJobs is in an illegal state";
//从待处理列表中删除
pendingCrawlJobs.remove(currentJob);
try {
this.currentJob.setupForCrawlStart();
// This is ugly but needed so I can clear the currentJob
// reference in the crawlEnding and update the list of completed
// jobs. Also, crawlEnded can startup next job.
this.currentJob.getController().addCrawlStatusListener(this);
// now, actually start
//控制器真正开始执行的地方
this.currentJob.getController().requestCrawlStart();
} catch (InitializationException e) {
loadJob(getStateJobFile(this.currentJob.getDirectory()));
this.currentJob = null;
startNextJobInternal(); // Load the next job if there is one.
}
}
}由以上代码不难发现整个流程如下:
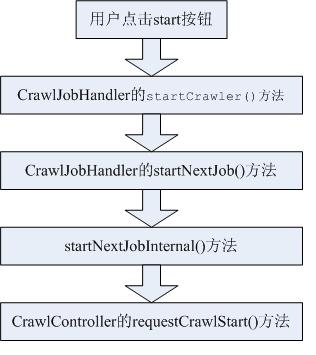
可以看出,最终将启动CrawlController的requestCrawlStart()方法.
(二)CrawlController
该类是一次抓取任务中的核心组件。它将决定整个抓取任务的开始和结束.
先看看它的源代码:
Code
package org.archive.crawler.framework;
public class CrawlController implements Serializable, Reporter {

// key subcomponents which define and implement a crawl in progress
private transient CrawlOrder order;
private transient CrawlScope scope;
private transient ProcessorChainList processorChains;
private transient Frontier frontier;
private transient ToePool toePool;
private transient ServerCache serverCache;
// This gets passed into the initialize method.
private transient SettingsHandler settingsHandler;
}
CrawlOrder:它保存了对该次抓取任务中order.xml的属性配置。
CrawlScope:决定当前抓取范围的一个组件。
ProcessorChainList:从名称上可知,其表示处理器链。
Frontier:它是一个URL的处理器,决定下一个要被处理的URL是什么。
ToePool:它表示一个线程池,管理了所有该抓取任务所创建的子线程。
ServerCache:它表示一个缓冲池,保存了所有在当前任务中,抓取过的Host名称和Server名称。
在构造 CrawlController实例,需要先做以下工作:
(1)首先构造一个XMLSettingsHandler对象,将order.xml内的属性信息装入,并调用它的initialize方法进行初始化。
(2)调用CrawlController构造函数,构造一个CrawlController实例
(3)调用CrawlController的initilize(SettingsHandler)方法,初始化CrawlController实例。其中,传入的参数就是
在第一步里构造的XMLSettingsHandler实例。
(4 )当上述3步完成后,CrawlController就具备了运行的条件。此时,只需调用它的requestCrawlStart()方法,就
可以启动线程池和Frontier,然后开始不断的抓取网页。
先来看看initilize(SettingsHandler)方法:
Code
public void initialize(SettingsHandler sH)
throws InitializationException {
sendCrawlStateChangeEvent(PREPARING, CrawlJob.STATUS_PREPARING);
this.singleThreadLock = new ReentrantLock();
this.settingsHandler = sH;
//从XMLSettingsHandler中取出Order
this.order = settingsHandler.getOrder();
this.order.setController(this);
this.bigmaps = new Hashtable<String,CachedBdbMap<?,?>>();
sExit = "";
this.manifest = new StringBuffer();
String onFailMessage = "";
try {
onFailMessage = "You must set the User-Agent and From HTTP" +
" header values to acceptable strings. \n" +
" User-Agent: [software-name](+[info-url])[misc]\n" +
" From: [email-address]\n";
//检查了用户设定的UserAgent等信息,看是否符合格式
order.checkUserAgentAndFrom();
onFailMessage = "Unable to setup disk";
if (disk == null) {
setupDisk(); //设定了开始抓取后保存文件信息的目录结构
}
onFailMessage = "Unable to create log file(s)";
//初始化了日志信息的记录工具
setupLogs();
onFailMessage = "Unable to test/run checkpoint recover";
this.checkpointRecover = getCheckpointRecover();
if (this.checkpointRecover == null) {
this.checkpointer =
new Checkpointer(this, this.checkpointsDisk);
} else {
setupCheckpointRecover();
}
onFailMessage = "Unable to setup bdb environment.";
//初始化使用Berkley DB的一些工具
setupBdb();
onFailMessage = "Unable to setup statistics";
setupStatTracking();
onFailMessage = "Unable to setup crawl modules";
//初始化了Scope、Frontier以及ProcessorChain
setupCrawlModules();
} catch (Exception e) {
String tmp = "On crawl: "
+ settingsHandler.getSettingsObject(null).getName() + " " +
onFailMessage;
LOGGER.log(Level.SEVERE, tmp, e);
throw new InitializationException(tmp, e);
}
Lookup.getDefaultCache(DClass.IN).setMaxEntries(1);
//dns.getRecords("localhost", Type.A, DClass.IN);
//实例化线程池
setupToePool();
setThresholds();
reserveMemory = new LinkedList<char[]>();
for(int i = 1; i < RESERVE_BLOCKS; i++) {
reserveMemory.add(new char[RESERVE_BLOCK_SIZE]);
}
}
可以看出在initilize()方法中主要做一些初始化工作,但这些对于Heritrix的运行是必需的.
再来看看CrawlController的核心,requestCrawlStart()方法:
Code
public void requestCrawlStart() {
//初始化处理器链
runProcessorInitialTasks();
sendCrawlStateChangeEvent(STARTED, CrawlJob.STATUS_PENDING);
String jobState;
state = RUNNING;
jobState = CrawlJob.STATUS_RUNNING;
sendCrawlStateChangeEvent(this.state, jobState);
// A proper exit will change this value.
this.sExit = CrawlJob.STATUS_FINISHED_ABNORMAL;
Thread statLogger = new Thread(statistics);
statLogger.setName("StatLogger");
//开始日志线程
statLogger.start();
//启运Frontier,抓取工作开始
frontier.start();
}
可以看出,做了那么多工作,最终将启动Frontier的start方法,而Frontier将为线程池的线程提供URI,真正开始
抓取任务.至此,抓取任务开始.
主要参考:开发自己的搜索引擎—Lucene 2.0+Heritrix



