

深入学习heritrix---体系结构(Overview of the crawler)
Heritrix采用了模块化的设计,它由一些核心类(core classes)和可插件模块(pluggable modules)构成。
核心类可以配置,但不能被覆盖,插件模块可以被由第三方模块取代。
(一)heritrix的体系结构图:
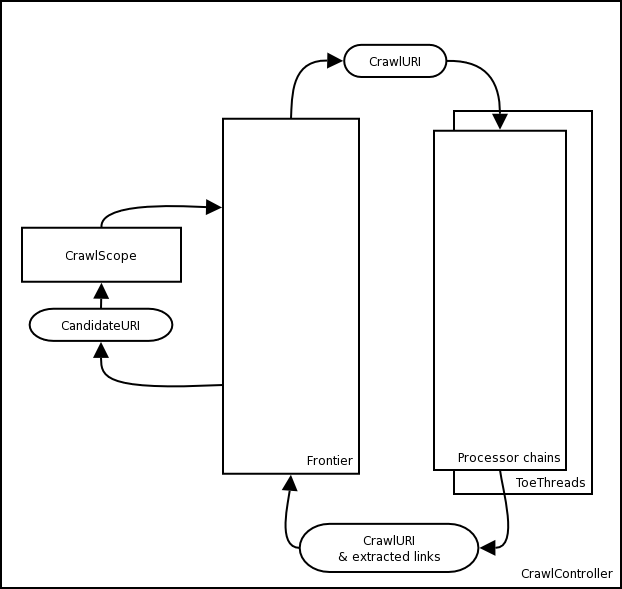
(二)架构分析
CrawlController(下载控制器)
整个下载过程的总的控制者,整个抓取工作的起点,决定整个抓取任务的开始和结束。从Frontier获取URI,传递给
线程池(ToePool)中的ToeThread处理。
Frointier(边界控制器)
主要确定下一个将被处理的URI,负责访问的均衡处理,避免对某一web服务器造成太大的压力。
它保存着crawl的状态:
(1)发现的URI(URIs have been discovered)
(2)正在被处理的URI(URIs are being processed (fetched))
(3)已经处理的URI(URIs have been processed)
TeoThread(处理线程)
Heritrix是多线程的,每一个URI被一个ToeThread处理。
Processor(处理器)
下图为处理器的整个结构图
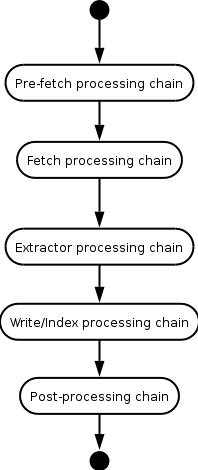
许多Processor组成一个处理链(processor chains)中,每一个处理链对URI进行一系列的处理。
(1)Pre-fetch processing chain(预处理链)
主要根据robot协议,DNS以及下载范围控制信息判断当前URI是否应当处理。
(2)Fetch processing chain(抓取处理链)
从远程服务器获取数据
(3) Extractor processing chain(抽取处理链)
从网页中抽取新的URI
(4)Write/index processing chain(写处理链)
负责把数据写入本地磁盘
(5)Post-processing chain(后置处理链)
由CrawlStateUpdater,LinksScoper,FrontierScheduler构成。
主要参考:Heritrix文档

