

性能测试主要指标
https://www.cnblogs.com/york-hust/archive/2013/05/23/3094233.html
1、响应时间&响应率
客户从发出请求到得到响应的整个时间; “TTLB”(Time to laster byte),从发起一个请求开始,到客户端收到最后一个字节的响应所耗费的时间。

红色虚线 表求的是一种系统的理想状态。 当服务器处理10个用户请求时所用的时间是2秒(假设),当服务器处理200用户请求时所用的时间也是2秒。 蓝色斜线 是服务器常见的一种曲线状态。 服务器的响应时间虽然用户数量的增加逐渐变慢。 当系统出现这种斜线,应该说系统性能是相当健壮的。随着用户的增长响应时间逐渐变长。 黑色曲线 服务器处理能力的真实曲线状态。 理发店模式 系统的拐角点 我们假设有一个门,在一个时间点上可同时过10个人,不管你是同时来3个还是10个都可以在同一时间点过门,假如来了11个人,必然有一个人要等10个人过门之后才能过。 那么当超过10人来过门时,过门的速度就开始变慢。那么10就是服务器性能的拐角点。我们通常做压力测试找服务器的拐角点是很重要的任务之一。 测试的细度,影响图像的结果
响应时间过程分析
呈现时间
不同浏览器显示
操作系统、电脑硬件(cpu、内存)
数据传输时间
送信
发送请求时间、返回信息时间
压测互联网(局域网)
系统处理时间
系统得到请求后对请求进行处理并将结果返回
性能测试重点需要验证的时间
用户的电脑、网络状况不可控
系统处理时间可控
系统的的处理,语言、语言框架、中间件,数据库、系统架构以及服务器系统。
实际的性能测试 现在的测试工具都屏蔽呈现过程,只是模拟多用户并发请求,计算用户得到响应的时间,页不会将服务器的每个响应都向客户端呈现。 对于数据传输的问题,强调的性能测试要在局域网中进行,在局域网中一般不会受到数据带宽的限制。所以,可以对数据的传输时间忽略不计。
两种情况:
访问网页首页,图片返回不完全
系统查询数据,返回数据分页
关于响应时间,要特别说明的一点是,对客户来说,该值是否能够被接受是带有一定的用户主观色彩,也就是说,响应时间的“长”和“短”没有绝对的区别。
合理的响应时间
互联网用户响应时间普通标准:2/5/10秒原则。
“非常有吸引力”-》“比较不错”-》“糟糕”-》“失败的请求”
考虑使用频率
安装系统
日常安装软件
税务系统
“合理的响应时间”取决于用户的需求,而不能依据测试人员自己设想来决定。
**
响应率 Request与Response是对应,一个请求对应一个响应。 但当客户端对服务器的压力达到一直程度后,不是每一请求都能得到响应的。 12306 "成功响应率也是很重要的一个指标。客户端发送一千个请求的成功得到响应的几率。 "
2、吞吐量&吞吐率
对于交互式应用来说,吞吐量指标反映的是服务器承受的压力 如一个大型工厂,他们的生产效率与生产速度很快,一天生产10W吨的货物,结果工厂的运输能力不行,就两辆小型三轮车一天拉2吨的货物,比喻有些夸张,但我想说明的是这个运输能力是整个系统的瓶颈。
提示,用吞吐量来衡量一个系统的输出能力是极其不准确的,用个最简单的例子说明,一个水龙头开一天一夜,流出10吨水;10个水龙头开1秒钟,流出0.1吨水。 当然是一个水龙头的吞吐量大。但是不能说1个水龙头的出水能力是10个水龙头的强 所以,我们要加单位时间,看谁1秒钟的出水量大。这就是吞吐率。
吞吐率Ti & To 单位时间的吞吐量,吞吐量/秒。 吞吐量:单位时间内网络上传输的数据量,也可以指单位时间内处理的客户端请求数量。 “请求数/秒”、“字节数/秒”、“页面数/秒”
不同的方式表达的吞吐量可以说明不同层次的问题。
例如,以字节数/秒方式表示的吞吐量主要受网络基础设置、服务器架构、应用服务器制约;以请求数/秒方式表示的吞吐量主要受应用服务器和应用代码的制约。
站在服务器端,T-in表示“吞”;T-out表求“吐”
Ti:T-in 主要衡量服务器接受的请求数据包的吞吐率。
To: T-out 主要衡量的服务器端返回已处理数据包的吞吐率。
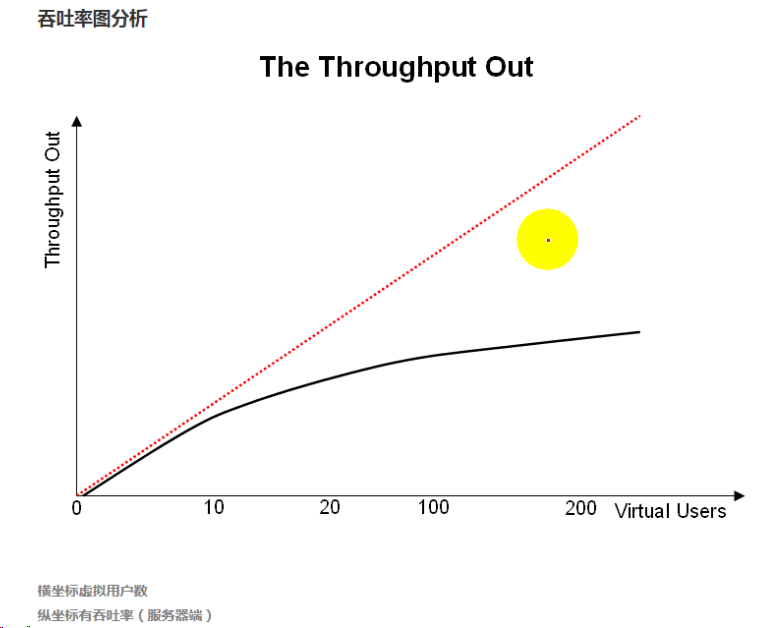
红色虚线,表示一种理想的状态。 随着用户数量的增加吞吐率也在持续增加。
黑色曲线,表示现实系统的吞吐率状态。 刚开始吞吐率随着用户数量的增加逐渐变大,当大到一定程度时,逐渐平缓直到变成一条平线。 如果用户还在持续增加中,那么吞吐率有可能下降,直到系统挂掉。
到了下班高峰期,车子变多,一下来了20辆,但这个路口的绿灯每天只能通过10辆,所以,这个时候,路口的通过率不会根据车辆的增加而继续增加。 好的系统好像好有个好的交警在位置秩序,虽然车辆还在增加,但每个车辆都有条不紊等待通过路口。 不好的系统如路口赶上交警拉肚子,车辆在增加,后面车辆等得不耐烦就往前挤,结果稿得互不相让。好嘛!之后还每个绿灯可通过10辆,现在只能有一辆车从夹缝中脱离苦海了。
响应时间图与吞吐率图并不是我们一轮性能测试下来就能得到结果。需要经过多轮测试才能得到。设置不同的用户数量,得到每次的测试数据,将每次数据连接,从而得到最终系统性能曲线。关于用户数量每次增加的数量自己把握。 每做完一轮测试后对数据进行分析,然后确定下轮测试所要设置的虚拟用户数。
吞吐量指标的作用 用户协助设计性能测试场景,以及衡量性能测试场景是否达到了预期的设计目标: 在设计性能测试场景时,吞吐量可被用户协助设计性能测试场景,根据估算的吞吐量数据,可以对应到测试场景的事务发生频率,事务发生次数等; 另外,在测试完成后,根据实际的吞吐量可以衡量测试是否达到了预期的目标。
用于协助分析性能瓶颈:
吞吐量的限制是性能瓶颈的一种重要表现形式,因此,有针对性地对吞吐量设计测试,可以协助尽快定位到性能冰晶所在位置。
3、qps和tps
事务 从业务的角度看,吞吐率=“业务数/小时或天”、“访问人数/小时或天”、“页面访问量/小时或天”。银行卡审批系统,“千件/小时”。 从用户的角度,一个表单提交可以得到一次审批。又引出来一个概念---事务。 就是用户某一步或几步操作的集合。 某一个页面的一次请求,系统的一次登录,淘宝支付。衡量服务器对事务的处理能力----TPS TPS (Transaction Per second) 每秒钟系统能够处理事务或交易的数量,它是衡量系统处理能力的重要指标。
每秒处理的事务数目。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。
客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数,最终利用这些信息作出的评估分。
TPS 的过程包括:客户端请求服务端、服务端内部处理、服务端返回客户端。
QPS(Queries Per Second) 是一台服务器每秒能够响应的查询次数 QPS = req/sec = 请求数/秒 qps与tps的区别 qps基本类似于tps 一次访问,一次tps,多个qps 例如,访问一个 Index 页面会请求服务器 3 次,包括一次 html,一次 css,一次 js,那么访问这一个页面就会产生一个“T”,产生三个“Q”。
如果是对一个接口(单场景)压测,且这个接口内部不会再去请求其它接口,那么TPS等于QPS,否则,TPS不等于QPS
计算公式: QPS(TPS):每秒钟request/事务 数量 并发数: 系统同时处理的request/事务数 响应时间: 一般取平均响应时间
QPS(TPS)= 并发数/平均响应时间 或者 并发数 =QPS(TPS)*平均响应时间
4、并发用户数
提交请求的用户总数 大家都知道我们的性能测试就通过工具模拟多用户对系统进行操作,对系统造成压力,来验证系统的性能(不太标准的解释)。好多人也简单的把性能测试当成并发测试。 “多用户”+“同时” 并发的两种情况 严格意义上的并发:所有的用户在同一时刻做同一件事或操作,同时刻登录,同时提交表单。 广义范围的并发:请求或都操作可以是相同的,也可以是不同的。比如,在同时有的用户在登录,有的用户在提交表单。 真正意义上的并发不存在 CPU在一个时间点上只能干一件事儿。 因为它很快,所以,它可以在多个程序之间快速瞬间的切换,给你造成的假象就是它在同时做这些事情。
神医看病-》先分类、扩大接待室
神医(CPU)-》接待人员、医院(系统)-》病人(用户)
所以,我们一般测试的目的是看医院的接待能力-》系统能力
系统用户数与同时在线人数 已注册用户数-》系统用户数 同时登录网站的人数-》同时在线人数
并发用户数:取决于业务并发用户数和业务场景,一般可以通过服务器日志的分析得到。
三一理发师理论 3名理发师,每个理发师剪一个头发的时间是1个小时,每个客户的接受的最长理发时间是3小时。
1位顾客:1名理发师。1小时,理发店服务1位顾客,顾客花费时间1小时; 两位顾客 三位顾客 顾客数量从1位增加到3位的过程中,理发店的整体工作效率在提高,但是每位顾客在理发店内所呆的时间并未延长。 6位顾客 前三位所花费的时间均为1小时。后三位所花费的时间均为2小时 9位顾客,3位的“响应时间”为1小时,3位的“响应时间”为2小时(等待1小时+剪发1小时),3位的“响应时间”为3小时(等待2小时+剪发1小时)——已经到达用户所能忍受的极限。 10位顾客,一定会有1位顾客因为“响应时间”过长而无法忍受,最终离开理发店走了。
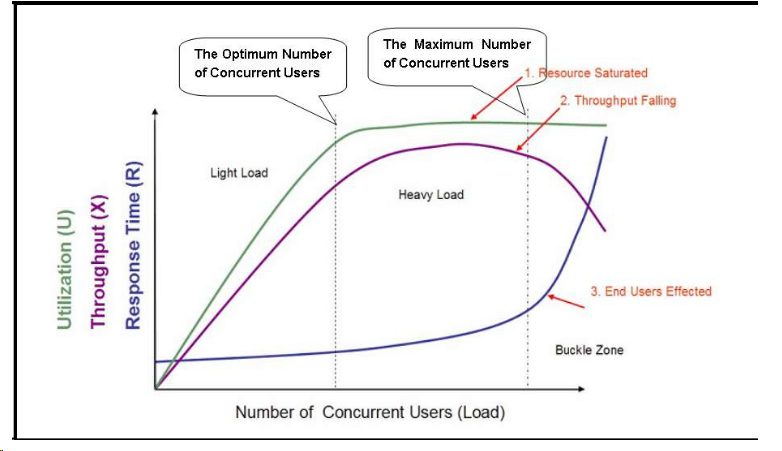
这张图中展示的是1个标准的软件性能模型。 三条曲线,分别表示资源的利用情况(Utilization,包括硬件资源和软件资源)、吞吐量(Throughput,这里是指每秒事务数)以及响应时间(Response Time)。 横轴:并发用户数 最开始,随着并发用户数的增长,资源占用率和吞吐量会相应的增长,但是响应时间的变化不大; 并发用户数增长到一定程度后,资源占用达到饱和,吞吐量增长明显放缓甚至停止增长,而响应时间却进一步延长。 并发用户数继续增长,软硬件资源占用继续维持在饱和状态,但是吞吐量开始下降,响应时间明显的超出了用户可接受的范围,并且最终导致用户放弃了这次请求甚至离开。 根据这种性能表现,划分三个区域,Light Load(较轻的压力)、Heavy Load(较重的压力)和Buckle Zone(用户无法忍受并放弃请求)。 在Light Load和Heavy Load 两个区域交界处的并发用户数,我们称为“最佳并发用户数(The Optimum Number of Concurrent Users)”,而Heavy Load和Buckle Zone两个区域交界处的并发用户数则称为“最大并发用户数(The Maximum Number of Concurrent Users)”。 当系统的负载等于最佳并发用户数时,系统的整体效率最高,没有资源被浪费,用户也不需要等待; 当系统负载处于最佳并发用户数和最大并发用户数之间时,系统可以继续工作,但是用户的等待时间延长,满意度开始降低,并且如果负载一直持续,将最终会导致有些用户无法忍受而放弃; 而当系统负载大于最大并发用户数时,将注定会导致某些用户无法忍受超长的响应时间而放弃。 理发店 最佳并发用户数-》每小时3个顾客 最大并发用户数-》每小时9个顾客 9个以后
对于一个确定的被测系统来说,在某个具体的软硬件环境下,它的“最佳并发用户数”和“最大并发用户数”都是客观存在。
最佳并发用户数 以“最佳并发用户数”为例,假如一个系统的最佳并发用户数是50,那么一旦并发量超过这个值,系统的吞吐量和响应时间必然会 “此消彼长”;如果系统负载长期大于这个数,必然会导致用户的满意度降低并最终达到一种无法忍受的地步。 最佳并发用户数要大于系统的平均负载。
当需要对一个系统长时间施加压力——例如连续加压3-5天,来验证系统的可靠性或者说稳定性时,我们所使用的并发用户数应该等于或小于“最佳并发用户数”
最大并发用户数
系统的最大并发用户数要大于系统需要承受的峰值负载
5、CPU负载
CPU负载显示的是一段时间内正在使用和等待使用CPU的平均任务数
CPU利用率高,并不意味着负载就一定大。 某公用电话亭,有一个人在打电话,四个人在等待,每人限定使用电话一分钟,若有人一分钟之内没有打完电话,只能挂掉电话去排队,等待下一轮。电话在这里就相当于CPU,而正在或等待打电话的人就相当于任务数。 在电话亭使用过程中,肯定会有人打完电话走掉,有人没有打完电话而选择重新排队,更会有新增的人在这儿排队,这个人数的变化就相当于任务数的增减。 为了统计平均负载情况,我们5秒钟统计一次人数,并在第1、5、15分钟的时候对统计情况取平均值,从而形成第1、5、15分钟的平均负载。
有的人拿起电话就打,一直打完1分钟,而有的人可能前三十秒在找电话号码,或者在犹豫要不要打,后三十秒才真正在打电话。如果把电话看作CPU,人数看作任务,我们就说前一个人(任务)的CPU利用率高,后一个人(任务)的CPU利用率低。 当然, CPU并不会在前三十秒工作,后三十秒歇着,只是说,有的程序涉及到大量的计算,所以CPU利用率就高,而有的程序牵涉到计算的部分很少,CPU利用率自然就低。
但无论CPU的利用率是高是低,跟后面有多少任务在排队没有必然关系。
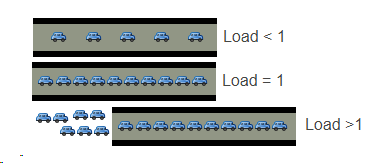
单核处理器 假设我们的系统是单CPU单内核的,把它比喻成是一条单向马路,把CPU任务比作汽车。当车不多的时候,load <1;当车占满整个马路的时候 load=1;当马路都站满了,而且马路外还堆满了汽车的时候,load>1
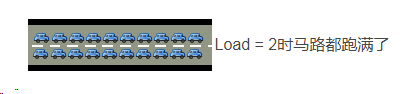
多核处理器 我们经常会发现服务器Load > 1但是运行仍然不错,那是因为服务器是多核处理器(Multi-core)。 假设我们服务器CPU是2核,那么将意味我们拥有2条马路,我们的Load = 2时,所有马路都跑满车辆。
了解了CPU负载的含义,我们如何来降低服务器的CPU负载呢? 最简单办法的是更换性能更好的服务器,不要想着仅仅提高CPU的性能,那没有用,CPU要发挥出它最好的性能还需要其它软硬件的配合。 在服务器其它方面配置合理的情况下,CPU数量和CPU核心数(即内核数)都会影响到CPU负载,因为任务最终是要分配到CPU核心去处理的。两块CPU要比一块CPU好,双核要比单核好。 因此,我们需要记住,除去CPU性能上的差异,CPU负载是基于内核数来计算的!有一个说法,“有多少内核,即有多少负载”。
CPU负载分担到每个CPU上的负载是多少呢?那就要看我这台服务器有一共有多少个内核了。 假设服务器CPU型号为Intel(R) Xeon(R) CPU E5320,双CPU,每个CPU都是双核,相当于服务器有4个内核。 前面我们说CPU负载是基于CPU内核数计算的,那么以前十五分钟的平均负载数10.49为例,我们可以得出,这台服务器每个CPU的负载为5.245,再分配到内核上,每个内核的负载为2.6左右。 CPU负载为多少才算比较理想 网上普通说法:CPU负载小于等于0.7算是一种理想状态。 不管某个CPU的性能有多好,1秒钟能处理多少任务,我们可以认为它无关紧要,虽然事实并非如此。在评估CPU负载时,我们只以5秒钟为单位为统计任务队列长度。如果每隔5秒钟统计的时候,发现任务队列长度都是1,那么CPU负载就为1。 假如我们只有一个单核的CPU,负载一直为1,意味着没有任务在排队,还不错。
上面提到的我那台服务器,是双核又CPU,等于是有4个内核,每个内核的负载为1的话,总负载为4。这就是说,如果我那台服务器的CPU负载长期保持在4左右,还可以接受。但实际上CPU负载已经达到9以上了,所以就很麻烦了。 但是每个内核的负载为1,并不能算是一种理想状态!这意味着我们的CPU一直很忙,不得清闲。网上有说理想的状态是每个内核的负载为0.7左右,我比较赞同,0.7乘以内核数,得出服务器理想的CPU负载,比如我这台服务器,负载在3.0以下就可以。
linux系统可以通过命令"w"查看当前load average情况

表示1分钟/5分钟/15分钟内,一共有1.3/1.48/1.69个任务在使用和等待使用CPU
三种Load值,应该看哪个: 通常我们先看15分钟load,如果load很高,再看1分钟和5分钟负载,查看是否有下降趋势。 1分钟负载值 > 1,那么我们不用担心,但是如果15分钟负载都超过1,我们要赶紧看看发生了什么事情。所以我们要根据实际情况查看这三个值
6、其它指标
CPU过高:说明出现硬件瓶颈,这时不管软件如何优化,性能也提升不上去,需要从硬件着手;
内存:测试过程中,要观察内存是否得到释放,内存是否存在泄露、溢出;
IO:硬盘读写(例如:打开word文档时会觉得慢,这时是在向硬盘读这一块的数据,点击保存的时候,就是在往硬盘里面写数据,也比较慢)。
