
合理使用DataTable与Entity集合
大家都知道,DataTable是个数据集,相当于数据表在内存中的映射。微软在提供的这个类非常方便,可以轻松的绑定在DataGrid控件上;Entity是实体类,即我们根据具体领域,所定义的对象类型。
我们在设计软件时有两个不同的思路:
一、 根据需求先设计数据表以及数据表之间的关系。表之间的关系有一对一,一对多,多对多。整个开发过程中以表为核心,对数据表进行操作。
二、先建立对象模型,建立对象之间的关系。对象之间关系要丰富,有关联、聚合、组合、派生、依赖。开发过程以对象模型为核心,进行各项操作。
那么这两个思路哪个科学呢?估计大家都知道是第二者。我们在设计一个软件或者模块时,要先进行需求分析,设计对象以及对象之间的关系、动作。一个软件基本离不开数据库的支持,因为我们需要把数据保存起来,供下次查询调用,即持久化。我们只要把数据库看作是个持久化介质。因为持久化介质还很多,例如xml文件,内存等等。当然用数据库是最方便和效率的,在这只是举例,明确一下要以对象模型,即Entity为核心,数据库的操作只是Entity的动作而已。
到这里问题就来了,既然以Entity为核心,我们就抛弃DataTable。直接使用ORM,把数据库映射为object。现在微软对ORM的支持相当丰富。但有个问题在里面有个问题:效率。
为什么会有效率问题呢?因为先查询数据库,然后再通过数据库与Entity之间的关系来创建一个Entity.现有框架对此功能的实现都是通过动态创建的,需要通过反射构造Entity,然后将查询的结果集数据赋值给Entity的属性。经过此转换消耗了一定的效率。而且每次都要把表中多有列都查询出来,这样就做不了查询的优化。不如直接使用DataTable绑定效率高。而仅仅使用DataTable又会很容易回到第一种思路上,就不是很科学了。怎么能保证开发设计的合理性,又能满足对效率要求较高的系统呢。
在这里我提出个解决方法仅供大家参考:
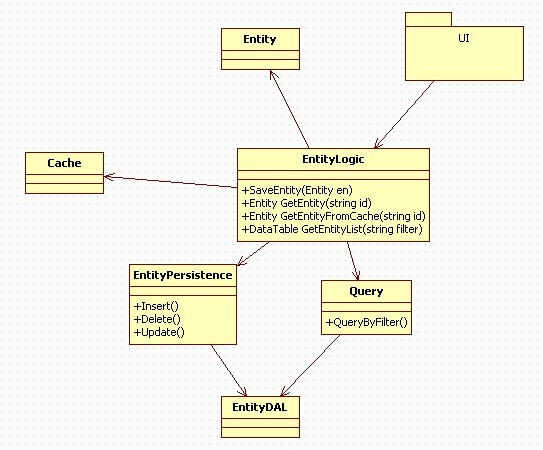
这个类图体现了分层,将持久层与逻辑层分开。这里不解释分层的优劣,只讲一下DataTable和Entity的使用。EntityLogic为UI提供服务,分别以这两种类型返回数据。对象列表以DataTable的形式返回,单个对象以Entity的形式返回。
EntityLogic各方法介绍:
SaveEntity:保存实体,即将Entity持久化,保存到数据库中。
GetEntity:获取一个实体,从持久化介质中读取数据,构造一个实体对象。如果缓存中存在此实体,从缓存中读取。返回Entity
GetEntityFromCache:获取一个实体,从缓存中读取数据。返回Entity
GetEntityList:获取对象列表,返回的是DataTable
为什么要这样区分呢?
因为批量查询是最消耗资源的,如果直接提供一个DataTable给UI,就比返回Entity集合效率高的多。但这样就破坏了面向对象的好处。如果我们想使用DataRow进行一些其他的操作,从DataRow里获取数据就会是这种形式DataRow[“ColumnName”],这样就不如Entity.GetPropery使用起来更直观和易维护。所以在这里,DataTable只作为显示用,不做其他的业务操作。
如果在查询的结果中再操作怎么办呢。那就需要用GetEntity方法,此方法提供了一个缓存的功能。可以根据对象的ID,获取到Entity。我们就可以使用Entity.GetPropery进行编程了。
这里关键问题就是缓存,缓存设计是很有讲究的,要定时清除,还要与持久层同步。所以会增加开发难度。在这里不详细介绍了。
总结:
通过DataTable与Entity的合理使用,即保证了软件开发的科学性,又保持了原有的效率。
本人提出一个思路,希望给大家得到启发,也希望大家进行交流,找到更合理的方法。


