寒假作业 (2/2)
寒假作业 (2/2)
作业描述
| 这个作业属于哪个课程 | 2021春软件工程实践|W班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业 (2/2) |
| 这个作业的目标 | 1. 阅读《构建之法》并提问 2. WordCount编程 |
| 其他参考文献 |
阅读《构建之法》并提问
2.3 中提到了 PSP 依赖于数据
本次作业中,我也发现了PSP记录并不完整,很多东西并不存在PSP记录表内,除此之外计算时间的精确度也非常影响,很多时候你无法确定你接下来做的事情恰好属于某一个内容,请问如何准确记录?
4.3 中提到了函数最好有单一的出口,为了达到这一目的,可以使用goto。
我认为无论如何 goto 语句都是最好不要使用的语句,会让代码的逻辑混乱,造成更多不可知的bug 很多时候根本可以用其他的语法取代,因此我认为无论如何都不应该用goto。这是我与书中相悖的地方
找不到了 中提到了程序过早优化的问题,说尽量不要过早优化
如果程序不尽量在早期优化的话,会导致回归测试需要做多遍,优化的度是什么样比较合适?
9.3 PM做开发和测试之外的所有事情
这个对PM的要求是不是太高了?据我所知软件工程的开发过程还需要运营?
12.2 中说道程序员不该等待设计师的图后再工作
我认为这里说的实在是太简单了,如果是一开始的话,可以进行架构等方面的设计,但是如果到了绘制页面的阶段的时候,我们已经把功能做完了,没设计师的图,我们干啥?难道不是还是要等吗?
WordCount 编程
项目地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 35 |
| • Estimate | • 估计这个任务需要多少时间 | 770 | 575 |
| Development | 开发 | 680 | 500 |
| • Analysis | • 需求分析 (包括学习新技术) | 170 | 200 |
| • Design Spec | • 生成设计文档 | 30 | 30 |
| • Design Review | • 设计复审 | 10 | 5 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 40 |
| • Design | • 具体设计 | 10 | 5 |
| • Coding | • 具体编码 | 180 | 100 |
| • Code Review | • 代码复审 | 30 | 10 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 220 | 125 |
| Reporting | 报告 | 40 | 40 |
| • Test Report | • 测试报告 | 10 | 10 |
| • Size Measurement | • 计算工作量 | 10 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 20 | 20 |
| Sum | 合计 | 770 | 595 |
解题思路
1. github
之前做项目的时候经常用到 github,这次在查询 github PR 最佳实践的时候发现了一个之前几乎没用过的 git rebase ,印象里这个指令和 git merge 差不多,但是以往的项目一般都是用 git merge 上网查询了差别后,发现 git rebase 可以使提交线变为一条直线。merge 后会有额外的一次 commit。感觉使用上两者其实都行,merge 比较经常用,因此还是用 merge 合并分支。
2. 代码规范
做项目一直用的是 vscode + eslint 配合检查语法规范,有些项目会在 pre-commit 钩子函数检查语法。会根据助教的问题 配合 airbnb 的 JS 语法规范以及与规范的冲突部分撰写。
3. 基本需求
看到基本需求部分,统计文件的字符数,单词总数以及有效行数等都可以用正则表达式进行解决,唯一比较困惑的地方是空白字符是什么,经过查阅呢,了解到,只要是看不见的字符都可以称作空白字符,这个正则表达式也有相应的解决方法。不过在统计单词出现的次数这里,emm ,想到了之前好像有用过 Trie 实现,查阅后发现只适合比较短的单词,这里的单词至少4个英文字母,又要跟上字母数字符号,因此实际上深度造的 Trie 树深度会很深,而且分支会很大,恐怕造成的内存开销会很大,因此还是采用最简单的Map形式实现就好,由于需要遍历一遍文档查找单词,因此时间复杂度至少是O(n),因此也没必要过多优化,在寻找频率最高的10个的时候直接用 Map 遍历一遍就行了,没必要单独维护一个数组记录,最后直接产出,因为算法的时间复杂度不会有根本性的差异,简化实现反而可以避免 BUG。查询正则表达式的时间复杂度……
4. 接口封装
这个接口封装部分,其实在 node 里面,还算是比较常规的操作了,通过模块化的方式,把接口分离,需要解决的问题是,node 如何写命令行程序,单元测试如何配合 node 进行使用,之前了解过单元测试框架 jest 。顺便了解一下 e2e 框架是什么,原来是和 http 有关的,那打扰了。数据的可视化部分实际上可以采用 echarts 或者 G2 等图形化界面进行展示,也就是说产出的接口可能需要满足一定的格式要求。
5. 单元测试
单元测试部分,提到了用白盒测试,并不清楚白盒测试是指什么,查阅后似乎就是要尽量的覆盖到测试的各个部分,例如各个条件分支等。
6. 性能分析
关于性能分析这一块的话,node 层面要做的话,node 并没有原生自带性能分析的软件,需要配合一些性能分析的工具,经查阅可以采用Node-Monitor 进行项目的性能分析。可以配合 git 钩子函数进行单元测试验证,如果不通过的话,那么就阻止 commit。
7. 项目结构
本次作业并没有对 node 的项目结构进行约束,只要大致符合提供的 C++ 或者 Java 的项目结构就行了,为了方便助教进行测试,直接采用 npm scripts的形式书写,不过可能需要自行修改脚本内输入输出文件的路径。经查阅也可以采用 process.argv 的形式获取 npm run xxx 的参数。
代码规范制定链接
设计与实现过程
- 功能文件下面设置
get与cal函数,并从模块导出,可以在各个地方使用。 - 由于需要过滤汉字,作为模块的统一需求,提取成一个文件
filterChinese - 正则表达式常量放入
regex.js文件方便维护以及防止书写错误。 - 总结来说总体结构如下,各文件内容助教可以检查。
1. 总体结构
221801107
│ .gitignore
│ codestyle.md
│ README.md
│
└─src
character.js
filterChinese.js
heap.js
index.txt
regex.js
row.js
word.js
wordCount.js
2. 字符处理
获取 filterChinese 函数,过滤后的长度即是字符个数。并从模块导出这两个函数
const filterChinese = require(".filterChinese");
// 获得字符数组
const getCharacter = (content) => filterChinese(content);
// 统计字符数量
const calCharacterCount = (content) => getCharacter(content).length;
3. 行处理
可以通过换行字符 \n 统计行数,通过 trim 函数判断是否为空检测空行。并导出相关函数。
// 统计行数
const calRowsCount = (content) => content.split(/\n/).length;
// 统计空行数
const calEmptyRowsCount = (content) => content.split(/\n/).filter((row) => row.trim() === "").length;
// 统计非空行数
const calNoEmptyRowsCount = (content) => calRowsCount(content) - calEmptyRowsCount(content);
4. 单词处理
File和file算一个单词,因此先进行小写转换,再用单词分割符分割,再过滤不是单词的例如fil这样的。- 获得单词的频率写了一个函数,由于是哈希映射,时间复杂度是O(n),而读入文档时间复杂度至少是O(n)级别的,没必要做更多优化
- 统计排序后的单词数也是直接排序后导出即可,这里为了适应于各个平台,导出为
{
word: "xxx",
count: 111,
}
的形式,方便做修改。
const { WORD_SPLIT_REGEX, WORD_REGEX } = require("./regex");
const filterChinese = require("./filterChinese");
// 获得所有单词,返回一个单词数组
const getWord = (content) => filterChinese(content)
.toLowerCase()
.split(WORD_SPLIT_REGEX)
.filter((word) => WORD_REGEX.test(word));
// 统计单词数量
const calWordCount = (content) => getWord(content).length;
// 统计单词频率
const getWordsFrequency = (content) => {
const wordArr = getWord(content);
const wordMap = new Map();
wordArr.forEach((word) => {
if (!wordMap.has(word)) {
wordMap.set(word, 0);
}
const count = wordMap.get(word);
wordMap.set(word, count + 1);
});
const ret = [];
wordMap.forEach((value, key) => {
ret.push({
word: key,
count: value,
});
});
return ret;
};
// 排序单词
const calSortedWordsFrequency = (content, count) => {
const arr = getWordsFrequency(content);
const sortArr = arr.sort((a, b) => {
if (a.count === b.count) {
return a.word < b.word ? -1 : 1;
}
return b.count - a.count;
});
if (typeof count === "undefined") {
return sortArr;
}
return sortArr.slice(0, count);
};
// 优化部分有堆排序单词
module.exports = {
getWord,
calWordCount,
getWordsFrequency,
calSortedWordsFrequency,
};
- 作业中还要求独到之处。
- 独到之处可能是代码比较精简,整体功能代码应该不超过150行,如果算上性能改进的堆排序,代码行数大概在 250行左右。
- 模块清晰,颗粒度小,各个函数都可以直接导出供测试。
性能改进
1. 采取整个文件读取的方式进行文件的读取。
JS 是单线程的,因此不可能在线程上做文章。采用整个文件直接读取,而不是分行读取的方式可以减少 IO 的中断次数,加快读文件。
2. 算法时间复杂度优化
大部分都是用正则表达式以及内部的函数,说实在的没什么好做性能改进的。原因是 split 以及 filter forEach 这些函数全都是 O(n) 级别的。由于需要遍历文档字符串,因此不可能有明显的改进。
不过对于 sort 函数是 O(nlogn) 倒是可以进行改进,因为只需要前十个排好序就可以了,那么可以采用堆排序,使时间复杂度降低至 O(nlogk) 这里 k 是 10, 也就是可以降低至 O(3n) 的级别。在单词数量非常多的情况下,会有一定的性能改进。由于 JS 默认没有堆的实现。因此手写了堆,在 heap.js 文件。
写完堆后采用堆排序
const calSortedWordsFrequencyByHeap = (content, count) => {
const arr = getWordsFrequency(content);
const heap = new Heap(count, (a, b) => {
if (a.count === b.count) {
return a.word < b.word ? -1 : 1;
}
return b.count - a.count;
});
arr.forEach((value) => {
heap.add(value);
});
const ret = [];
while (!heap.empty()) {
ret.push(heap.top());
heap.pop();
}
return ret.reverse();
};
另外进行单元测试
test("can calculate right sort by heap", () => {
const test1 = "huro huro lero";
expect(
calSortedWordsFrequencyByHeap(test1)
.map((item) => `${item.word}: ${item.count}\n`)
.join(""),
).toBe("huro: 2\nlero: 1\n");
const test2 = "windows95 windows2000 windows98";
expect(
calSortedWordsFrequencyByHeap(test2)
.map((item) => `${item.word}: ${item.count}\n`)
.join(""),
).toBe("windows2000: 1\nwindows95: 1\nwindows98: 1\n");
});
通过单元测试。
对于 1e7 个字符,经过上述改进运行时间有减少大约一半的变化,或许针对更大的文件会有更好的提升
使用 heap
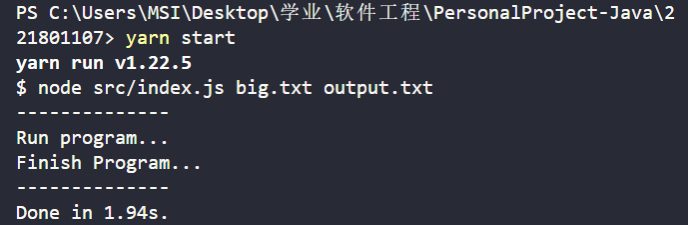
未使用 heap
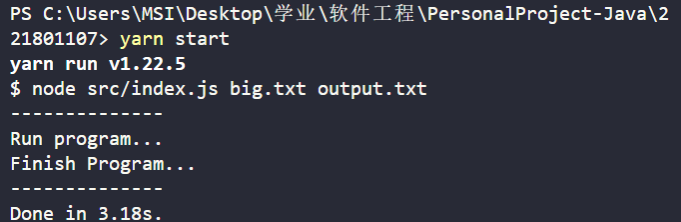
单元测试
1. 字符函数测试
- 测试是否忽略中文字符
- 测试是否计算 ASCII 字符
- 测试是否能够计算空格,制表符等特殊字符
test("can ignore chinese character", () => {
expect(calCharacterCount("嗨")).toBe(0);
});
test("can calculate ASCII character", () => {
expect(calCharacterCount("abc")).toBe(3);
});
test("can calculate ' ', '\t', '\n'", () => {
expect(calCharacterCount("\n\t ")).toBe(3);
});
2. 单词测试
- 测试是否能区分单词
- 测试是否能获得正确的单词数量
- 测试是否单词按照约定顺序进行排序
- 测试是否忽略了大写
test("can get right word", () => {
expect(calWordCount("abc123")).toBe(0);
expect(calWordCount("abc")).toBe(0);
expect(calWordCount("abcd123")).toBe(1);
expect(calWordCount("abcd")).toBe(1);
expect(calWordCount("abcde")).toBe(1);
expect(calWordCount("abcd##")).toBe(1);
});
test("can calculate right words count", () => {
expect(calWordCount("")).toBe(0);
expect(calWordCount("abc123 abcd123")).toBe(1);
expect(calWordCount("abcd123 abcd123")).toBe(2);
});
test("can calculate right sort", () => {
const test1 = "huro huro lero";
expect(
calSortedWordsFrequency(test1)
.map((item) => `${item.word}: ${item.count}\n`)
.join(""),
).toBe("huro: 2\nlero: 1\n");
const test2 = "windows95 windows2000 windows98";
expect(
calSortedWordsFrequency(test2)
.map((item) => `${item.word}: ${item.count}\n`)
.join(""),
).toBe("windows2000: 1\nwindows95: 1\nwindows98: 1\n");
});
test("can ignore uppercase", () => {
const test = "huro Huro lero";
expect(
calSortedWordsFrequency(test)
.map((item) => `${item.word}: ${item.count}\n`)
.join(""),
).toBe("huro: 2\nlero: 1\n");
});
3. 行测试
- 测试是否获得正确的行数
- 测试是否获得正确的空行数
- 测试是否获得正确的非空行数
test("can get right rows count", () => {
expect(calRowsCount("xxx")).toBe(1);
expect(calRowsCount("xxx\nxxx\n")).toBe(3);
});
test("can get right empty rows", () => {
expect(calEmptyRowsCount("xxx")).toBe(0);
expect(calEmptyRowsCount("xxx\nxxx\n")).toBe(1);
});
test("can get right no-empty rows", () => {
expect(calNoEmptyRowsCount("xxx\nxxx\n")).toBe(2);
});
4. 一键测试
之前可以直接运行 yarn test 进行一键测试,测试结果如下。没有下载 yarn 的也可以用 npm run test 进行测试。后来由于目录结构要求删掉了,但是保留了截图。可以配合git 钩子实现提交检测

5. 覆盖率测试

异常处理
由于函数进行了封装,内部调用不会出现传递参数异常的情况,只需要对用户的命令行输入做处理即可,对于程序内部的错误,告知用户是程序内部的错误,让其 File 作者。
1. 处理输入文件不存在的情况
if (!fs.existsSync(input)) {
console.error("Error: readFile not exist");
return;
}
2. 处理命令行参数无输入文件或输出文件的情况
const argvs = process.argv;
if (argvs.length < 4) {
console.error("Error: please input two files");
return;
}
3. 其他错误可以打印 ex.message 进行查看
try {
// ...
} catch (ex) {
console.error(ex.message, "please file xxx");
}
心路历程和收获
- 学会怎么配置
eslint - 知道
webpack打包的项目应该用于brower - 知道
.eslintignore只能在工作区根目录生效,不过可以通过settings配置使其在其他路径下也能生效。 - 知道
webpack v5相比webpack v4少了node polyfill优化性能。 - 了解命令行程序如何传参
- 了解白盒测试是什么
- 了解
git rebase和git merge的区别

 浙公网安备 33010602011771号
浙公网安备 33010602011771号