AI start
训练模型来检测图像噪声区域通常需要以下步骤:
- 数据准备:收集包含噪声和无噪声的图像样本作为训练数据。可以使用现有的带有噪声和无噪声标签的图像数据集,或者手动创建标签来标记图像中的噪声区域。
- 数据预处理:对图像进行预处理,以便将其转换为适合模型训练的格式。这可能包括调整图像大小、归一化像素值、增加数据增强等操作。
- 构建模型:选择适合的深度学习模型架构,如卷积神经网络(CNN)。根据问题的复杂性和数据集的规模,可以选择使用已经存在的预训练模型或自定义模型。
- 模型训练:使用准备好的训练数据集,将数据输入到模型中进行训练。通过反向传播算法和优化器来调整模型的权重和参数,使其能够准确地检测图像中的噪声区域。
- 模型评估:使用测试数据集对训练好的模型进行评估,计算模型的准确率、召回率、F1分数等指标,以评估模型的性能。
- 模型调优:根据评估结果,可以对模型进行调优,如调整模型架构、调整超参数、增加训练数据等,以提高模型的性能。
- 模型应用:将训练好的模型应用于新的图像数据,进行噪声区域检测。
需要注意的是,以上步骤仅为一般性指导,具体的学习过程可能因问题的复杂性、数据集的特点和使用的模型而有所不同。在实际应用中,可能需要进行多次迭代和调试,以获得更好的模型性能。
在AI训练模型中,常用的术语包括:
- 数据集(Dataset):用于训练和评估模型的数据集合。数据集可以包含输入特征和相应的标签或目标值。
- 样本(Sample):数据集中的单个数据点,包含输入特征和相应的标签或目标值。
- 特征(Feature):用于描述样本的输入变量或属性。在机器学习中,特征通常以向量或矩阵的形式表示。
- 标签(Label):样本的目标值或输出变量,用于指导模型进行预测或分类。
- 训练集(Training Set):用于训练模型的数据子集,模型通过学习训练集中的样本来进行参数调整和优化。
- 验证集(Validation Set):用于调整模型超参数、选择模型和进行模型选择的数据子集。验证集通常用于评估模型在训练过程中的性能。
- 测试集(Test Set):用于评估模型在最终阶段的泛化能力和性能的数据子集。测试集应该是模型之前未见过的数据,以验证模型的真实性能。
- 损失函数(Loss Function):用于衡量模型预测结果与真实标签之间的差异或误差。损失函数的值越小,表示模型的预测结果越接近真实标签。
- 优化算法(Optimization Algorithm):用于更新模型参数以最小化损失函数的算法。常见的优化算法包括梯度下降法(Gradient Descent)和其变种。
- 过拟合(Overfitting):指模型在训练集上表现良好,但在新数据上表现较差的现象。过拟合可能是由于模型过于复杂或训练数据不足引起的。
- 正则化(Regularization):一种用于减少模型过拟合的技术,通过在损失函数中引入正则化项来限制模型参数的大小。
- 批量(Batch):在训练过程中,将一组样本同时输入模型进行前向传播和反向传播的操作。批量大小决定了每次参数更新的样本数量。
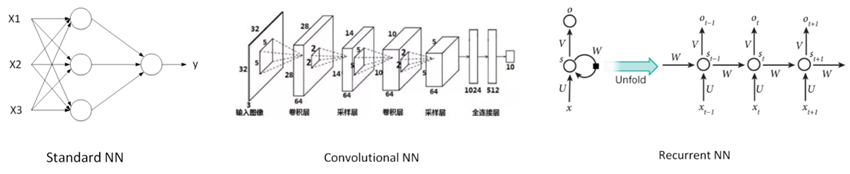
一般的监督式学习(房价预测和线上广告问题),我们只要使用标准的神经网络模型就可以了。而对于图像识别处理问题,我们则要使用卷积神经网络(Convolution Neural Network),即CNN。而对于处理类似语音这样的序列信号时,则要使用循环神经网络(Recurrent Neural Network),即RNN。还有其它的例如自动驾驶这样的复杂问题则需要更加复杂的混合神经网络模型。
——————————
——————
数据类型一般分为两种:Structured Data和Unstructured Data。
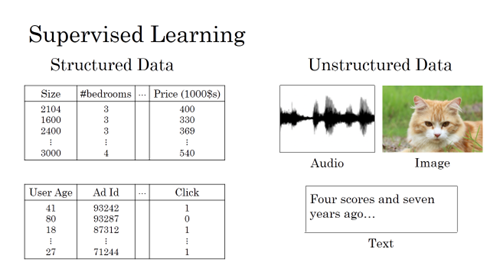
Structured Data通常指的是有实际意义的数据。例如房价预测中的size,#bedrooms,price等;例如在线广告中的User Age,Ad ID等。这些数据都具有实际的物理意义,比较容易理解。而Unstructured Data通常指的是比较抽象的数据,例如Audio,Image或者Text。
构建一个深度学习的流程是首先产生Idea,然后将Idea转化为Code,最后进行Experiment。接着根据结果修改Idea,继续这种Idea->Code->Experiment的循环,直到最终训练得到表现不错的深度学习网络模型。如果计算速度越快,每一步骤耗时越少,那么上述循环越能高效进行。
Logistic Regression Cost Function
逻辑回归中,w和b都是未知参数,需要反复训练优化得到。因此,我们需要定义一个cost function,包含了参数w和b。通过优化cost function,当cost function取值最小时,得到对应的w和b。
先从单个样本出发,我们希望该样本的预测值y^与真实值越相似越好。我们把单个样本的cost function用Loss function来表示.
Loss function的原则和目的就是要衡量预测输出y^与真实样本输出y的接近程度.
python和pytorch的初步学习需要了解的知识;
- Python编程语言:熟悉Python的基本语法、数据类型、控制流程等。了解Python的常用库,如NumPy、Pandas等。
- 深度学习基础知识:了解深度学习的基本概念,包括神经网络、损失函数、优化算法等。掌握常用的深度学习模型,如卷积神经网络(CNN)、循环神经网络(RNN)等。
- PyTorch库:熟悉PyTorch的基本概念和使用方法,包括张量操作、模型定义、模型训练和推理等。了解PyTorch提供的各种工具和函数,如数据加载、优化器、损失函数等。
- 数据预处理:了解数据预处理的常用方法,如数据清洗、标准化、数据增强等。掌握如何使用PyTorch进行数据加载和预处理。
- 模型训练和调优:了解模型训练的基本流程,包括数据划分、模型训练、模型评估等。了解常用的模型调优方法,如学习率调整、正则化、批归一化等。
- GPU加速:了解如何使用GPU进行深度学习模型的加速。熟悉PyTorch中GPU相关的操作和设置。






【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)