数据挖掘--K-means
K-Means方法是MacQueen1967年提出的。给定一个数据集合X和一个整数K(n),K-Means方法是将X分成K个聚类并使得在每个聚类中所有值与该聚类中心距离的总和最小。
K-Means聚类方法分为以下几步:
[1] 给K个cluster选择最初的中心点,称为K个Means。
[2] 计算每个对象和每个中心点之间的距离。
[3] 把每个对象分配给距它最近的中心点做属的cluster。
[4] 重新计算每个cluster的中心点。
[5] 重复2,3,4步,直到算法收敛。
以下几张图动态展示了这几个步骤:
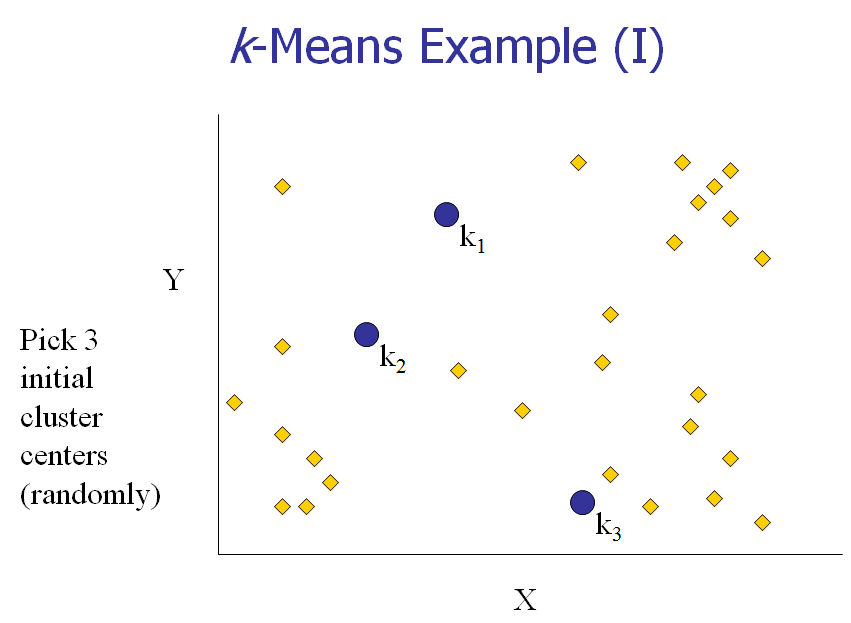
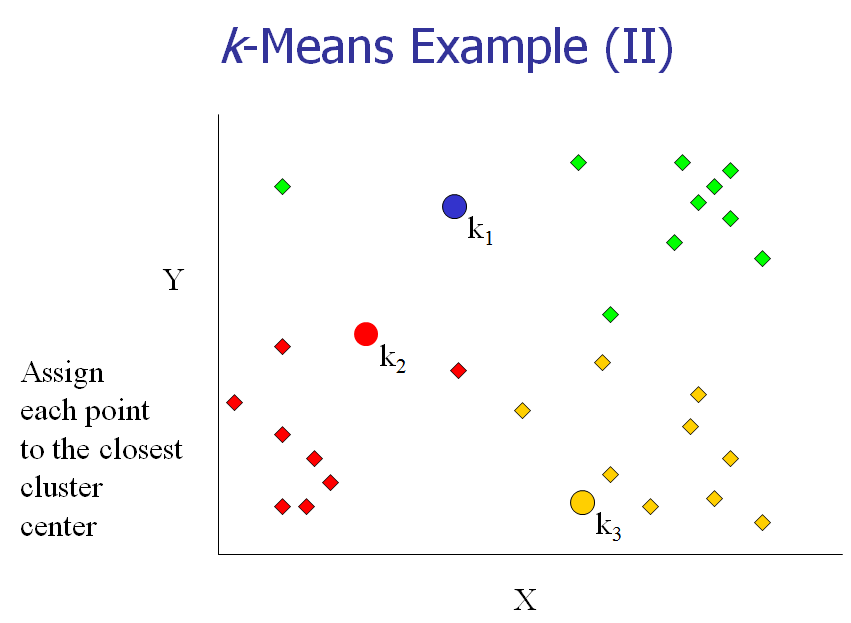


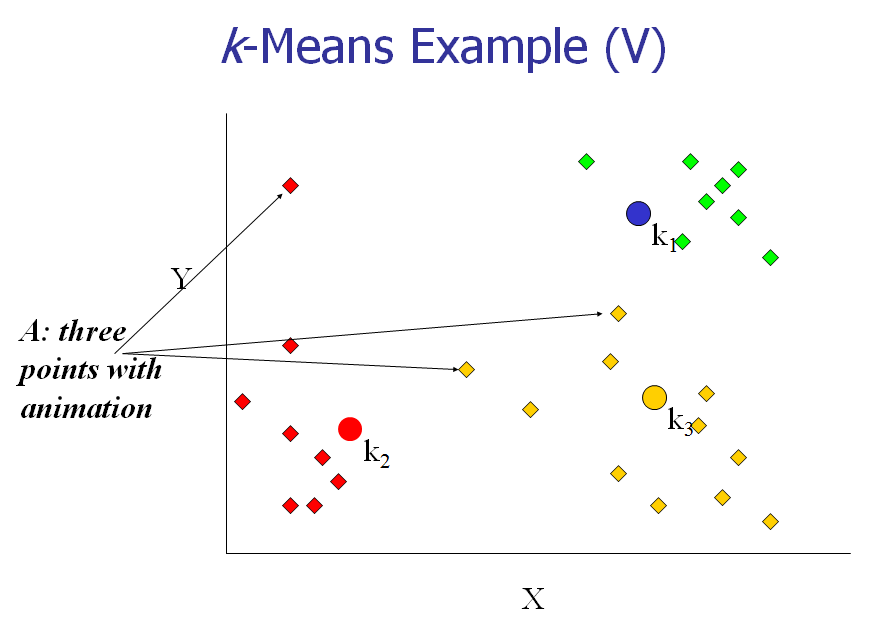


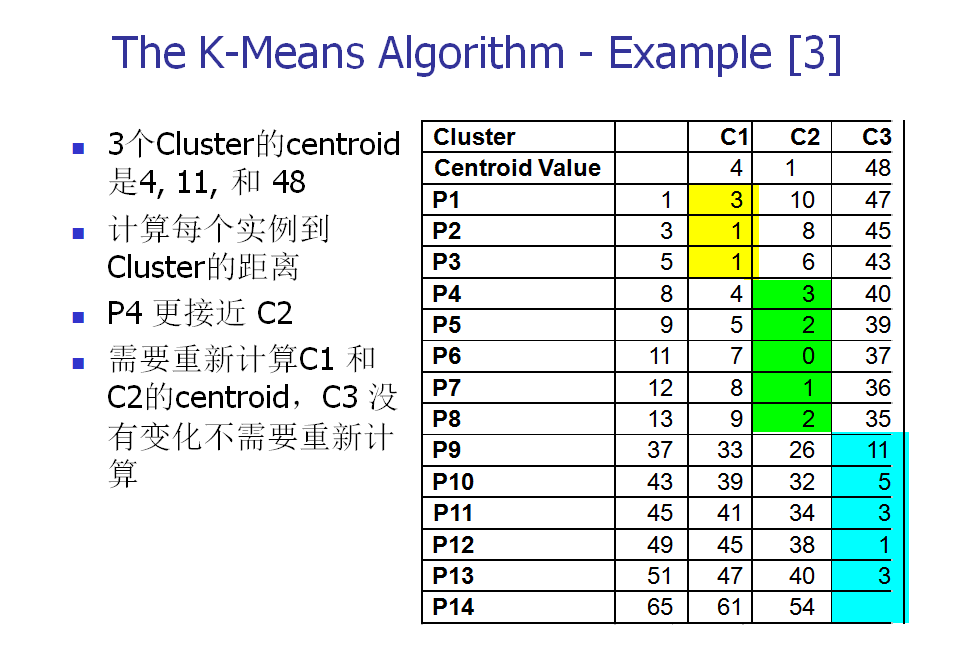
下面,我们以一个具体的例子来说明一下K-means算法的实现。
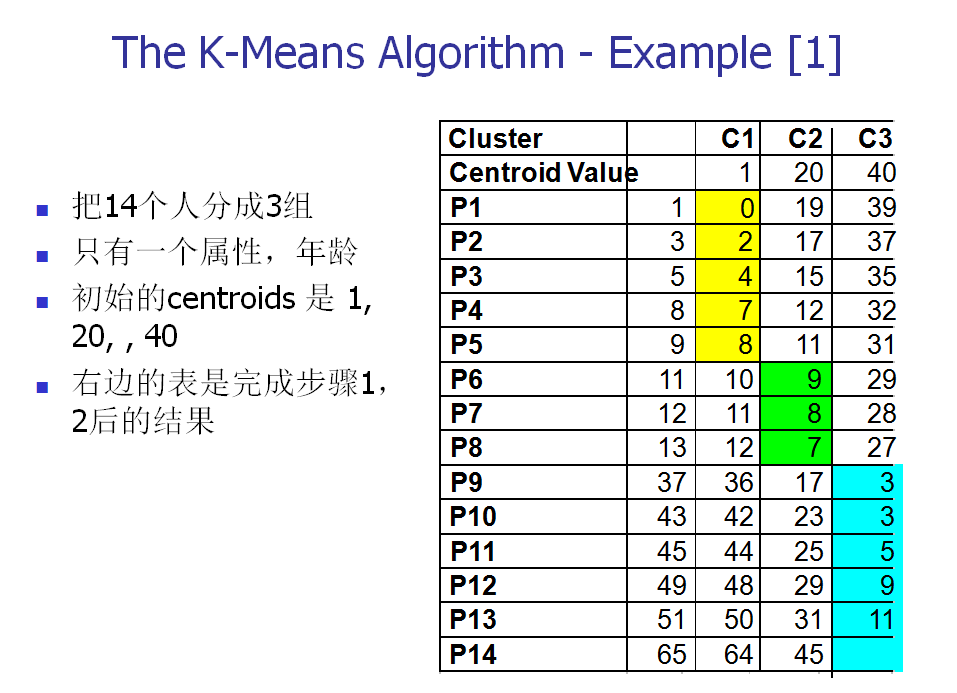


K-means算法的优缺点:
优点:
(1)对于处理大数据量具有可扩充性和高效率。算法的复杂度是O(tkn),其中n是对象的个数,k是cluster的个数,t是循环的次数,通常k,t<<n。
(2)可以实现局部最优化,如果要找全局最优,可以用退火算法或者遗传算法
缺点:
(1)Cluster的个数必须事先确定,在有些应用中,事先并不知道cluster的个数。
(2)K个中心点必须事先预定,而对于有些字符属性,很难确定中心点。
(3)不能处理噪音数据。
(4)不能处理有些分布的数据(例如凹形)
K-Means方法的变种
(1) K-Modes :处理分类属性
(2) K-Prototypes:处理分类和数值属性
(3) K-Medoids
它们与K-Means方法的主要区别在于:
(1)最初的K个中心点的选择不同。
(2)距离的计算方式不同。
(3)计算cluster的中心点的策略不同。
对未知的世界充满好奇~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号