mysql 8 索引
一 索引的概念
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。
数据库查询是数据库的最主要功能之一。我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。最基本的查询算法当然是顺序查找(linear search),这种复杂度为O(n)的算法在数据量很大时显然是糟糕的,好在计算机科学的发展提供了很多更优秀的查找算法,例如二分查找(binary search)、二叉树查找(binary tree search)等。
如果稍微分析一下会发现,每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织),所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引
索引本质上是独立的索引文件,里面按照特定的顺序(一般采用B+树结构)记录了数据字段(A,B)和实际数据存储位置 在没有索引的时候,如果要查询某个字段=值,则需要遍历所有实际数据,然后和字段对比,也就是全表扫描 然而在拥有索引的时候,则不需要查询原始数据,只需要查询索引文件,分别查询出A和B匹配的记录,然后计算他们的交集,最后再根据索引中记录的实际位置去读取数据,避免了全表扫描 。
二 索引分类
1、普通索引
最基本的索引,它没有任何限制,用于加速查询。
创建方法:


a. 建表的时候一起创建 CREATE TABLE mytable ( name VARCHAR(32) , INDEX index_mytable_name (name) ); b. 建表后,直接创建索引 CREATE INDEX index_mytable_name ON mytable(name); c. 修改表结构 ALTER TABLE mytable ADD INDEX index_mytable_name (name); 注:如果是字符串字段,还可以指定索引的长度,在列命令后面加上索引长度就可以了(例如:name(11))
2、唯一索引
索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
创建方法:
a. 建表的时候一起创建 CREATE TABLE mytable ( `name` VARCHAR(32) , UNIQUE index_unique_mytable_name (`name`) ); b. 建表后,直接创建索引 CREATE UNIQUE INDEX index_mytable_name ON mytable(name); c. 修改表结构 ALTER TABLE mytable ADD UNIQUE INDEX index_mytable_name (name); 注:如果是字符串字段,还可以指定索引的长度,在列命令后面加上索引长度就可以了(例如:name(11))
3、主键索引
是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键索引。
创建方法:
a. 建表的时候一起创建 CREATE TABLE mytable ( `id` int(11) NOT NULL AUTO_INCREMENT , `name` VARCHAR(32) , PRIMARY KEY (`id`) ); b. 修改表结构 ALTER TABLE test.t1 ADD CONSTRAINT t1_pk PRIMARY KEY (id); 注:如果是字符串字段,还可以指定索引的长度,在列命令后面加上索引长度就可以了(例如:name(11))
4、组合(复合)索引
指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合。
创建方法:
a. 建表的时候一起创建 CREATE TABLE mytable ( `id` int(11) , `name` VARCHAR(32) , INDEX index_mytable_id_name (`id`,`name`) ); b. 建表后,直接创建索引 CREATE INDEX index_mytable_id_name ON mytable(id,name); c. 修改表结构 ALTER TABLE mytable ADD INDEX index_mytable_id_name (id,name);
查看索引
show index from tablename
删除索引
drop index index_name on table_name;
5、全文索引
主要用来查找文本中的关键字,而不是直接与索引中的值相比较。
fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。
fulltext索引配合match against操作使用,而不是一般的where语句加like。
它可以在create table,alter table ,create index使用,不过目前只有char、varchar,text 列上可以创建全文索引。
创建方法:
a. 建表的时候一起创建
CREATE TABLE `article` ( `id` int(11) NOT NULL AUTO_INCREMENT , `title` char(250) NOT NULL , `contents` text NULL , `create_at` int(10) NULL DEFAULT NULL , PRIMARY KEY (`id`), FULLTEXT (contents) ); b. 建表后,直接创建索引 CREATE FULLTEXT INDEX index_article_contents ON article(contents); c. 修改表结构 ALTER TABLE article ADD FULLTEXT INDEX index_article_contents (contents);
如何使用全文索引进行搜索?
MySQL的全文索引查询有多种模式,我们一般经常使用两种.
1. 自然语言搜索
就是普通的包含关键词的搜索.
2. BOOLEAN MODE
这个模式和lucene中的BooleanQuery很像,可以通过一些操作符,来指定搜索词在结果中的包含情况.比如 +嘻哈表示必须包含嘻哈, -嘻哈表示必须不包含,默认为误操作符,代表可以出现可以不出现,但是出现时在查询结果集中的排名较高一些.也就是该结果和搜索词的相关性高一些.
具体包含的所有操作符可以通过MySQL查询来查看:
mysql> show variables like '%ft_boolean_syntax%';
+-------------------+----------------+
| Variable_name | Value |
+-------------------+----------------+
| ft_boolean_syntax | + -><()~*:""&| |
+-------------------+----------------+
使用自然语言搜索如下:
mysql> SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('精神' IN NATURAL LANGUAGE MODE);
+----+-----------------+-------------------------+
| id | title | body |
+----+-----------------+-------------------------+
| 1 | 弘扬正能量 | 贯彻党的18大精神 |
+----+-----------------+-------------------------+mysql> SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('精神');
+----+-----------------+-------------------------+
| id | title | body |
+----+-----------------+-------------------------+
| 1 | 弘扬正能量 | 贯彻党的18大精神 |
+----+-----------------+-------------------------+可以看到,搜索结果命中了一条,且在不指定搜索模式的情况下,默认模式为自然语言搜索.
使用boolean搜索如下:
mysql> SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('+精神' IN BOOLEAN MODE);
+----+-----------------+-------------------------+
| id | title | body |
+----+-----------------+-------------------------+
| 1 | 弘扬正能量 | 贯彻党的18大精神 |
+----+-----------------+-------------------------+
mysql> SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('+精神 -贯彻' IN BOOLEAN MODE);
当搜索必须命中精神时,命中了一条数据,当在加上不能包含贯彻的时候,无命中结果.
适用于数据量比较小的,且对搜索结果的精确度和可定制化程度要求不高的话,否则还是用使用lucene,es相关的那一套全文搜索工具包来做
6 聚集索引和非聚集索引
聚集索引:
每个InnoDB表都有一个称之为聚簇索引(clustered index)的特殊索引,存储记录行数据,是一种数据存储的方式
索引中键值的逻辑顺序决定了表中相应行的物理顺序(索引中的数据物理存放地址和索引的顺序是一致的)
可以这么理解:只要是索引是连续的,那么数据在存储介质上的存储位置也是连续的。
比方说:想要到字典上查找一个字,我们可以根据字典前面的拼音找到该字,注意拼音的排列时有顺序的。
打个比方:当我们想要找“啊”这个字,然后又想找“不”这个字,根据拼音来看“b”一定在”a“的后面。
聚集索引就像我们根据拼音的顺序查字典一样,可以大大的提高效率。在经常搜索一定范围的值时,通过索引找到第一条数据,根据物理地址连续存储的特点,然后检索相邻的数据,直到到达条件截至项。
innoDB会使用聚集索引来优化查询和DML(增,删,改) 每个表总会有一个聚集索引
l 当在表上定义一个主键时, InnoDB把它当聚簇索引用。为每个表都定义一个主键,如果没有逻辑上唯一且NOT-NULL的列,则添加一个自动增长(auto-increment)的列
2 如果没为表定义主键,mysql定位所有索引列都为NOT NULL的第一个唯一索引,并把它当聚簇索引使用。
3 如果表没有主键或合适的唯一索引,InnoDB会在某个包含row ID值的合成列上生成一个隐藏的聚簇索引。记录行按表中InnoDB赋予行的row ID排序。row ID为一6字节域,
当有新行被插入时会自动增加,所以,按row ID排序的行物理上为按插入顺序排序。
InnoDB引擎会为每张表都加一个聚集索引,聚集索引就是按照每张表的主键(根据上面1,2,3点总会有一个真实主键或者代替主键的东西)构造一颗B+树,同时叶子节点中存放的即为整张表的记录数据。
如下图 4,7,10 代表非叶子节点,存储的是存放键值和指向数据页的指针
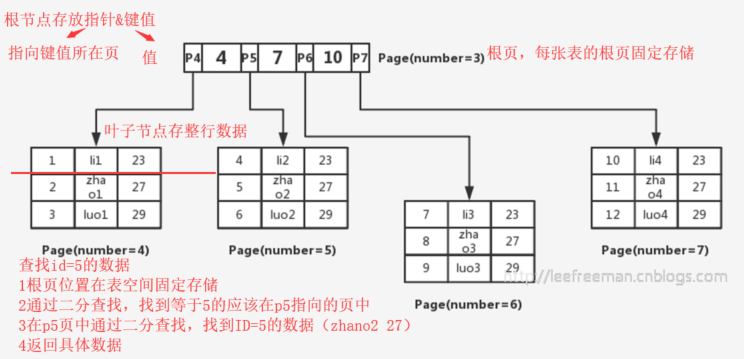
InnoDB的最小存储数据单元是页(大小为16KB), B+tree的叶子节点存储的数据,最小单位是页 , 在聚簇索引中,根据主键遍历B+tree树,找到非叶子节点上的指针(指向数据页,然后再对页数据进行2分查找,找到需要的数据),可以是1页,或者N页
节点可以存储键值和指针,也可以存放数据: 在B+树中叶子节点存放数据,非叶子节点存放键值+指针。
非聚集索引:
也叫二级索引。除了聚簇索引外的索引都叫二级索引。 二级索引的叶子节点中保存的不是指向行的物理指针,而是行的主键值。当通过二级索引查找行,存储引擎需要在二级索引中找到相应的叶子节点,获得行的主键值,然后使用主键去聚簇索引中查找数据行,这需要两次B-Tree查找。
索引的逻辑顺序与磁盘上的物理存储顺序不同。非聚集索引的键值在逻辑上也是连续的,但是表中的数据在存储介质上的物理顺序是不一致的,即记录的逻辑顺序和实际存储的物理顺序没有任何联系。索引的记录节点有一个数据指针指向真正的数据存储位置。
非聚集索引就像根据偏旁部首查字典一样,字典前面的目录在逻辑上也是连续的,但是查两个偏旁在目录上挨着的字时,字典中的字却很不可能是挨着的。
问题? b+tree索引中,叶子节点可以存储什么?
答: B+tree的叶子节点可以存储可能存储的是整行数据(聚集索引),也有可能是主键的值(非聚集索引)
问题: 那么,聚簇索引和非聚簇索引,在查询数据的时候有区别吗?
答 : 聚簇索引查询会更快
因为主键索引树的叶子节点直接就是我们要查询的整行数据了。而非主键索引的叶子节点是主键的值,查到主键的值以后,还需要再通过主键的值再去聚集索引里进行一次查询
问题: 刚刚你提到主键索引查询只会查一次,而非主键索引需要回表查询多次。是所有情况都是这样的吗?非主键索引一定会查询多次吗?
通过覆盖索引也可以只查询一次,具体解释看另一篇博客对覆盖索引的介绍
7 hash索引和B+tree索引的区别
看本人另一篇博客
https://www.cnblogs.com/hup666/p/13388570.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号