MySQL基础(非常全)
MySQL基础
一、MySQL概述
1、什么是数据库 ?
答:数据的仓库,如:在ATM的示例中我们创建了一个 db 目录,称其为数据库
2、什么是 MySQL、Oracle、SQLite、Access、MS SQL Server等 ?
答:他们均是一个软件,都有两个主要的功能:
- a. 将数据保存到文件或内存
- b. 接收特定的命令,然后对文件进行相应的操作
3、什么是SQL ?
答:MySQL等软件可以接受命令,并做出相应的操作,由于命令中可以包含删除文件、获取文件内容等众多操作,对于编写的命令就是是SQL语句。
二、MySQL安装
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下公司。MySQL 最流行的关系型数据库管理系统,在 WEB 应用方面MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。
想要使用MySQL来存储并操作数据,则需要做几件事情:
a. 安装MySQL服务端
b. 安装MySQL客户端
b. 【客户端】连接【服务端】
c. 【客户端】发送命令给【服务端MySQL】服务的接受命令并执行相应操作(增删改查等)
下载
http://dev.mysql.com/downloads/mysql/
安装
windows:
http://jingyan.baidu.com/article/f3ad7d0ffc061a09c3345bf0.html
linux:
yum install mysql-server
mac:
一直点下一步
客户端连接
连接:
1、mysql管理人默认为root,没有设置密码则直接登录
mysql -h host -u root -p 不用输入密码按回车自动进入
2、如果想设置mysql密码
mysqladmin -u root password 123456
3、如果你的root现在有密码了(123456),那么修改密码为abcdef的命令是:
mysqladmin -u root -p password abcdef
退出:
QUIT 或者 Control+D
三、数据库基础
分为两大部分:
1、数据库和表的创建;
2、数据库和表内容的操作
数据库操作-思路图
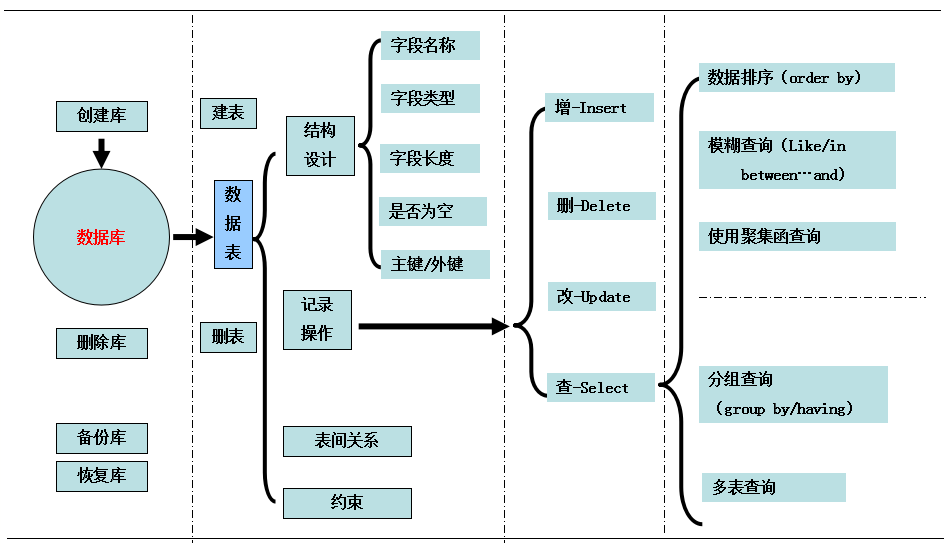
1、数据库和表的创建
(一)数据库的创建
1.1、显示数据库
1 SHOW DATABASES;
默认数据库:
mysql - 用户权限相关数据
test - 用于用户测试数据
information_schema - MySQL本身架构相关数据
1.2、创建数据库
# utf-8 CREATE DATABASE 数据库名称 DEFAULT CHARSET utf8 COLLATE utf8_general_ci; # gbk CREATE DATABASE 数据库名称 DEFAULT CHARACTER SET gbk COLLATE gbk_chinese_ci;
1.3、打开数据库
USE db_name;
注:每次使用数据库必须打开相应数据库
显示当前使用的数据库中所有表:SHOW TABLES;
1.4、用户管理
用户设置:
创建用户
create user '用户名'@'IP地址' identified by '密码';
删除用户
drop user '用户名'@'IP地址';
修改用户
rename user '用户名'@'IP地址'; to '新用户名'@'IP地址';;
修改密码
set password for '用户名'@'IP地址' = Password('新密码')
PS:用户权限相关数据保存在mysql数据库的user表中,所以也可以直接对其进行操作(不建议)
用户权限设置:
show grants for '用户'@'IP地址' -- 查看权限 grant 权限 on 数据库.表 to '用户'@'IP地址' -- 授权 revoke 权限 on 数据库.表 from '用户'@'IP地址' -- 取消权限
 对于权限设置
对于权限设置
all privileges 除grant外的所有权限
select 仅查权限
select,insert 查和插入权限
...
usage 无访问权限
alter 使用alter table
alter routine 使用alter procedure和drop procedure
create 使用create table
create routine 使用create procedure
create temporary tables 使用create temporary tables
create user 使用create user、drop user、rename user和revoke all privileges
create view 使用create view
delete 使用delete
drop 使用drop table
execute 使用call和存储过程
file 使用select into outfile 和 load data infile
grant option 使用grant 和 revoke
index 使用index
insert 使用insert
lock tables 使用lock table
process 使用show full processlist
select 使用select
show databases 使用show databases
show view 使用show view
update 使用update
reload 使用flush
shutdown 使用mysqladmin shutdown(关闭MySQL)
super 使用change master、kill、logs、purge、master和set global。还允许mysqladmin调试登陆
replication client 服务器位置的访问
replication slave 由复制从属使用

all privileges 除grant外的所有权限
select 仅查权限
select,insert 查和插入权限
...
usage 无访问权限
alter 使用alter table
alter routine 使用alter procedure和drop procedure
create 使用create table
create routine 使用create procedure
create temporary tables 使用create temporary tables
create user 使用create user、drop user、rename user和revoke all privileges
create view 使用create view
delete 使用delete
drop 使用drop table
execute 使用call和存储过程
file 使用select into outfile 和 load data infile
grant option 使用grant 和 revoke
index 使用index
insert 使用insert
lock tables 使用lock table
process 使用show full processlist
select 使用select
show databases 使用show databases
show view 使用show view
update 使用update
reload 使用flush
shutdown 使用mysqladmin shutdown(关闭MySQL)
super 使用change master、kill、logs、purge、master和set global。还允许mysqladmin调试登陆
replication client 服务器位置的访问
replication slave 由复制从属使用
对于数据库名的解释
对于目标数据库以及内部其他:
数据库名.* 数据库中的所有
数据库名.表 指定数据库中的某张表
数据库名.存储过程 指定数据库中的存储过程
*.* 所有数据库
对于目标数据库以及内部其他:
数据库名.* 数据库中的所有
数据库名.表 指定数据库中的某张表
数据库名.存储过程 指定数据库中的存储过程
*.* 所有数据库
对于ip地址的访问用户名@IP地址 用户只能在改IP下才能访问 用户名@192.168.1.% 用户只能在改IP段下才能访问(通配符%表示任意) 用户名@% 用户可以再任意IP下访问(默认IP地址为%)
用户名@IP地址 用户只能在改IP下才能访问
用户名@192.168.1.% 用户只能在改IP段下才能访问(通配符%表示任意)
用户名@% 用户可以再任意IP下访问(默认IP地址为%)
实际例子grant all privileges on db1.tb1 TO '用户名'@'IP' grant select on db1.* TO '用户名'@'IP' grant select,insert on *.* TO '用户名'@'IP' revoke select on db1.tb1 from '用户名'@'IP'
grant all privileges on db1.tb1 TO '用户名'@'IP'
grant select on db1.* TO '用户名'@'IP'
grant select,insert on *.* TO '用户名'@'IP'
revoke select on db1.tb1 from '用户名'@'IP'
1.4、备份库和恢复库
备份库:
MySQL备份和还原,都是利用mysqldump、mysql和source命令来完成。
1.在Windows下MySQL的备份与还原
备份 1、开始菜单 | 运行 | cmd |利用“cd /Program Files/MySQL/MySQL Server 5.0/bin”命令进入bin文件夹 2、利用“mysqldump -u 用户名 -p databasename >exportfilename”导出数据库到文件,如mysqldump -u root -p voice>voice.sql,然后输入密码即可开始导出。 还原 1、进入MySQL Command Line Client,输入密码,进入到“mysql>”。 2、输入命令"show databases;",回车,看看有些什么数据库;建立你要还原的数据库,输入"create database voice;",回车。 3、切换到刚建立的数据库,输入"use voice;",回车;导入数据,输入"source voice.sql;",回车,开始导入,再次出现"mysql>"并且没有提示错误即还原成功。
2、在linux下MySQL的备份与还原
2.1 备份(利用命令mysqldump进行备份) [root@localhost mysql]# mysqldump -u root -p voice>voice.sql,输入密码即可。 2.2 还原 方法一: [root@localhost ~]# mysql -u root -p 回车,输入密码,进入MySQL的控制台"mysql>",同1.2还原。 方法二: [root@localhost mysql]# mysql -u root -p voice<voice.sql,输入密码即可。
3、更多备份及还原命令
更多备份
备份:
1.备份全部数据库的数据和结构
mysqldump -uroot -p123456 -A >F:\all.sql
2.备份全部数据库的结构(加 -d 参数)
mysqldump -uroot -p123456 -A -d>F:\all_struct.sql
3.备份全部数据库的数据(加 -t 参数)
mysqldump -uroot -p123456 -A -t>F:\all_data.sql
4.备份单个数据库的数据和结构(,数据库名mydb)
mysqldump -uroot -p123456 mydb>F:\mydb.sql
5.备份单个数据库的结构
mysqldump -uroot -p123456 mydb -d>F:\mydb.sql
6.备份单个数据库的数据
mysqldump -uroot -p123456 mydb -t>F:\mydb.sql
7.备份多个表的数据和结构(数据,结构的单独备份方法与上同)
mysqldump -uroot -p123456 mydb t1 t2 >f:\multables.sql
8.一次备份多个数据库
mysqldump -uroot -p123456 --databases db1 db2 >f:\muldbs.sql
还原:
还原部分分(1)mysql命令行source方法 和 (2)系统命令行方法
1.还原全部数据库:
(1) mysql命令行:mysql>source f:\all.sql
(2) 系统命令行: mysql -uroot -p123456 <f:\all.sql
2.还原单个数据库(需指定数据库)
(1) mysql>use mydb
mysql>source f:\mydb.sql
(2) mysql -uroot -p123456 mydb <f:\mydb.sql
3.还原单个数据库的多个表(需指定数据库)
(1) mysql>use mydb
mysql>source f:\multables.sql
(2) mysql -uroot -p123456 mydb <f:\multables.sql
4.还原多个数据库,(一个备份文件里有多个数据库的备份,此时不需要指定数据库)
(1) mysql命令行:mysql>source f:\muldbs.sql
(2) 系统命令行: mysql -uroot -p123456 <f:\muldbs.sql
备份: 1.备份全部数据库的数据和结构 mysqldump -uroot -p123456 -A >F:\all.sql 2.备份全部数据库的结构(加 -d 参数) mysqldump -uroot -p123456 -A -d>F:\all_struct.sql 3.备份全部数据库的数据(加 -t 参数) mysqldump -uroot -p123456 -A -t>F:\all_data.sql 4.备份单个数据库的数据和结构(,数据库名mydb) mysqldump -uroot -p123456 mydb>F:\mydb.sql 5.备份单个数据库的结构 mysqldump -uroot -p123456 mydb -d>F:\mydb.sql 6.备份单个数据库的数据 mysqldump -uroot -p123456 mydb -t>F:\mydb.sql 7.备份多个表的数据和结构(数据,结构的单独备份方法与上同) mysqldump -uroot -p123456 mydb t1 t2 >f:\multables.sql 8.一次备份多个数据库 mysqldump -uroot -p123456 --databases db1 db2 >f:\muldbs.sql 还原: 还原部分分(1)mysql命令行source方法 和 (2)系统命令行方法 1.还原全部数据库: (1) mysql命令行:mysql>source f:\all.sql (2) 系统命令行: mysql -uroot -p123456 <f:\all.sql 2.还原单个数据库(需指定数据库) (1) mysql>use mydb mysql>source f:\mydb.sql (2) mysql -uroot -p123456 mydb <f:\mydb.sql 3.还原单个数据库的多个表(需指定数据库) (1) mysql>use mydb mysql>source f:\multables.sql (2) mysql -uroot -p123456 mydb <f:\multables.sql 4.还原多个数据库,(一个备份文件里有多个数据库的备份,此时不需要指定数据库) (1) mysql命令行:mysql>source f:\muldbs.sql (2) 系统命令行: mysql -uroot -p123456 <f:\muldbs.sql
更多备份知识:
http://www.jb51.net/article/41570.htm
(二)数据表的创建
1.1、显示数据表
show tables;
1.2、创建数据表
create table if not EXISTS student( id int auto_increment primary key, #主键约束 +自增 stuName varchar(20) not null , #非空约束 gender char(1) , seat int unique, #唯一约束 age int default 18 #默认约束,默认18 )ENGINE=InnoDB DEFAULT CHARSET=utf8
主键与外键关系(非常重要)
http://www.cnblogs.com/programmer-tlh/p/5782451.html
1.3删除表
drop table 表名
1.4、清空表
delete from 表名 truncate table 表名
1.5、复制表
#1.仅仅复制表的结构 #只复制表结构,里面没数据 create table 新表名 like 旧表名 #2.复制表结构+数据 create table 新表名 select * from 旧表名 #3.只复制部分数据和部分列 create table 新表名 select 列1,列2... from 旧表 where 条件 #4.只复制部分结构,但是不需要数据 create table 新表名 select 列1,列2... from 旧表 where 1=2;
1.6、基本数据类型
MySQL的数据类型大致分为:数值、时间和字符串
1. bit[(M)] 二进制位(101001),m表示二进制位的长度(1-64),默认m=1 2. tinyint[(m)] [unsigned] [zerofill] 小整数,数据类型用于保存一些范围的整数数值范围: 特别的: MySQL中无布尔值,使用tinyint(1)构造。 3. int[(m)][unsigned][zerofill] 整数,数据类型用于保存一些范围的整数数值范围: 特别的:整数类型中的m仅用于显示,对存储范围无限制。例如: int(5),当插入数据2时,select 时数据显示为: 00002 4. bigint[(m)][unsigned][zerofill] 大整数,数据类型用于保存一些范围的整数数值范围: 5. decimal[(m[,d])] [unsigned] [zerofill] 准确的小数值,m是数字总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。 特别的:对于精确数值计算时需要用此类型 decaimal能够存储精确值的原因在于其内部按照字符串存储。 6. FLOAT[(M,D)] [UNSIGNED] [ZEROFILL] 单精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。 7. DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL] 双精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。 8. char (m) char数据类型用于表示固定长度的字符串,可以包含最多达255个字符。其中m代表字符串的长度。 PS: 即使数据小于m长度,也会占用m长度 9.varchar(m) varchars数据类型用于变长的字符串,可以包含最多达255个字符。其中m代表该数据类型所允许保存的字符串的最大长度,只要长度小于该最大值的字符串都可以被保存在该数据类型中。 注:虽然varchar使用起来较为灵活,但是从整个系统的性能角度来说,char数据类型的处理速度更快,有时甚至可以超出varchar处理速度的50%。因此,用户在设计数据库时应当综合考虑各方面的因素,以求达到最佳的平衡 10. text text数据类型用于保存变长的大字符串,可以组多到65535 (2**16 − 1)个字符。 #时间类型 11. DATE
#只有日期没有时间 YYYY-MM-DD(1000-01-01/9999-12-31) 12. TIME
#中有时间没有日期 HH:MM:SS('-838:59:59'/'838:59:59') 13. YEAR YYYY(1901/2155) 14. DATETIME YYYY-MM-DD HH:MM:SS(1000-01-01 00:00:00/9999-12-31 23:59:59 Y) 15. TIMESTAMP YYYYMMDD HHMMSS(1970-01-01 00:00:00/2037 年某时)
1.7、修改表(alter)
添加列:alter table 表名 add 列名 类型 删除列:alter table 表名 drop column 列名 修改列: alter table 表名 modify column 列名 类型; -- 类型 alter table 表名 change 原列名 新列名 类型; -- 列名,类型 添加主键: alter table 表名 add primary key(列名); 删除主键: alter table 表名 drop primary key; alter table 表名 modify 列名 int, drop primary key; 添加外键:alter table 从表 add constraint 外键名称(形如:FK_从表_主表) foreign key 从表(外键字段) references 主表(主键字段); 删除外键:alter table 表名 drop foreign key 外键名称 修改默认值:ALTER TABLE testalter_tbl ALTER i SET DEFAULT 1000; 删除默认值:ALTER TABLE testalter_tbl ALTER i DROP DEFAULT;
更多参考:
- http://www.runoob.com/mysql/mysql-data-types.html
1.8、数据表关系
关联映射:一对多/多对一
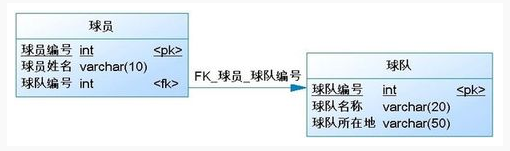
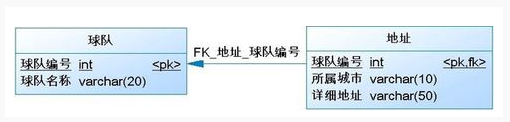

约束是一种限制,它通过对表的行或列的数据做出限制,来确保表的数据的完整性、唯一性。
MYSQL中,常用的几种约束:

===================================================
主键(PRIMARY KEY)是用于约束表中的一行,作为这一行的标识符,在一张表中通过主键就能准确定位到一行,因此主键十分重要。主键要求这一行的数据不能有重复且不能为空。
还有一种特殊的主键——复合主键。主键不仅可以是表中的一列,也可以由表中的两列或多列来共同标识
===================================================
默认值约束(DEFAULT)规定,当有DEFAULT约束的列,插入数据为空时该怎么办。
DEFAULT约束只会在使用INSERT语句(上一实验介绍过)时体现出来,INSERT语句中,如果被DEFAULT约束的位置没有值,那么这个位置将会被DEFAULT的值填充
===================================================
唯一约束(UNIQUE)比较简单,它规定一张表中指定的一列的值必须不能有重复值,即这一列每个值都是唯一的。
当INSERT语句新插入的数据和已有数据重复的时候,如果有UNIQUE约束,则INSERT失败.
===================================================
外键(FOREIGN KEY)既能确保数据完整性,也能表现表之间的关系。
一个表可以有多个外键,每个外键必须REFERENCES(参考)另一个表的主键,被外键约束的列,取值必须在它参考的列中有对应值。
在INSERT时,如果被外键约束的值没有在参考列中有对应,比如以下命令,参考列(department表的dpt_name)中没有dpt3,则INSERT失败
===================================================
非空约束(NOT NULL),听名字就能理解,被非空约束的列,在插入值时必须非空。
在MySQL中违反非空约束,不会报错,只会有警告.
例子:
create table if not EXISTS student( id int auto_increment primary key, #主键约束 +自增 stuName varchar(20) not null , #非空约束 gender char(1) , seat int unique, #唯一约束 age int default 18 , #默认约束,默认18 majorid int #外键约束,外键约束必须卸载constraint后面 #constraint fk_stuinfo_major foreign key(majorid) references major(id) )ENGINE=InnoDB DEFAULT CHARSET=utf8
2、数据库和表内容的操作(增、删、改、查)
1、增
insert into 表 (列名,列名...) values (值,值,值...) insert into 表 (列名,列名...) values (值,值,值...),(值,值,值...) insert into 表 (列名,列名...) select (列名,列名...) from 表
2、删
delete from 表 delete from 表 where id=1 and name='alex'
3、改
#一,修改单表记录 #语法: update 表名 set 字段 =值 ,字段等于值 ...where 筛选条件 #二, 修改多表记录 #语法: update 表1 别名 left | right | inner join 表2 别名 on 链接条件 set 字段= 值, 字段 =值 ... where 筛选条件
4、查
4.1、普通查询
select * from 表 select * from 表 where id > 1 select nid,name,gender as gg from 表 where id > 1
更多选项查询
a、条件
select * from 表 where id > 1 and name != 'alex' and num = 12;
select * from 表 where id between 5 and 16;
select * from 表 where id in (11,22,33)
select * from 表 where id not in (11,22,33)
select * from 表 where id in (select nid from 表)
b、限制
select * from 表 limit 5; - 前5行
select * from 表 limit 4,5; - 从第4行开始的5行
select * from 表 limit 5 offset 4 - 从第4行开始的5行
a、条件
select * from 表 where id > 1 and name != 'alex' and num = 12;
select * from 表 where id between 5 and 16;
select * from 表 where id in (11,22,33)
select * from 表 where id not in (11,22,33)
select * from 表 where id in (select nid from 表)
b、限制
select * from 表 limit 5; - 前5行
select * from 表 limit 4,5; - 从第4行开始的5行
select * from 表 limit 5 offset 4 - 从第4行开始的5行
4.2、数据排序(查询)
排序
select * from 表 order by 列 asc - 根据 “列” 从小到大排列
select * from 表 order by 列 desc - 根据 “列” 从大到小排列
select * from 表 order by 列1 desc,列2 asc - 根据 “列1” 从大到小排列,如果相同则按列2从小到大排序
4.3、模糊查询
通配符(模糊查询)
select * from 表 where name like 'ale%' - ale开头的所有(多个字符串)
select * from 表 where name like 'ale_' - ale开头的所有(一个字符)
4.4、聚集函数查询
1)COUNT 语法:COUNT(e1) 参数:e1为一个表达式,可以是任意的数据类型 返回:返回数值型数据 作用:返回e1指定列不为空的记录总数 2)SUM, 语法:SUM(e1) 参数:e1为类型为数值型的表达式 返回:返回数值型数据 作用:对e1指定的列进行求和计算 3)MIN, MAX 语法:MIN(e1)、MAX(e1) 参数:e1为一个字符型、日期型或数值类型的表达式。 若e1为字符型,则根据ASCII码来判断最大值与最小值。 返回:根据e1参数的类型,返回对应类型的数据。 作用:MIN(e1)返回e1表达式指定的列中最小值; MAX(e1)返回e1表达式指定的列中最大值; 4)AVG 语法:AVG(e1) 参数:e1为一个数值类型的表达式 返回:返回一个数值类型数据 作用:对e1表达式指定的列,求平均值。 5)MEDIAN 语法:MEDIAN(e1) 参数:e1为一个数值或日期类型的表达式 返回:返回一个数值或日期类型的数据 作用:首先,根据e1表达式指定的列,对值进行排序; 若排序后,总记录为奇数,则返回排序队列中,位于中间的值; 若排序后,总记录为偶数,则对位于排序队列中,中间两个值进行求平均,返回这个平均值; #四、流程控制函数 6) IF函数 SELECT IF(100>9,'好','坏'); #需求:如果有奖金,则显示最终奖金,如果没有,则显示0 SELECT IF(commission_pct IS NULL,0,salary*12*commission_pct) 奖金,commission_pct FROM employees; 7) CASE函数 ①情况1 :类似于switch语句,可以实现等值判断 CASE 表达式 WHEN 值1 THEN 结果1 WHEN 值2 THEN 结果2 ... ELSE 结果n END 案例: 部门编号是30,工资显示为2倍 部门编号是50,工资显示为3倍 部门编号是60,工资显示为4倍 否则不变 显示 部门编号,新工资,旧工资 SELECT department_id,salary, CASE department_id WHEN 30 THEN salary*2 WHEN 50 THEN salary*3 WHEN 60 THEN salary*4 ELSE salary END newSalary FROM employees; ②情况2:类似于多重IF语句,实现区间判断 CASE WHEN 条件1 THEN 结果1 WHEN 条件2 THEN 结果2 ... ELSE 结果n END 案例:如果工资>20000,显示级别A 工资>15000,显示级别B 工资>10000,显示级别C 否则,显示D SELECT salary, CASE WHEN salary>20000 THEN 'A' WHEN salary>15000 THEN 'B' WHEN salary>10000 THEN 'C' ELSE 'D' END AS a FROM employees; 8) data_sub()函数 通过data_sub()函数就可以基于某一个时间戳得到任意时间 select date_sub(now(), interval 1 year) from dual – 一年前 select date_sub(now(), interval -1 year) from dual – 一年后 select date_sub(now(), interval 12 month) from dual – 12个月之前 select date_sub(now(), interval -12 month) from dual – 12个月之后 select date_sub(now(), interval 1 day) from dual – 一天前 select date_sub(now(), interval -1 day) from dual – 一天后 select date_sub(now(), interval 24 hour) from dual – 24小时前 select date_sub(now(), interval -24 hour) from dual – 24小时后 select date_sub(now(), interval 100 minute) from dual – 100分钟之前 select date_sub(now(), interval -100 minute) from dual – 100分钟之后 select date_sub(now(), interval 24 second) from dual – 24秒之前 select date_sub(now(), interval -24 second) from dual – 24秒之后 案例:查询10分钟设备是否在线,根据上报时间判断,查询上报时间在十分钟以内的设备大于0就在线,否则就离线 SELECT IF ( COUNT( 1 ) = 0, '离线', '在线' ) AS 设备状态 FROM ( SELECT mac_address FROM pro_device_resource WHERE mac_address = 'Mac地址' AND create_time > DATE_SUB( NOW(), INTERVAL 10 minute) GROUP BY mac_address )s
4.5、分组查询+排序
#语法:
select 分组函数,列(要求出现在group by的后面)
from 表
where 筛选条件
group 分组的列表
having 分组后筛选
order by 排序
limit 检索记录行
select num,nid,count(*),sum(score),max(score),min(score) from 表 where num='111' group by num,nid having max(id) > 10 #having是分组后的筛选 order by nid desc
4.6多表查询
a、连表
#sql99语法 无对应关系则不显示 select A.num, A.name, B.name from A,B Where A.nid = B.nid
#内链接 无对应关系则不显示 select A.num, A.name, B.name from A inner join B on A.nid = B.nid
#左外链接 A表所有显示,如果B中无对应关系,则值为null select A.num, A.name, B.name from A left join B on A.nid = B.nid
#右外链接 B表所有显示,如果B中无对应关系,则值为null select A.num, A.name, B.name from A right join B on A.nid = B.nid
b、组合 组合,自动处理重合 select nickname from A union select name from B 组合,不处理重合 select nickname from A union all select name from B
4.7. 子查询
/* 分类 按子查询出现的位置 select后面: 仅仅支持标量子查询 from后面 :支持表子查询 重点: where或having后面: 支持标量和列子查询,也支持行子查询,但是较少 exists后面(相关子查询):支持表子查询 按结果集的行列数不同 标量子查询(结果集只有一行一列) 列子查询(结果集只有一行多列) 行子查询(结果集又一行多列) 表子查询(一般为多行多列) 行子查询和列子查询都统称为表子查询 特点 ①子查询放在小括号内 ②子查询一般放在条件的右侧 ③标量子查询,一般搭配单行操作符使用 >, <, >= , <= , = ,<> ④列子查询,一般搭配着多行操作符使用 in , all */
4.7.1 where或having后面标量子查询(一行一列)
#一 .where后面标量子查询 #案例1.谁的工资比Abel高? #①查询Abel的工资 select salary from employees where last_name='Abel' #②查询用工信息,满足salary>①的结果 select * from employees where salary>( select salary from employees where last_name='Abel' ) #案例2: 返回job_id与141号员工相同,salary比143号员工多的员工 姓名,job_id和工资 #①先查询出141号员工的job_id select job_id from employees where employee_id=141 #②查询出143员工的salary select salary from employees where employee_id=143 #③查询出员工的姓名,job_id,要求job_id=①,并且salary>② select job_id,last_name,salary from employees where job_id=( select job_id from employees where employee_id=141 )and salary>( select salary from employees where employee_id=143 ) #案例3: 返回公司工资最少的员工last_name,job_id和salary #①查询公司的最低工资 select min(salary) from employees #②查询last_name,job_id和salary,要求salary=① select last_name,job_id,salary from employees where salary=( select min(salary) from employees )
4.7.2 where或者having后面列子查询(多行子查询)
#where或having后面的列子查询(多行子查询) 需要配合 in/not in, all #案例1: 返回location_id是1400或1700的部门中的所有员工姓名 #①查询出location_id是1400和1700的部门编号 select DISTINCT department_id from departments where location_id in (1400,1700) #②查询出department_id =①的员工信息 select * from departments where department_id in ( select DISTINCT department_id from departments where location_id in (1400,1700) )
4.7.3 select后面子查询(只支持标量)
# select后面 #案例1.查询每个部门的员工个数 select d.* ,( select count(*) from employees e where e.department_id= d.department_id ) AS 个数 from departments d
4.7.4 from后面子查询 ,子查询充当一张表,需要有别名
# from 后面的子查询 #案例: 查询每个部门的平均工资的工资等级 #①查询每个部门的平均工资 select avg(salary),department_id from employees GROUP BY department_id #②链接①的结果集和job_grades表,筛选条件平均工资 between lowest_sal and highest_sal select ag_dep.*, g.grade_level from ( select avg(salary) ag,department_id from employees GROUP BY department_id ) ag_dep inner join job_grades g on age_dep.ag between lowest_sal and highest_sal
5、视图
含义:虚拟表,和普通表一样使用,视图只保存了sql逻辑,不保存查询结果.在使用的时候动态生成
5.1 创建视图:
# 创建视图 #语法: /* create view 视图名 AS 查询语句; */ 案例: #①.创建视图表myv1 create view myv1 AS select last_name,department_name,job_title from employees e inner join departments d on e.department_id = d.department_id inner join jobs j on j.job_id = e.job_id; #②.使用视图,语法和普通表一样 select * from myv1
5.2 视图的修改
#视图的修改 /* 语法: alter view 视图名 AS 查询语句 */
5.3 视图的删除
#视图的删除,可以一次删除多个 /* 语法: drop view 视图名 ,视图名,...... */
6、mysql事务
本文实验的测试环境:Windows 10+cmd+MySQL5.6.36+InnoDB
一、事务的基本要素(ACID)
1、原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节。事务执行过程中出错,会回滚到事务开始前的状态,所有的操作就像没有发生一样。也就是说事务是一个不可分割的整体,就像化学中学过的原子,是物质构成的基本单位。
2、一致性(Consistency):事务开始前和结束后,数据库的完整性约束没有被破坏 。比如A向B转账,不可能A扣了钱,B却没收到。
3、隔离性(Isolation):同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B不能向这张卡转账。
4、持久性(Durability):事务完成后,事务对数据库的所有更新将被保存到数据库,不能回滚。
二、事务的并发问题
1、脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
2、不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。
3、幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
三、MySQL事务隔离级别
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 不可重复读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
mysql默认的事务隔离级别为repeatable-read

四、用例子说明各个隔离级别的情况
1、读未提交:
(1)打开一个客户端A,并设置当前事务模式为read uncommitted(未提交读),查询表account的初始值:

(2)在客户端A的事务提交之前,打开另一个客户端B,更新表account:

(3)这时,虽然客户端B的事务还没提交,但是客户端A就可以查询到B已经更新的数据:

(4)一旦客户端B的事务因为某种原因回滚,所有的操作都将会被撤销,那客户端A查询到的数据其实就是脏数据:

(5)在客户端A执行更新语句update account set balance = balance - 50 where id =1,lilei的balance没有变成350,居然是400,是不是很奇怪,数据不一致啊,如果你这么想就太天真 了,在应用程序中,我们会用400-50=350,并不知道其他会话回滚了,要想解决这个问题可以采用读已提交的隔离级别

2、读已提交
(1)打开一个客户端A,并设置当前事务模式为read committed(未提交读),查询表account的所有记录:

(2)在客户端A的事务提交之前,打开另一个客户端B,更新表account:

(3)这时,客户端B的事务还没提交,客户端A不能查询到B已经更新的数据,解决了脏读问题:

(4)客户端B的事务提交

(5)客户端A执行与上一步相同的查询,结果 与上一步不一致,即产生了不可重复读的问题

3、可重复读
(1)打开一个客户端A,并设置当前事务模式为repeatable read,查询表account的所有记录

(2)在客户端A的事务提交之前,打开另一个客户端B,更新表account并提交

(3)在客户端A查询表account的所有记录,与步骤(1)查询结果一致,没有出现不可重复读的问题

(4)在客户端A,接着执行update balance = balance - 50 where id = 1,balance没有变成400-50=350,lilei的balance值用的是步骤(2)中的350来算的,所以是300,数据的一致性倒是没有被破坏。可重复读的隔离级别下使用了MVCC机制,select操作不会更新版本号,是快照读(历史版本);insert、update和delete会更新版本号,是当前读(当前版本)。

(5)重新打开客户端B,插入一条新数据后提交

(6)在客户端A查询表account的所有记录,没有 查出 新增数据,所以没有出现幻读

4.串行化
(1)打开一个客户端A,并设置当前事务模式为serializable,查询表account的初始值:
mysql> set session transaction isolation level serializable; Query OK, 0 rows affected (0.00 sec) mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> select * from account; +------+--------+---------+ | id | name | balance | +------+--------+---------+ | 1 | lilei | 10000 | | 2 | hanmei | 10000 | | 3 | lucy | 10000 | | 4 | lily | 10000 | +------+--------+---------+ 4 rows in set (0.00 sec)
(2)打开一个客户端B,并设置当前事务模式为serializable,插入一条记录报错,表被锁了插入失败,mysql中事务隔离级别为serializable时会锁表,因此不会出现幻读的情况,这种隔离级别并发性极低,开发中很少会用到。
mysql> set session transaction isolation level serializable; Query OK, 0 rows affected (0.00 sec) mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> insert into account values(5,'tom',0); ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
补充:
1、事务隔离级别为读提交时,写数据只会锁住相应的行
2、事务隔离级别为可重复读时,如果检索条件有索引(包括主键索引)的时候,默认加锁方式是next-key 锁;如果检索条件没有索引,更新数据时会锁住整张表。一个间隙被事务加了锁,其他事务是不能在这个间隙插入记录的,这样可以防止幻读。
3、事务隔离级别为串行化时,读写数据都会锁住整张表
4、隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大。
