python网络爬虫简介(第一章)
Python网络爬虫相关概念
爬虫介绍
引入:
- 之前在授课过程中,好多同学都问过我这样的一个问题:为什么要学习爬虫,学习爬虫能够为我们以后的发展带来那些好处?其实学习爬虫的原因和为我们以后发展带来的好处都是显而易见的,无论是从实际的应用还是从就业上。
- 我们都知道,当前我们所处的时代是大数据的时代,在大数据时代,要进行数据分析,首先要有数据源,而学习爬虫,可以让我们获取更多的数据源,并且这些数据源可以按我们的目的进行采集。
- 优酷推出的火星情报局就是基于网络爬虫和数据分析制作完成的。其中每期的节目话题都是从相关热门的互动平台中进行相关数据的爬取,然后对爬取到的数据进行数据分析而得来的。另一方面,优酷根据用户实时观看视频时的前进,后退等行为数据,能够推测计算出观众的兴趣点和爱好点,这样有助于节目的剪辑和后期的节目方案的编写。
- 今日头条作为一个新闻推荐类的应用,其内部的新闻数据都是通过爬虫程序在各个新闻网站进行新闻数据的爬取,然后通过相应的处理和运算将用户感兴趣的新闻话题推送到用户的手机上。
- 从就业的角度来说,爬虫工程师目前来说属于紧缺人才,并且薪资待遇普遍较高所以,深层次地掌握这门技术,对于就业来说,是非常有利的。有些人学习爬虫可能为了就业或者跳槽。从这个角度来说,爬虫工程师是不错的选择之一。随着大数据时代的来临,爬虫技术的应用将越来越广泛,在未来会拥有更好的发展空间。
今日详情
什么是爬虫:
- 爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程
- 解析:
浏览器怎么上网,我就模拟浏览器上网,然后去获取数据
从中获取两个主要的关键字:
模拟:什么是模拟,为什么要模拟浏览器:
- 因为:所谓的浏览器就是纯天然的爬虫工具(在浏览器中输入请求的内容,获取相应的网页,最终在浏览器中看到相应的页面)
爬取(抓取):
-
抓取到页面的一整张数据
-
抓取页面中的局部数据
爬虫在使用场景中的分类:
- 通用爬虫:
需要将页面一整张数据惊醒爬取 - 聚焦爬虫:
需要将页面中的数据局部爬取(聚焦爬虫与通用爬虫是有关联的,聚焦爬虫是需要建立在通用爬虫的基础上。) - 增量式爬虫:
检测网站数据的更新的情况,用增量式爬虫爬取网站中最新更新出来的数据。 - 分布式爬虫:
可以搭建一个分布式集群,可以快速的进行海量数据的爬取
爬虫的合法性探究:
- .如果你的爬虫程序没有影响对方网站的正常运行且没有爬取相关涉及侵权的数据
爬虫的核心:
反爬机制:
- 一些网站,不想让其他人爬取自己网站的数据,怎么办:
- 一些门户网站在服务器端会设置一些机制或策略用来阻止爬虫对数据的爬取
反反爬机制:
- 我们想要获取更多更完整的数据,去破解反爬机制。
-即爬虫需要破解网站指定的反爬机制从而爬取到网站的数据
开发环境:
anacanda
-
anacanda: 是一个基于数据分析+机器学习的集成环境。
-
jupyter: anaconda提供的一一个基于浏览器可视化的而开发|
-
安装:
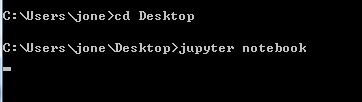
安装了anaconda后,需要在终端中录入jupyter notebook指令。 -
使用:
-注意: jupyter notebook指令对应的终端目录就是jupyter启动后的根目录
默认是在根目录下,如果切换到其他目录,那么这个目录就是根目录如:
cd Desktop/ 那么根目录就是Desktop

其中如果创建了一个python3 的文件,后缀名为ipynd

. ipynb是 jupyter中的一个源文件,代码的编写就要基于该源文件。该源文件是由cell组成的(每一行就是一个cell)
cell的使用: -
cell是分成了两种不同的模式:
code:用来编写程序的
markdown:用来编写笔记 -
快捷键:
。添加cell: a,b
。删除cell: x
。切换cel的模式:
。code-》markdown: m
。反之:y
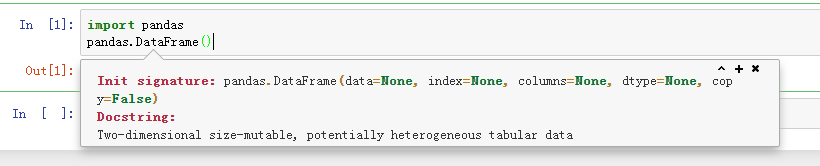
。查看帮助文档: shift+tab
有志者,事竟成,破釜沉舟,百二秦关终属楚;
苦心人,天不负,卧薪尝胆,三千越甲可吞吴。
想到与得到中间还有两个字——做到。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号