【Java基础四】-基础函数实践一
最近在新迭代的版本中,遇到这么几个需求,其实核心涉及到的还是最基本的Java基础或者函数,本次将自己近期的需求做法给予分享一下:
一、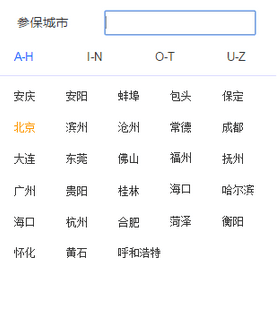
看需求,需要给前端提供4部分内容,转换思想,其实就是提供4个List集合就好,那么我到底该怎么处理后端数据,让其能对号入座呢?
很简单,自己的思想就是首先必须获取每个数据的首字母,然后将其进行排序判断,然后对应座位即可,下边分享自己的demo。
工具类:
public class FirstLetterUntil {
private static int BEGIN = 45217;
private static int END = 63486;
// 按照声母表示,这个表是在GB2312中的出现的第一个汉字,也就是说“啊”是代表首字母a的第一个汉字。
// i, u, v都不做声母, 自定规则跟随前面的字母
private static char[] chartable = {'啊', '芭', '擦', '搭', '蛾', '发', '噶', '哈',
'哈', '击', '喀', '垃', '妈', '拿', '哦', '啪', '期', '然', '撒', '塌', '塌',
'塌', '挖', '昔', '压', '匝',};
// 二十六个字母区间对应二十七个端点
// GB2312码汉字区间十进制表示
private static int[] table = new int[27];
// 对应首字母区间表
private static char[] initialtable = {'a', 'b', 'c', 'd', 'e', 'f', 'g',
'h', 'h', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't',
't', 't', 'w', 'x', 'y', 'z',};
// 初始化
static {
for (int i = 0; i < 26; i++) {
table[i] = gbValue(chartable[i]);// 得到GB2312码的首字母区间端点表,十进制。
}
table[26] = END;// 区间表结尾
}
/**
* 根据一个包含汉字的字符串返回一个汉字拼音首字母的字符串 最重要的一个方法,思路如下:一个个字符读入、判断、输出
*/
public static String getFirstLetter(String sourceStr) {
String result = "";
String str = sourceStr.toLowerCase();
int StrLength = str.length();
int i;
try {
for (i = 0; i < StrLength; i++) {
result += Char2Initial(str.charAt(i));
}
} catch (Exception e) {
result = "";
}
return result;
}
/**
* 输入字符,得到他的声母,英文字母返回对应的大写字母,其他非简体汉字返回 '0'
*/
private static char Char2Initial(char ch) {
// 对英文字母的处理:小写字母转换为大写,大写的直接返回
if (ch >= 'a' && ch <= 'z') {
return ch;
}
if (ch >= 'A' && ch <= 'Z') {
return ch;
}
// 对非英文字母的处理:转化为首字母,然后判断是否在码表范围内,
// 若不是,则直接返回。
// 若是,则在码表内的进行判断。
int gb = gbValue(ch);// 汉字转换首字母
if ((gb < BEGIN) || (gb > END))// 在码表区间之前,直接返回
{
return ch;
}
int i;
for (i = 0; i < 26; i++) {// 判断匹配码表区间,匹配到就break,判断区间形如“[,)”
if ((gb >= table[i]) && (gb < table[i + 1])) {
break;
}
}
if (gb == END) {//补上GB2312区间最右端
i = 25;
}
return initialtable[i]; // 在码表区间中,返回首字母
}
/**
* 取出汉字的编码 cn 汉字
*/
private static int gbValue(char ch) {// 将一个汉字(GB2312)转换为十进制表示。
String str = new String();
str += ch;
try {
byte[] bytes = str.getBytes("GB2312");
if (bytes.length < 2) {
return 0;
}
return (bytes[0] << 8 & 0xff00) + (bytes[1] & 0xff);
} catch (Exception e) {
return 0;
}
}自己的测试类:
public static void main(String[] args) throws ParseException {
// Collator 类是用来执行区分语言环境的 String 比较的,这里选择使用CHINA
Comparator comparator = Collator.getInstance(java.util.Locale.CHINA);
//设置的假数据
String[] arrStrings = {"阿狸", "小白", "乖乖", "羊宝宝", "猴崽子", "王四", "宝贝"};
//定义的4个list集合
List<String> firstList = new ArrayList<>();
List<String> secondList = new ArrayList<>();
List<String> thirdList = new ArrayList<>();
List<String> lastList = new ArrayList<>();
//一一取出,进行判断
for (int i = 0; i < arrStrings.length; i++) {
String a = arrStrings[i];
String first1 = FirstLetterUntil.getFirstLetter(a).substring(0, 1);
if (first1.equals("a") || first1.equals("b") || first1.equals("c") || first1.equals("d") || first1.equals("e") || first1.equals("f")) {
firstList.add(a);
}
if (first1.equals("i") || first1.equals("g") || first1.equals("k") || first1.equals("l") || first1.equals("m") || first1.equals("n")) {
secondList.add(a);
}
if (first1.equals("o") || first1.equals("p") || first1.equals("q") || first1.equals("r") || first1.equals("s") || first1.equals("t")) {
thirdList.add(a);
}
if (first1.equals("u") || first1.equals("v") || first1.equals("w") || first1.equals("x") || first1.equals("y") || first1.equals("z")) {
lastList.add(a);
}
}
System.out.println(firstList);
System.out.println(secondList);
System.out.println(thirdList);
System.out.println(lastList);
}最后的输出结果:
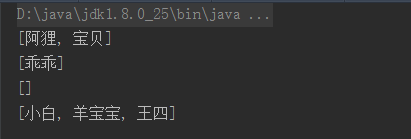
这样,在前端只需要一一获取list集合则可以满足需求。
二:谈到根据字母获取信息的需求,除此之外,还有一个是直接从A到Z一一获取的,就和手机通讯录一样,两种想法,一种无空返回,就是说字母Z下边无数据,那么前端就不显示字母Z;另一种是A-Z都显示,若没数据,则显示为空;相比上个要求,英文字母分四段显示,需求上是复杂了些许,但是代码上确实提炼了许多,我们只需要通过K—Value的形式,对号入座即可。
public static void main(String[] args) throws ParseException {
//设置的假数据
String[] arrStrings = {"阿狸", "阿宝", "小白", "乖乖","网络","杨树", "羊宝宝", "猴崽子", "王四", "宝贝"};
Map<Object, String> map = new HashMap<>();
for (int i = 0; i < arrStrings.length; i++) {
//获取对应的集合
String myStr = arrStrings[i];
//获取第一个字母
String myKey = FirstLetterUntil.getFirstLetter(myStr).substring(0, 1);
//判定首字母是否相同,相同,放到同一个value中
if (map.containsKey(myKey)){
map.put(myKey,map.get(myKey)+","+myStr);
}else {
map.put(myKey,myStr);
}
}
System.out.println(map);看输出结果:

三:由于结算的需求,我需要将A表信息通过id整合一下,存入到B表中,意思就是说假如A表中id为1234的数据有4条,我需要汇总一下条数,以及里边的部分字段的求和然后以id为关联字段,创建一条记录放入B表中;也就是说B表中我每个id只有一条数据来汇总。
我使用的主要的思想就是set去重的思想,比如A表中Id=1234的有4条;Id=4567的有5条,汇总到set集合中,我也仅仅有两条数据而已;至于数量的汇总,使用了collections的方法。
看核心代码:
public static int frequency(Collection<?> c, Object o) {
int result = 0;
if (o == null) {
for (Object e : c)
if (e == null)
result++;
} else {
for (Object e : c)
if (o.equals(e))
result++;
}
return result;
}整个需求的部分代码:
Set set = new HashSet(supplierIdList);
for (Object s : set) {
int thingsCounts = 0;
double rate = 0;
//计算不同的供应商id对应的个数
int count = Collections.frequency(supplierIdList, s);
}好多需求都是看java 基础的,基础扎实,真的是什么都不怕解决啊。借此激励自己,加油!

