JS正则匹配过滤字符串中的html标签及html标签内的内容
使用正则过滤html标签。
以前写了很多次。但每次都没保存,然后换了家公司后,没有了以前的代码,然后又遇到类似的问题,然后又是网上查啊写啊,自己鼓捣了大半天。
所以,这次,我决定在博客上也写一份,备份,省的下次又自己写一次,浪费我的脑细胞。
一、匹配html标签,但不匹配html标签里的内容(简单粗暴,直接上正则。前面三种不是我所需要的,后面reg4过滤单标签的,可以需要)
var reg = /<[^>]+>/gi; //匹配所有的html标签。但不包括html标签内的内容 var reg2 = /<(?!img).*?>/gi; //匹配除img标签外的html标签 不包括html标签内的内容 var reg3 = /<(?!img|p|\/p).*?>/gi; //匹配除img、p标签外的html标签 不包括html标签内的内容 var reg4 = /<(img|br|hr|input)[^>]*>/gi; //只匹配img、br、hr、input标签
二、匹配html标签里内容的正则,有两大难点
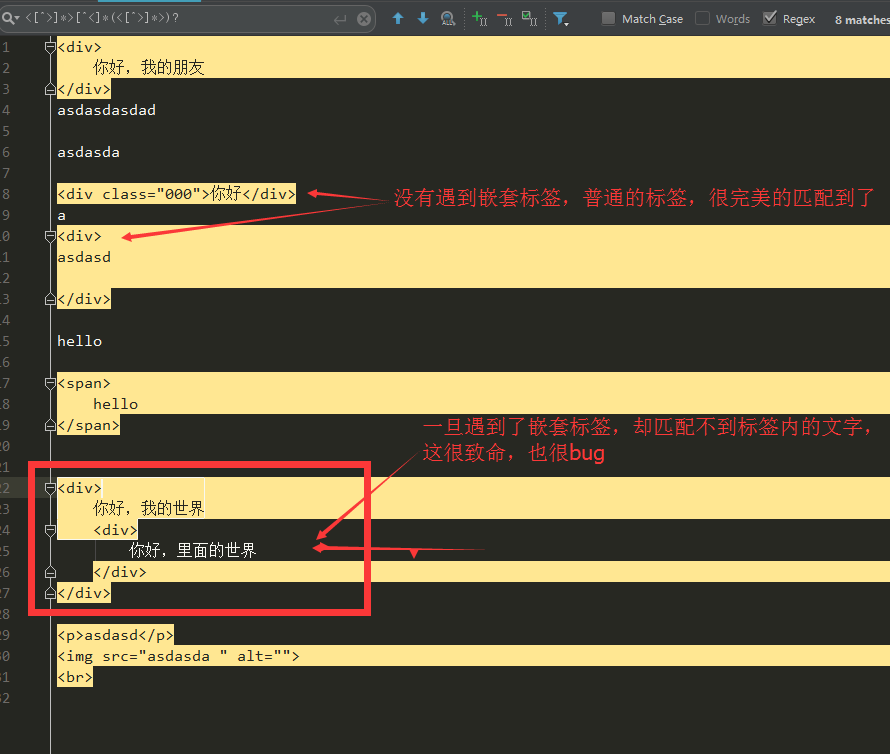
1、单标签和双标签的区别 例如 <br><img> 和 <div></div> 的区别
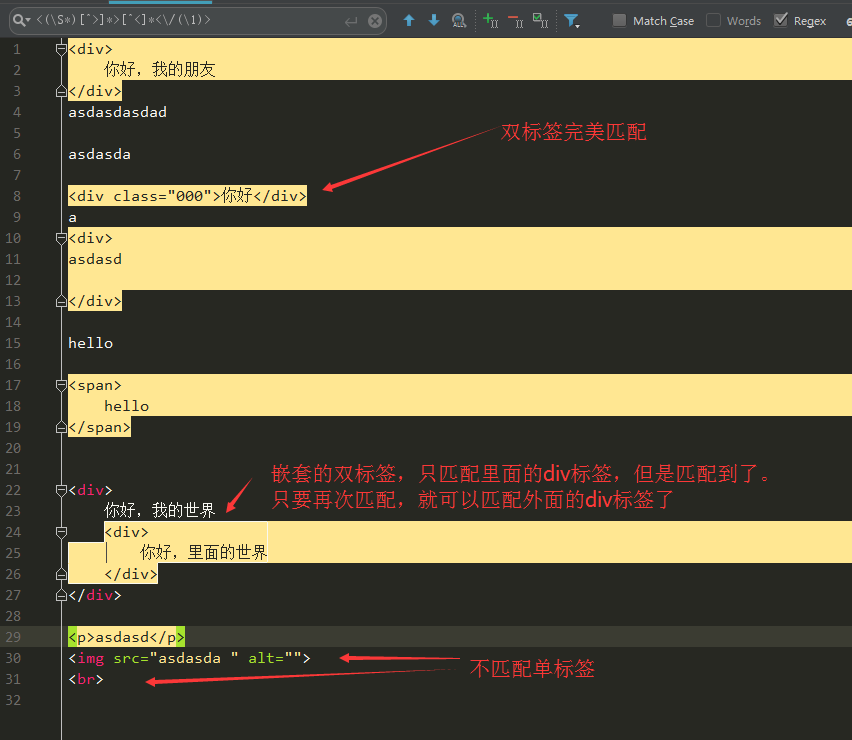
2、嵌套标签(超难,基本无解,若需要过滤的话,则可以通过分组匹配一直重复匹配来解决) 例如 <div>外面的div<div>里面的div</div></div>
思路:
先用下面的正则把所有的单标签去除:
var reg = /<(img|br|hr|input)[^>]*>/gi;
再上基本的正则匹配代码:
/* * 普通匹配 (但后面用不到,用不到的原因,可查看下面截图) * 下面两个可以匹配 * 但是有个bug 嵌套标签的结构就不会被匹配到 例如这样的结构: <div>外面的div<div>里面的div</div></div> * 这也就是上面所说的嵌套标签的难点 * */ var reg = /<div[^>]*>[^<]*<\/div>/gi; //匹配所有的div标签。包括div标签内的内容 var reg2 = /<[^>]*>[^<]*(<[^>]*>)?/gi; //匹配所有的html标签,包括html标签内的内容 /* * 使用分组匹配 * bug跟上面的一样 嵌套标签的结构就不会被匹配到 例如这样的结构: <div>外面的div<div>里面的div</div></div> * 如果用在过滤上的话,可以重复过滤(不会少过滤掉一些本就在标签内的内容,也不会多过滤标签外的内容)。在过滤上看,分组匹配比上面的匹配靠谱多了。 * 但是,有个小问题,下面的分组匹配正则匹配不到单标签的,所以还需要用到上面的一般匹配。 * 双标签对应匹配 * */ var reg3 = /<(div)[^>]*>[^<]*<\/(\1)>/gi; //分组匹配 匹配所有的div标签,包括div标签内的内容 var reg4 = /<(\S*)[^>]*>[^<]*<\/(\1)>/gi; //分组匹配 匹配所有的html双标签,包括div标签内的内容
再分析上面的两个匹配:
普通匹配,可以匹配到单标签和双标签,但是嵌套标签,这就问题大了,看下面截图
分组匹配,只能匹配双标签,但是嵌套标签,有点小问题,但可以接受,可以用循环来匹配,看下面截图
这思路写的不好,不喜勿喷,也希望正则大佬留下说出新的想法。
最终代码:
/* * 在网上看到用 new RegExp() 比 正则字面量 速度快 * 网址:https://www.cnblogs.com/52cik/p/js-regular-literal-regexp.html * 我没测试过,姑且一试,以后有机会弄个测试出来 * */ /* * 正则放定义的原因: * 是我不想在函数里重复定义正则,比较损性能,但如果不是多次使用级别的,那也损不了多少性。 * */ // var reg = /<[^>]+>/gi; //过滤所有的html标签 var reg = new RegExp('<[^>]+>','gi'); //过滤所有的html标签,不包括内容 // var reg2 = /<(img|br|hr|input)[^>]*>/gi; //只匹配img、br、hr、input标签 var reg2 = new RegExp('<(img|br|hr|input)[^>]*>','gi'); //只匹配img、br、hr、input标签 // var reg3 = /<(\S*)[^>]*>[^<]*<\/(\1)>/gi; //分组匹配,过滤所有的html标签,包括内容 var reg3 = new RegExp('<(\\S*)[^>]*>[^<]*<\\/(\\1)>','gi'); //分组匹配,过滤所有的html标签,包括内容 /* * 将所有的标签过滤,不过滤标签内内容 * */ function filterHtml(str){ if(typeof str !='string'){ //不是字符串 return str; } return str.replace(reg,''); } /* * 讲所有的标签过滤,也过滤标签内的内容 * str 需要过滤的字符串 * isbool 为false则需要单标签过滤,为true则不需要单标签过滤 * */ function filterHtmlOrContainer(str,isbool) { if(typeof str !='string'){ //不是字符串 return str; } var result = str; if(!isbool){ //先把单标签过滤了 result = result.replace(reg2, ''); } result = result.replace(reg3,''); //先经过分组匹配,把双标签去除,如果是嵌套标签,则会先将嵌套标签内的双标签过滤掉 if(reg3.test(result)) { //如果为true,则代表还有标签 return filterHtmlOrContainer(result, true); }else { return result; } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号