

在 Windows 上利用Qwen大模型搭建一个 ChatGPT 式的问答小助手
本文首发于公众号:Hunter后端
原文链接:在 Windows 上利用Qwen大模型搭建一个 ChatGPT 式的问答小助手
最近 ChatGPT 式的聊天机器人比较火,可以提供各种问答功能,阿里最近推出了 Qwen1.5 系列的大模型,提供了各个参数版本的大模型,其中有一些参数量较小的模型,比较适合我们这种穷* 用于尝试一下手动运行大模型。
今天我们就使用 Qwen1.5 大模型来尝试一下,自己搭建一个问答小助手。
1、配置
首先介绍一下搭建的环境,8g 内存,4g GPU 显存,win10系统,所以如果配置等于或高于我这个环境的也可以轻松实现这一次的搭建过程。
下面是搭建成功后一些问答的效果展示:


其中,因为显存限制,我这边分别使用 Qwem1.5-0.5B-Chat 和 Qwem1.5-1.8B-Chat 进行测试,0.5B 版本占用显存不到 2g,1.8B 版本显存占用不到 4g,这个 B 表示的是模型使用的参数量,在我电脑上 0.5B 的版本推理速度要比 1.8B 的速度要快很多,但是某些问题的准确性没有 1.8B 高。
接下来正式介绍搭建过程。
2、环境安装
使用 Qwen 这个大模型需要用到 CUDA 相关驱动以及几个 Python 库,torch,transformers,accelerate 等。
1. CUDA
首先,确认 Windows 机器上是否有相关驱动,这里我们可以在 cmd 里输入 nvidia-smi 查看相应输出,比如我的输入如下:
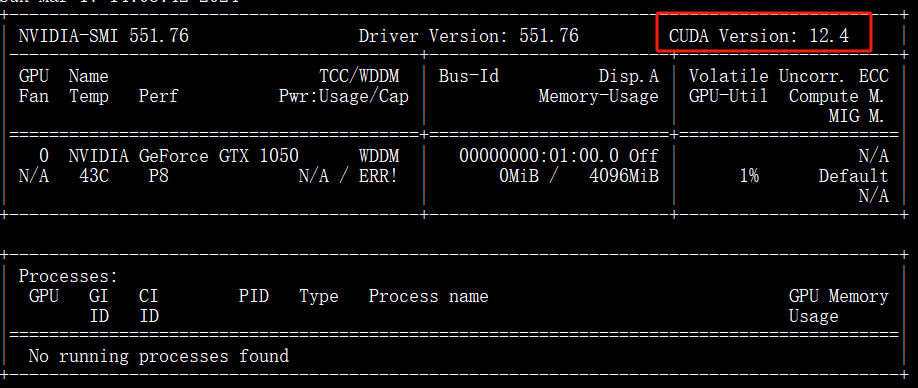
然后上张图里截出来的 CUDA Version 去下面这个地址下载 CUDA Toolkit:https://developer.nvidia.com/cuda-toolkit-archive
到这一步完成,相应的 CUDA 准备工作就 OK 了。
建议可以先看下下面这个链接,里面有完整的安装示意流程:Windows下CUDA安装
2. conda 环境准备
这里为了方便,我新建了一个 conda 环境,使用的 Python 3.10 版本
conda create -n qwen python=3.10
3. torch 库
为了使用 GPU,torch 库的版本需要是 cuda 版本的,在 Windows 版本下我直接安装其 whl 包,可以在下面的地址找到对应的版本:https://download.pytorch.org/whl/torch_stable.html。
这里我下载的是文件名是 torch-2.2.1+cu121-cp310-cp310-win_amd64.whl。
torch-2.2.1 表示的是 torch 的版本
cu121 表示的是 cuda 版本是 12.1,我们实际的 CUDA Version 是 12.4,没有最新的但是也能兼容
cp310 是 Python 的版本 3.10
win_amd64 则是 Windows 版本。
whl 包比较大,有 2 个多 g,下载后直接到对应的目录下执行下面的操作即可:
pip3 install torch-2.2.1+cu121-cp310-cp310-win_amd64.whl
4. transformers 库
transformers 库是使用大模型的基础库,这里注意下,Qwen1.5 版本的大模型是最近才出来的,所以 transformers 库需要比较新的才能支持,需要 >= 4.37.0
这里我们直接 pip3 install transformers 就会自动为我们安装最新的库,也可以直接指定这个版本。
5. accelerate 库
我在操作的过程中,还需要用到 accelerate 这个库,所以额外安装下:
pip3 install accelerate -i https://mirrors.aliyun.com/pypi/simple/
到这一步,我们的环境就安装好了,我们可以尝试一下是否可以正常使用 CUDA:
import torch
print(torch.cuda.is_available())
# True
输出为 True 则表示可以正常使用 CUDA。
3、下载模型
所有大模型的下载官方都会发布在 huggingface 网站上:https://huggingface.co/。
我们可以在上面搜索到目前所有发布的大模型,包括 Qwen 系列,百川系列,ChatGLM 系列,Llama 系列等。
我们可以下载下一步执行代码的时候直接指定模型名称,会自动为我们下载,但是我习惯于先将其下载下来,然后在本地指定路径进行调用。
这里我们可以去这两个地址下载对应的文件:
https://huggingface.co/Qwen/Qwen1.5-0.5B-Chat/tree/main
https://huggingface.co/Qwen/Qwen1.5-1.8B-Chat/tree/main
分别是 Qwen1.5 的 0.5B Chat 版本和 1.8B Chat 版本。
其中,最主要的文件是 model.safetensors,这个就是大模型本身,也就是我们运行的时候需要加载的文件,可以看到这两个地址的这个文件分别是 1g 多和 3g 多。
除此之外,还有一些必要的配置文件比如 config.json,一些词表的文件用于加载的时候做映射操作。
注意:上面的网址可能需要一些魔法操作,如果你没有魔法的途径,可以去魔搭社区找对应的版本,https://www.modelscope.cn/search?search=Qwen1.5
这里,下载的大模型文件列表如下图所示:

至此,我们所有的准备工作就完成了,接下来我们可以开始写代码进行问答操作了。
4、对话代码
我们需要先加载大模型:
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
path = r"F:\\models\\Qwen1.5-0.5B-Chat"
model = AutoModelForCausalLM.from_pretrained(
path,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(path)
这里的 path 就是我们下载的大模型的本地文件路径。
接下来下面的代码就是进行对话的操作了:
prompt = "你是谁"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
# 我是来自阿里云的超大规模语言模型,我叫通义千问。我是一个能够回答问题、创作文字,还能表达观点、撰写代码的 人工智能模型。如果您有任何问题或需要帮助,请随时告诉我,我会尽力提供支持和解答。
1. 封装成函数
我们可以将上面下部分代码封装成函数,这样就可以每次直接调用函数来进行问答操作了:
def get_response(prompt):
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512,
pad_token_id=tokenizer.eos_token_id
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
然后可以直接调用函数进行问答:
get_response("如何学习Python?")
2. 保存历史进行多轮对话
接下来我们可以保存对话历史来进行多轮对话,以下是代码:
def run_qwen_with_history():
messages = [
{"role": "system", "content": "You are a helpful assistant."},
# {"role": "user", "content": prompt}
]
while True:
new_question = input("请输入你的问题:")
if new_question == "clear":
messages = [messages[0]]
continue
messages.append({"role": "user", "content": new_question})
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512,
pad_token_id=tokenizer.eos_token_id
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
messages.append({"role": "system", "content": response})
在这里执行这个函数之后,会在命令行里输出 请输入你的问题:,然后我们可以输入我们的问题,之后可以连续多轮输出,后台会记住我们之前的对话,从而实现多轮对话的功能。
5、总结
经过分别使用 0.5B 版本和 1.8B 的版本,在我电脑的配置里,0.5B 版本的输出会快一些,但是在某些问题回答的质量上不如 1.8B。
而 1.8B 版本答案质量相对较高,但是速度在 4g 显存的情况下,则非常慢。
以上就是本次使用 Qwen1.5 在 Windows 上搭建问答小助手的全过程,之后还可以将大模型提供接口操作,将其应用到 web 页面上,从而实现一个真正的 ChatGPT 式问答助手。
对于以上这些操作是直接使用的大模型,而真正要将其应用于生产,还需要对大模型进行微调,训练等一系列操作,使其更适用于实际场景,这些以后有机会再学习介绍吧。
如果想获取更多后端相关文章,可扫码关注阅读:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix