
线程创建的四种方式
java中创建线程的四种方法以及区别
Java使用Thread类代表线程,所有的线程对象都必须是Thread类或其子类的实例。Java可以用三种方式来创建线程,如下所示:
1)继承Thread类创建线程
2)实现Runnable接口创建线程
3)使用Callable和Future创建线程
4)使用线程池例如用Executor框架
下面让我们分别来看看这四种创建线程的方法。
------------------------继承Thread类创建线程---------------------
通过继承Thread类来创建并启动多线程的一般步骤如下
1】d定义Thread类的子类,并重写该类的run()方法,该方法的方法体就是线程需要完成的任务,run()方法也称为线程执行体。
2】创建Thread子类的实例,也就是创建了线程对象
3】启动线程,即调用线程的start()方法
代码实例
public class MyThread extends Thread{//继承Thread类
public void run(){
//重写run方法
}
}
public class Main {
public static void main(String[] args){
new MyThread().start();//创建并启动线程
}
}
------------------------实现Runnable接口创建线程---------------------
通过实现Runnable接口创建并启动线程一般步骤如下:
1】定义Runnable接口的实现类,一样要重写run()方法,这个run()方法和Thread中的run()方法一样是线程的执行体
2】创建Runnable实现类的实例,并用这个实例作为Thread的target来创建Thread对象,这个Thread对象才是真正的线程对象
3】第三部依然是通过调用线程对象的start()方法来启动线程
代码实例:
public class MyThread2 implements Runnable {//实现Runnable接口
public void run(){
//重写run方法
}
}
public class Main {
public static void main(String[] args){
//创建并启动线程
MyThread2 myThread=new MyThread2();
Thread thread=new Thread(myThread);
thread().start();
//或者 new Thread(new MyThread2()).start();
}
}
------------------------使用Callable和Future创建线程---------------------
和Runnable接口不一样,Callable接口提供了一个call()方法作为线程执行体,call()方法比run()方法功能要强大。
》call()方法可以有返回值
》call()方法可以声明抛出异常
Java5提供了Future接口来代表Callable接口里call()方法的返回值,并且为Future接口提供了一个实现类FutureTask,这个实现类既实现了Future接口,还实现了Runnable接口,因此可以作为Thread类的target。在Future接口里定义了几个公共方法来控制它关联的Callable任务。
>boolean cancel(boolean mayInterruptIfRunning):视图取消该Future里面关联的Callable任务
>V get():返回Callable里call()方法的返回值,调用这个方法会导致程序阻塞,必须等到子线程结束后才会得到返回值
>V get(long timeout,TimeUnit unit):返回Callable里call()方法的返回值,最多阻塞timeout时间,经过指定时间没有返回抛出TimeoutException
>boolean isDone():若Callable任务完成,返回True
>boolean isCancelled():如果在Callable任务正常完成前被取消,返回True
介绍了相关的概念之后,创建并启动有返回值的线程的步骤如下:
1】创建Callable接口的实现类,并实现call()方法,然后创建该实现类的实例(从java8开始可以直接使用Lambda表达式创建Callable对象)。
2】使用FutureTask类来包装Callable对象,该FutureTask对象封装了Callable对象的call()方法的返回值
3】使用FutureTask对象作为Thread对象的target创建并启动线程(因为FutureTask实现了Runnable接口)
4】调用FutureTask对象的get()方法来获得子线程执行结束后的返回值
代码实例:
public class Main {
public static void main(String[] args){
MyThread3 th=new MyThread3();
//使用Lambda表达式创建Callable对象
//使用FutureTask类来包装Callable对象
FutureTask<Integer> future=new FutureTask<Integer>(
(Callable<Integer>)()->{
return 5;
}
);
new Thread(task,"有返回值的线程").start();//实质上还是以Callable对象来创建并启动线程
try{
System.out.println("子线程的返回值:"+future.get());//get()方法会阻塞,直到子线程执行结束才返回
}catch(Exception e){
ex.printStackTrace();
}
}
}
------------------------使用线程池例如用Executor框架---------------------
1.5后引入的Executor框架的最大优点是把任务的提交和执行解耦。要执行任务的人只需把Task描述清楚,然后提交即可。这个Task是怎么被执行的,被谁执行的,什么时候执行的,提交的人就不用关心了。具体点讲,提交一个Callable对象给ExecutorService(如最常用的线程池ThreadPoolExecutor),将得到一个Future对象,调用Future对象的get方法等待执行结果就好了。Executor框架的内部使用了线程池机制,它在java.util.cocurrent
包下,通过该框架来控制线程的启动、执行和关闭,可以简化并发编程的操作。因此,在Java
5之后,通过Executor来启动线程比使用Thread的start方法更好,除了更易管理,效率更好(用线程池实现,节约开销)外,还有关键的一点:有助于避免this逃逸问题——如果我们在构造器中启动一个线程,因为另一个任务可能会在构造器结束之前开始执行,此时可能会访问到初始化了一半的对象用Executor在构造器中。
Executor框架包括:线程池,Executor,Executors,ExecutorService,CompletionService,Future,Callable等。
Executor接口中之定义了一个方法execute(Runnable command),该方法接收一个Runable实例,它用来执行一个任务,任务即一个实现了Runnable接口的类。ExecutorService接口继承自Executor接口,它提供了更丰富的实现多线程的方法,比如,ExecutorService提供了关闭自己的方法,以及可为跟踪一个或多个异步任务执行状况而生成 Future 的方法。 可以调用ExecutorService的shutdown()方法来平滑地关闭 ExecutorService,调用该方法后,将导致ExecutorService停止接受任何新的任务且等待已经提交的任务执行完成(已经提交的任务会分两类:一类是已经在执行的,另一类是还没有开始执行的),当所有已经提交的任务执行完毕后将会关闭ExecutorService。因此我们一般用该接口来实现和管理多线程。
ExecutorService的生命周期包括三种状态:运行、关闭、终止。创建后便进入运行状态,当调用了shutdown()方法时,便进入关闭状态,此时意味着ExecutorService不再接受新的任务,但它还在执行已经提交了的任务,当素有已经提交了的任务执行完后,便到达终止状态。如果不调用shutdown()方法,ExecutorService会一直处在运行状态,不断接收新的任务,执行新的任务,服务器端一般不需要关闭它,保持一直运行即可。
Executors提供了一系列工厂方法用于创先线程池,返回的线程池都实现了ExecutorService接口。
public static ExecutorService newFixedThreadPool(int nThreads)
创建固定数目线程的线程池。
public static ExecutorService newCachedThreadPool()
创建一个可缓存的线程池,调用execute将重用以前构造的线程(如果线程可用)。如果现有线程没有可用的,则创建一个新线 程并添加到池中。终止并从缓存中移除那些已有 60 秒钟未被使用的线程。
public static ExecutorService newSingleThreadExecutor()
创建一个单线程化的Executor。
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)
创建一个支持定时及周期性的任务执行的线程池,多数情况下可用来替代Timer类。
这四种方法都是用的Executors中的ThreadFactory建立的线程,下面就以上四个方法做个比较
newCachedThreadPool() |
-缓存型池子,先查看池中有没有以前建立的线程,如果有,就 reuse.如果没有,就建一个新的线程加入池中 -缓存型池子通常用于执行一些生存期很短的异步型任务 因此在一些面向连接的daemon型SERVER中用得不多。但对于生存期短的异步任务,它是Executor的首选。 -能reuse的线程,必须是timeout IDLE内的池中线程,缺省 timeout是60s,超过这个IDLE时长,线程实例将被终止及移出池。 注意,放入CachedThreadPool的线程不必担心其结束,超过TIMEOUT不活动,其会自动被终止。 |
newFixedThreadPool(int) |
-newFixedThreadPool与cacheThreadPool差不多,也是能reuse就用,但不能随时建新的线程 -其独特之处:任意时间点,最多只能有固定数目的活动线程存在,此时如果有新的线程要建立,只能放在另外的队列中等待,直到当前的线程中某个线程终止直接被移出池子 -和cacheThreadPool不同,FixedThreadPool没有IDLE机制(可能也有,但既然文档没提,肯定非常长,类似依赖上层的TCP或UDP IDLE机制之类的),所以FixedThreadPool多数针对一些很稳定很固定的正规并发线程,多用于服务器 -从方法的源代码看,cache池和fixed 池调用的是同一个底层 池,只不过参数不同: fixed池线程数固定,并且是0秒IDLE(无IDLE) cache池线程数支持0-Integer.MAX_VALUE(显然完全没考虑主机的资源承受能力),60秒IDLE |
| newScheduledThreadPool(int) |
-调度型线程池 -这个池子里的线程可以按schedule依次delay执行,或周期执行 |
| SingleThreadExecutor() |
-单例线程,任意时间池中只能有一个线程 -用的是和cache池和fixed池相同的底层池,但线程数目是1-1,0秒IDLE(无IDLE) |
一般来说,CachedTheadPool在程序执行过程中通常会创建与所需数量相同的线程,然后在它回收旧线程时停止创建新线程,因此它是合理的Executor的首选,只有当这种方式会引发问题时(比如需要大量长时间面向连接的线程时),才需要考虑用FixedThreadPool。(该段话摘自《Thinking in Java》第四版)
Executor执行Runnable任务
通过Executors的以上四个静态工厂方法获得 ExecutorService实例,而后调用该实例的execute(Runnable command)方法即可。一旦Runnable任务传递到execute()方法,该方法便会自动在一个线程上


[java] view pl
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class TestCachedThreadPool{
public static void main(String[] args){
ExecutorService executorService = Executors.newCachedThreadPool();
// ExecutorService executorService = Executors.newFixedThreadPool(5);
// ExecutorService executorService = Executors.newSingleThreadExecutor();
for (int i = 0; i < 5; i++){
executorService.execute(new TestRunnable());
System.out.println("************* a" + i + " *************");
}
executorService.shutdown();
}
}
class TestRunnable implements Runnable{
public void run(){
System.out.println(Thread.currentThread().getName() + "线程被调用了。");
}
}
某次执行后的结果如下:
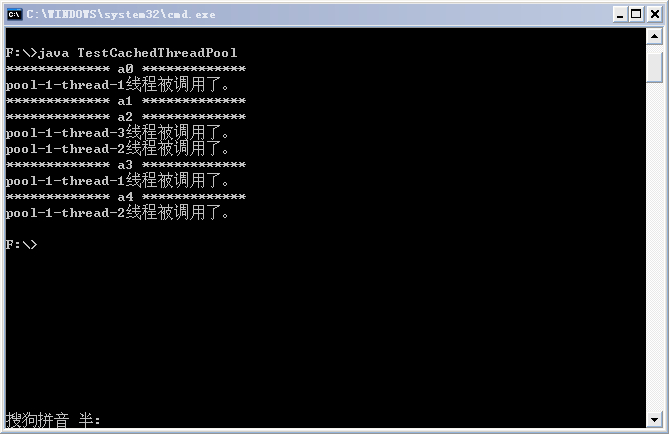
从结果中可以看出,pool-1-thread-1和pool-1-thread-2均被调用了两次,这是随机的,execute会首先在线程池中选择一个已有空闲线程来执行任务,如果线程池中没有空闲线程,它便会创建一个新的线程来执行任务。
Executor执行Callable任务
在Java 5之后,任务分两类:一类是实现了Runnable接口的类,一类是实现了Callable接口的类。两者都可以被ExecutorService执行,但是Runnable任务没有返回值,而Callable任务有返回值。并且Callable的call()方法只能通过ExecutorService的submit(Callable<T> task) 方法来执行,并且返回一个 <T>Future<T>,是表示任务等待完成的 Future。
Callable接口类似于Runnable,两者都是为那些其实例可能被另一个线程执行的类设计的。但是 Runnable 不会返回结果,并且无法抛出经过检查的异常而Callable又返回结果,而且当获取返回结果时可能会抛出异常。Callable中的call()方法类似Runnable的run()方法,区别同样是有返回值,后者没有。
当将一个Callable的对象传递给ExecutorService的submit方法,则该call方法自动在一个线程上执行,并且会返回执行结果Future对象。同样,将Runnable的对象传递给ExecutorService的submit方法,则该run方法自动在一个线程上执行,并且会返回执行结果Future对象,但是在该Future对象上调用get方法,将返回null。
下面给出一个Executor执行Callable任务的示例代码:
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.*;
public class CallableDemo{
public static void main(String[] args){
ExecutorService executorService = Executors.newCachedThreadPool();
List<Future<String>> resultList = new ArrayList<Future<String>>();
//创建10个任务并执行
for (int i = 0; i < 10; i++){
//使用ExecutorService执行Callable类型的任务,并将结果保存在future变量中
Future<String> future = executorService.submit(new TaskWithResult(i));
//将任务执行结果存储到List中
resultList.add(future);
}
//遍历任务的结果
for (Future<String> fs : resultList){
try{
while(!fs.isDone);//Future返回如果没有完成,则一直循环等待,直到Future返回完成
System.out.println(fs.get()); //打印各个线程(任务)执行的结果
}catch(InterruptedException e){
e.printStackTrace();
}catch(ExecutionException e){
e.printStackTrace();
}finally{
//启动一次顺序关闭,执行以前提交的任务,但不接受新任务
executorService.shutdown();
}
}
}
}
class TaskWithResult implements Callable<String>{
private int id;
public TaskWithResult(int id){
this.id = id;
}
/**
* 任务的具体过程,一旦任务传给ExecutorService的submit方法,
* 则该方法自动在一个线程上执行
*/
public String call() throws Exception {
System.out.println("call()方法被自动调用!!! " + Thread.currentThread().getName());
//该返回结果将被Future的get方法得到
return "call()方法被自动调用,任务返回的结果是:" + id + " " + Thread.currentThread().getName();
}
}
某次执行结果如下:
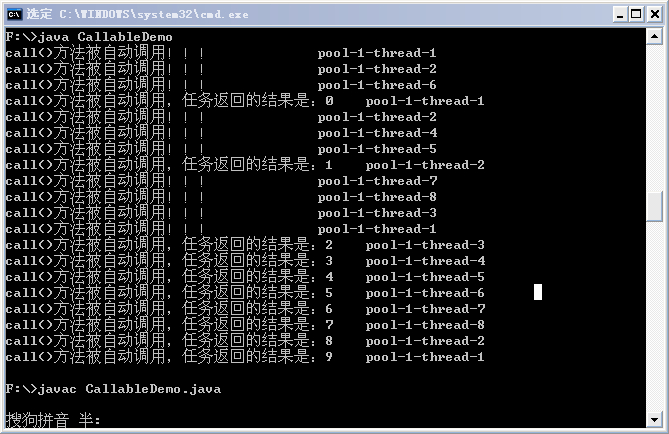
从结果中可以同样可以看出,submit也是首先选择空闲线程来执行任务,如果没有,才会创建新的线程来执行任务。另外,需要注意:如果Future的返回尚未完成,则get()方法会阻塞等待,直到Future完成返回,可以通过调用isDone()方法判断Future是否完成了返回。
自定义线程池
自定义线程池,可以用ThreadPoolExecutor类创建,它有多个构造方法来创建线程池,用该类很容易实现自定义的线程池,这里先贴上示例程序:import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadPoolTest{
public static void main(String[] args){
//创建等待队列
BlockingQueue<Runnable> bqueue = new ArrayBlockingQueue<Runnable>(20);
//创建线程池,池中保存的线程数为3,允许的最大线程数为5
ThreadPoolExecutor pool = new ThreadPoolExecutor(3,5,50,TimeUnit.MILLISECONDS,bqueue);
//创建七个任务
Runnable t1 = new MyThread();
Runnable t2 = new MyThread();
Runnable t3 = new MyThread();
Runnable t4 = new MyThread();
Runnable t5 = new MyThread();
Runnable t6 = new MyThread();
Runnable t7 = new MyThread();
//每个任务会在一个线程上执行
pool.execute(t1);
pool.execute(t2);
pool.execute(t3);
pool.execute(t4);
pool.execute(t5);
pool.execute(t6);
pool.execute(t7);
//关闭线程池
pool.shutdown();
}
}
class MyThread implements Runnable{
@Override
public void run(){
System.out.println(Thread.currentThread().getName() + "正在执行。。。");
try{
Thread.sleep(100);
}catch(InterruptedException e){
e.printStackTrace();
}
}
}
运行结果如下:

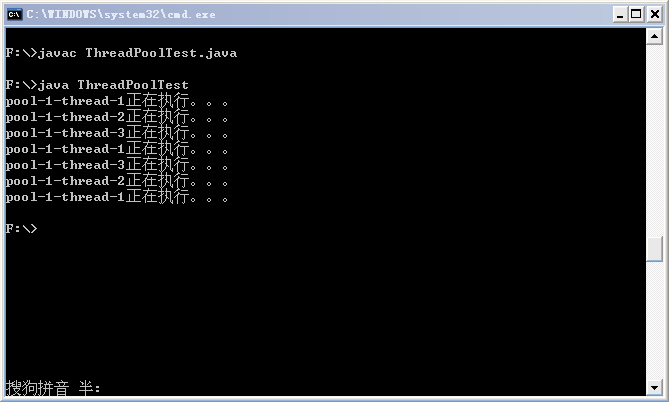
从结果中可以看出,七个任务是在线程池的三个线程上执行的。这里简要说明下用到的ThreadPoolExecuror类的构造方法中各个参数的含义。
public ThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit,BlockingQueue<Runnable> workQueue)
corePoolSize:线程池中所保存的线程数,包括空闲线程。
maximumPoolSize:池中允许的最大线程数。
keepAliveTime:当线程数大于核心数时,该参数为所有的任务终止前,多余的空闲线程等待新任务的最长时间。
unit:等待时间的单位。
workQueue:任务执行前保存任务的队列,仅保存由execute方法提交的Runnable任务。
--------------------------------------四种创建线程方法对比--------------------------------------
实现Runnable和实现Callable接口的方式基本相同,不过是后者执行call()方法有返回值,后者线程执行体run()方法无返回值,因此可以把这两种方式归为一种这种方式与继承Thread类的方法之间的差别如下:
1、线程只是实现Runnable或实现Callable接口,还可以继承其他类。
2、这种方式下,多个线程可以共享一个target对象,非常适合多线程处理同一份资源的情形。
3、但是编程稍微复杂,如果需要访问当前线程,必须调用Thread.currentThread()方法。
4、继承Thread类的线程类不能再继承其他父类(Java单继承决定)。
5、前三种的线程如果创建关闭频繁会消耗系统资源影响性能,而使用线程池可以不用线程的时候放回线程池,用的时候再从线程池取,项目开发中主要使用线程池
注:在前三种中一般推荐采用实现接口的方式来创建多线程

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步