

一致性hash算法应用场景、详解与实现(JAVA)
一、概述
在分布式环境下,开发者通常会遇到一些分布存储的场景,例如数据库的分库分表(比如用户id尾号为1的放入数据库1,id尾号为2的放入数据库2);又如分布式缓存数据的获取(比如根据ip地址进行缓存数据的分布存放)。在这种情况下,如何快速的将数据放入指定的位置,又如何快速获取是个最基本的要求,对于这种实现,有以下两种常用的方式:
1、配置中心拉取:这种情况下,数据的路由都会通过这一个中心节点取拉起配置,具体的方式如下:
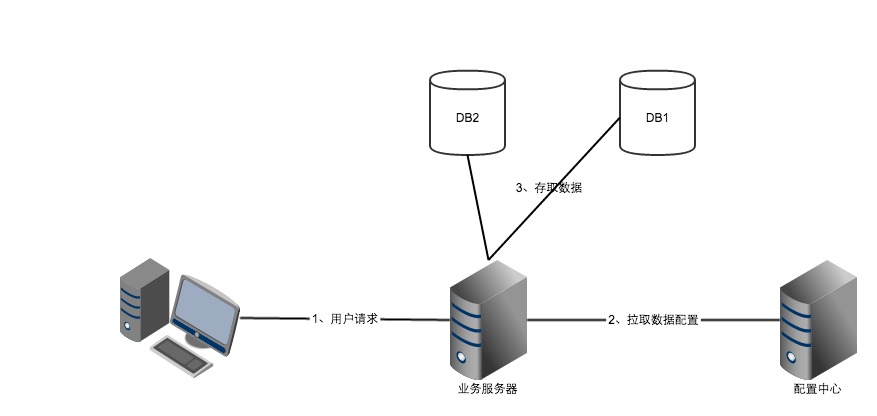
这种模式下的优点和缺点都很明显,优点就是方便维护,后面弹性扩展都只需要对配置中心数据进行操作即可,能够做到动态的完成DB的扩容等一些列问题。缺点就是这种情况下配置中心万一出现问题,后果是灾难性的,容易有单点故障,而且等到后续数据量特别巨大的时候,配置中心有可能本身会变成改系统的瓶颈。
2、对于需要操作的数据,通过一个确定的规则产生一个key,然后根据这个key进行一定的规则运算,直接获取到具体的数据操作地址。本文接下来所阐述的一些算法,就是通过这种方式去实现的。
二、数据分发的方式。
对于最简单的数据分发方式,当然是通过取余算法来进行分发,这样能够保证最终的数据充分的均匀。但是这种情况下,在发生设备增加和减少的情况,会直接导致命中率急剧下降。
