利用python分析创造营2020选手情况
一 去腾讯官网获取选手的照片和姓名
https://m.v.qq.com/activity/h5/303_index/index.html?ovscroll=0&autoplay=1&actityId=107015 官网
用谷歌打开这个网站,如果所示,去获取数据的网址
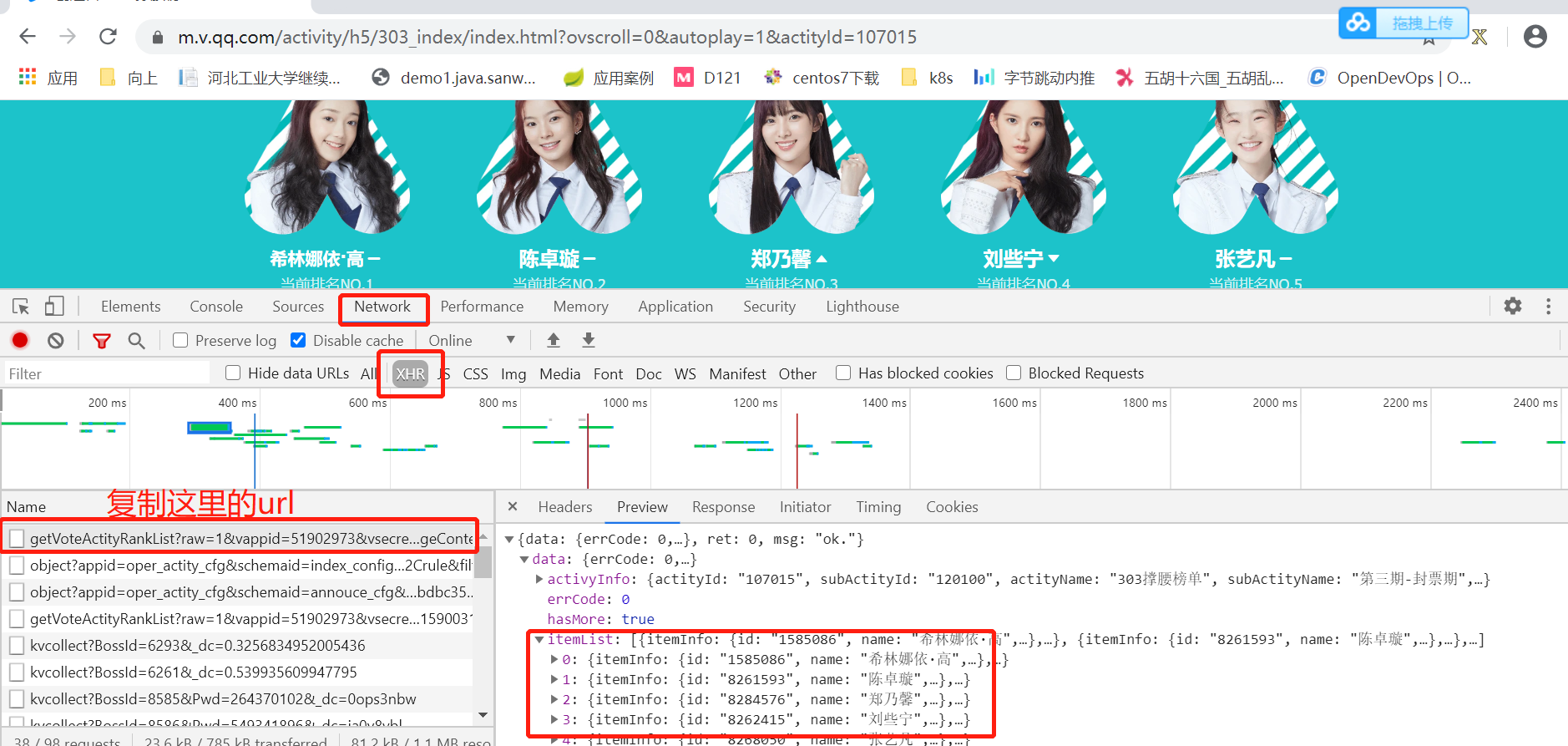
代码如下:
# 导入库
import pandas as pd
import requests
import json
def get_tx_actors():
"""
获取资料地址:https://m.v.qq.com/activity/h5/303_index/index.html?ovscroll=0&autoplay=1&actityId=107015
"""
# 获取URL
url = 'https://zbaccess.video.qq.com/fcgi/getVoteActityRankList?raw=1&vappid=51902973&vsecret=14816bd3d3bb7c03d6fd123b47541a77d0c7ff859fb85f21&actityId=107015&pageSize=101&vplatform=3&listFlag=0&pageContext=&ver=1&_t=1589598410618&_=1589598410619'
# 添加headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
# 发起请求
response = requests.get(url, headers=headers)
# 解析数据
json_data = json.loads(response.text)
# 提取选手信息
player_infos = json_data['data']['itemList']
# 提取信息
names = [i['itemInfo'].get('name') for i in player_infos]
rank_num = [i['rankInfo'].get('rank') for i in player_infos]
images = [i['itemInfo']['mapData'].get('poster_pic') for i in player_infos]
# 保存信息
df = pd.DataFrame({
'names': names,
'rank_num': rank_num,
'images': images
})
return df
# 运行函数
df = get_tx_actors()
df.to_csv('./data/腾讯选手信息111.csv', index=False,encoding="utf-8")
def download_img():
"""
功能:下载图片,为了后期给百度AI分析
"""
# 下载图片
for name, image in zip(df['names'], df['images']):
# 请求图片url
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
r = requests.get(image, headers=headers)
# 创建新的图片
f = open('./photo/{}.png'.format(name), 'wb')
# 写入图片内容
f.write(r.content)
# 关闭
f.close()
# 下载图片
download_img()
二 维基百科获取选手的身高和籍贯等信息
# 导入包
import pandas as pd
from selenium import webdriver
import time
def get_wiki_infos():
"""
功能:使用selenium获取维基百科信息(备注:需要可以登录外网)
"""
# 启动chrome
# browser = webdriver.Chrome()
browser = webdriver.Chrome(executable_path=r'./chromedriver_win32/chromedriver.exe')
# 维基URL
# url = 'https://zh.wikipedia.org/wiki/%E5%88%9B%E9%80%A0%E8%90%A52020'
url = 'https://img.xileso.top/wiki/%E5%88%9B%E9%80%A0%E8%90%A52020'
# 进入URL
browser.get(url)
# 休眠3秒
time.sleep(3)
# 获取姓名
names = [i.text for i in browser.find_elements_by_xpath('//*[@id="collapsibleTable0"]/tbody/tr/td[1]')]
# 获取国籍/地区
region = [i.text for i in browser.find_elements_by_xpath('//*[@id="collapsibleTable0"]/tbody/tr/td[2]')]
# 获取出生日期
age = [i.text for i in browser.find_elements_by_xpath('//*[@id="collapsibleTable0"]/tbody/tr/td[3]')]
# 获取身高
height = [i.text for i in browser.find_elements_by_xpath('//*[@id="collapsibleTable0"]/tbody/tr/td[4]')]
# 获取经济公司
company = [i.text for i in browser.find_elements_by_xpath('//*[@id="collapsibleTable0"]/tbody/tr/td[5]')]
# 保存数据
df = pd.DataFrame({
'names': names,
'region': region,
'age': age,
'height': height,
'company': company
})
# 关闭chrome
browser.close()
return df
# 获取维基百科信息
df = get_wiki_infos()
# 读出数据
df.to_excel('./data/维基百科选手信息.xlsx', index=False)
三 颜值分析
这里我们要借助百度Ai的人脸识别,所以要先申请账号,详情见下面地址
https://ai.baidu.com/ai-doc/REFERENCE/Ck3dwjgn3 百度ai人脸识别使用
https://ai.baidu.com/ai-doc/REFERENCE/Ck3dwjhhu 如何获取token
# 导入包
import pandas as pd
import requests
# from 爬虫 import my_config
import base64
import os
import time
def get_access_token():
"""
功能:获取token信息
"""
# client_id 为官网获取的AK, client_secret 为官网获取的SK
client_id = "BoHP5cwZFd6swU4v2nPCNuTf"
client_secret = "GxmtjdwG0Lylk7LvR99Pw6GF1QIjkaKA"
# 请求url
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&' \
'client_id={}&client_secret={}'.format(client_id, client_secret)
response = requests.get(host)
if response:
return response.json()['access_token']
def get_file_content(file_path):
"""
功能:使用base64转换路径编码
"""
with open(file_path, 'rb') as fp:
content = base64.b64encode(fp.read())
return content.decode('utf-8')
def get_face_score(file_path):
"""
功能:调用api,实现一个百度的颜值分析器
"""
# 调用函数,获取image_code
image_code = get_file_content(file_path=file_path)
# 请求base_url
request_url = "https://aip.baidubce.com/rest/2.0/face/v3/detect"
# 请求头
params = {
'image':'{}'.format(image_code),
'image_type': 'BASE64',
'face_field': 'age,gender,beauty'
}
# 调用函数,获取token
my_access_token = get_access_token()
# 获取access_token
access_token = my_access_token
# 构建请求URL
request_url = request_url + "?access_token=" + access_token
# 请求头
headers = {'content-type': 'json'}
# 发起请求
response = requests.post(request_url, data=params, headers=headers)
if response:
print(response.json())
age = response.json()['result']['face_list'][0]['age']
gender = response.json()['result']['face_list'][0]['gender']['type']
gender_prob = response.json()['result']['face_list'][0]['gender']['probability']
beauty = response.json()['result']['face_list'][0]['beauty']
all_results = [age, gender, gender_prob, beauty]
return all_results
def get_players_score(photo_name_list):
"""
功能:给定photo_name_list,获取所有选手的AI评测结果
"""
player_name = []
age_all = []
gender_all = []
prob_all = []
beauty_all = []
step = 1
# 循环请求所有图片
for photo_name in photo_name_list:
# 打印进度
print('我正在获取第{}个选手{}的信息'.format(step, photo_name))
step += 1
# 文件路径
file_path = r"D:\python21\爬虫\photo\{}".format(photo_name)
# 获取分数
all_results = get_face_score(file_path=file_path)
# 获取年龄
age = all_results[0]
# 获取性别
gender = all_results[1]
# 获取性别预测概率
prob = all_results[2]
# 获取颜值
beauty = all_results[3]
# 追加
player_name.append(photo_name)
age_all.append(age)
gender_all.append(gender)
prob_all.append(prob)
beauty_all.append(beauty)
# 休眠一秒
time.sleep(1)
# 存储数据
df_res = pd.DataFrame({
'name': player_name,
'age': age_all,
'gender': gender_all,
'prob': prob_all,
'beauty': beauty_all
})
return df_res
# 获取name列表
photo_name_list = os.listdir('./photo')
df = get_players_score(photo_name_list=photo_name_list)
# 读出数据
df.to_csv('./data/百度颜值评分.xlsx', index=False)
四 数据合并
在上面的三个步骤,我们得到了三个数据表格,我们要把他们合并到一个表格里面,为了更好的分析
# 导入相关包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pyecharts.charts import Pie, Line, Map, Bar, Page
from pyecharts import options as opts
from pyecharts.globals import SymbolType
# 腾讯选手信息(姓名,照片)
df1 = pd.read_csv('D:/python21/爬虫/data/腾讯选手信息.csv',encoding='utf-8')
a=df1.head()
# 维基百科信息(身高,籍贯)
df2 = pd.read_excel('D:/python21/爬虫/data/维基百科选手信息.xlsx')
b=df2.head()
# 百度AI颜值评测(颜值评分)
df3 = pd.read_csv('D:\python21\爬虫\data\百度颜值评分.csv',encoding='utf-8')
# 重命名
df3.rename({'name': 'names', 'age': 'pred_age'}, axis=1, inplace=True)
# df3提取姓名
df3['names'] = df3.names.str.extract('([\u4e00-\u9fa5]+)')
c=df3.head()
# 提取分析列
df3 = df3[['names', 'pred_age', 'beauty']]
c=df3.head()
print(a)
##########################合并三个表格数据
# 合并宽表
# 先合并df1和df2
df_all = pd.merge(df1, df2, on='names', how='inner')
dd=df_all.head(2)
# 再合并df_all和df3
df_all = pd.merge(df_all, df3, on='names', how='inner')
df_all.head(5)
# 查看数据信息
df_all.info()
# height:提取数值
df_all['height'] = df_all.height.str.extract('(\d+)').astype('float')
df_all.head(2)
# # print(a)
# age: 提取年龄
df_all['age'] = df_all.age.str.extract('.*?((.*?)岁\)').astype('float')
a=df_all.head(2)
# print(a)
# 填充缺失值否则画图的时候会报错
df_all['age'].fillna(value=df_all.age.mean(), inplace=True)
df_all['height'].fillna(value=df_all.height.mean(), inplace=True)
# 读出处理后的数据,最终保存一个文件
df_all.to_csv('D:/python21/爬虫/data/df_dealedtt.csv', index=False,encoding='utf-8')
最终会生成一个这样的表数据,如下所示
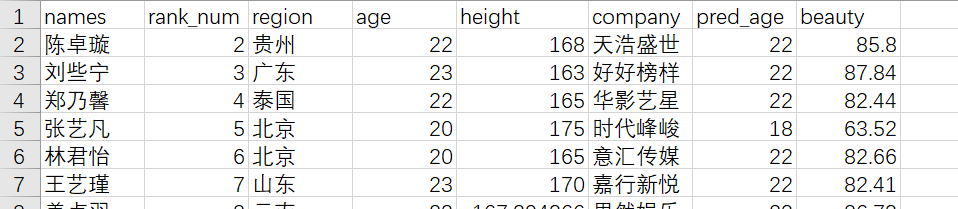
五 绘图
1 选手年龄分析
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pyecharts.charts import Pie, Line, Map, Bar, Page
from pyecharts import options as opts
from pyecharts.globals import SymbolType
df = pd.read_csv('D:/python21/爬虫/data/df_dealedtt.csv')
df_all = pd.read_csv('D:/python21/爬虫/data/df_dealedtt.csv')
print(df.head(12))
# 转换数据类型
df['age'] = df.age.astype('int')
df['height'] = df.height.astype('int')
# # print(df.info())
age_bins = [18,20,22,24,26]
age_labels = ['18-20', '20-22', '22-24', '24-26']
# 分箱
age_cut = pd.cut(df.age, bins=age_bins, labels=age_labels)
age_cut = age_cut.value_counts()
# 产生数据对
data_pair = [list(z) for z in zip(age_cut.index.tolist(), age_cut.values.tolist())]
##############选手年龄分布
# 绘制饼图
# {a}(系列名称),{b}(数据项名称),{c}(数值), {d}(百分比)
pie1 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))
pie1.add('', data_pair=data_pair, radius=['35%', '60%'])
pie1.set_global_opts(title_opts=opts.TitleOpts(title='选手年龄分布'),
legend_opts=opts.LegendOpts(orient='vertical', pos_top='15%', pos_left='2%'))
pie1.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
pie1.render("年龄.html")
最终会生成一个html格式的图形,如下所示
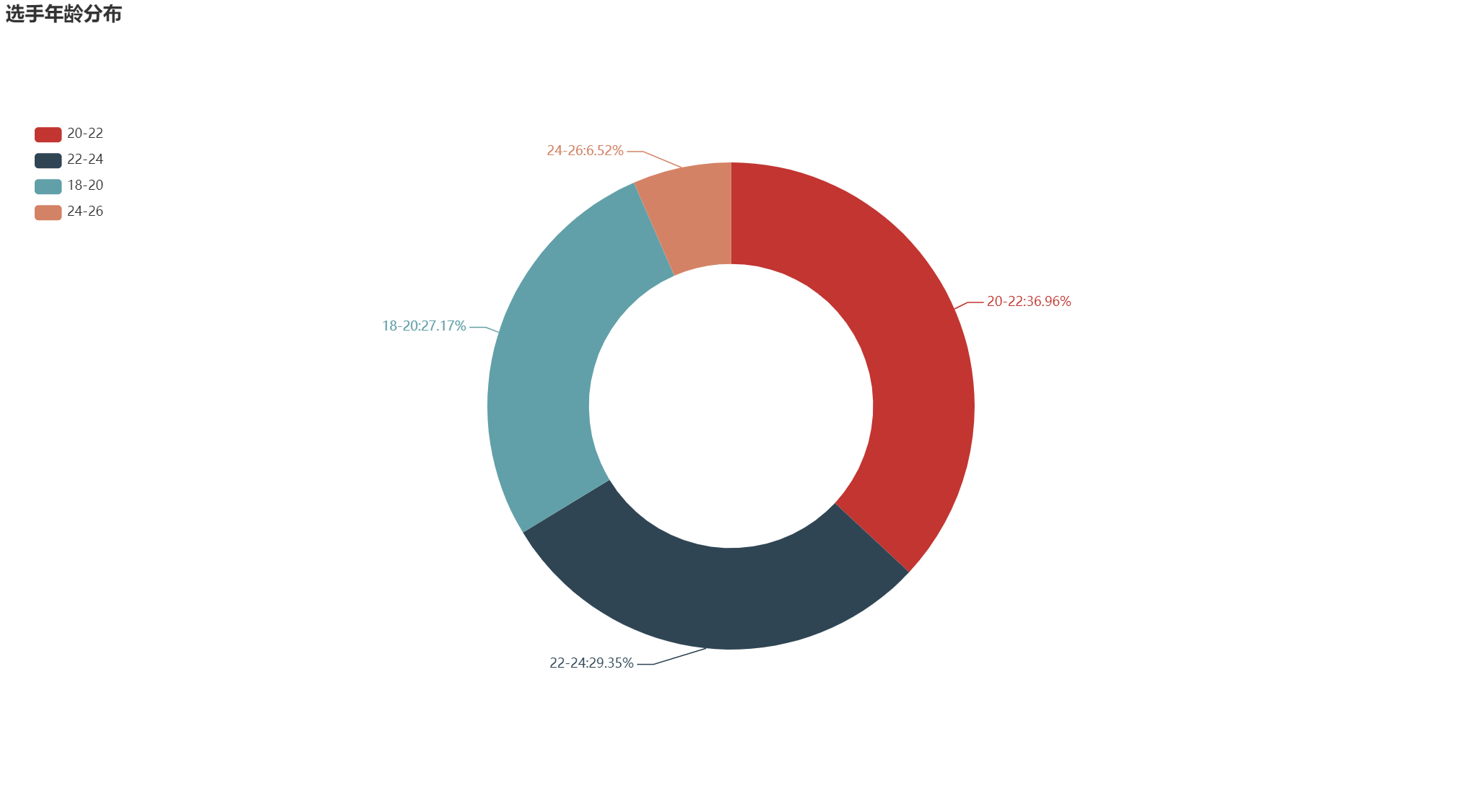
2 选手籍贯分布
city_num = df.region.value_counts()
city_num.head()
# 数据对
data_pair2 = [list(z) for z in zip(city_num.index.tolist(), city_num.values.tolist())]
# 绘制地图
map1 = Map(init_opts=opts.InitOpts(width='1350px', height='750px'))
map1.add('', data_pair2, maptype='china')
map1.set_global_opts(title_opts=opts.TitleOpts(title='选手的籍贯分布'),
visualmap_opts=opts.VisualMapOpts(max_=9))
map1.render("籍贯.html")
如下图所示:
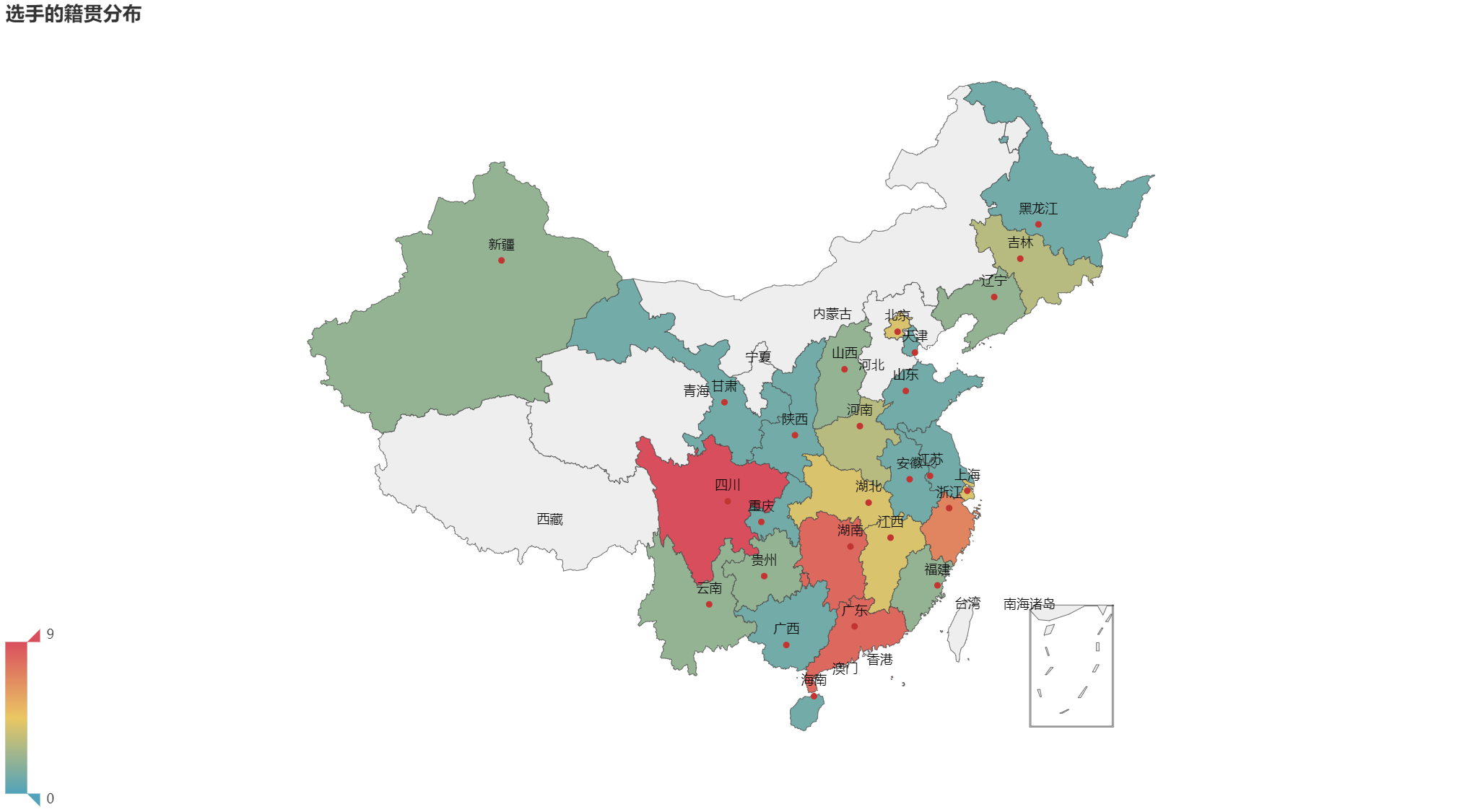
可以看出四川的选手最多。
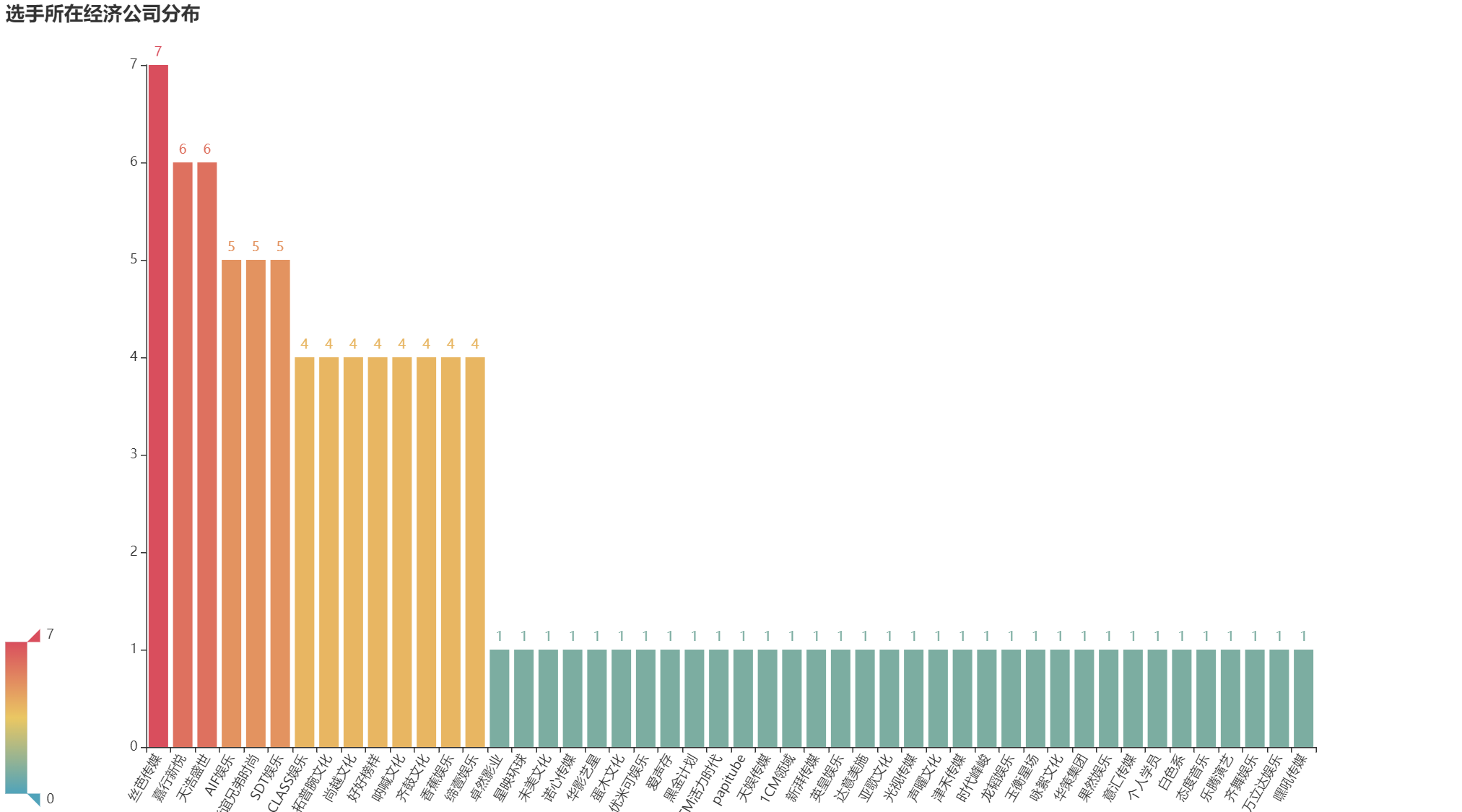
3 选手经济公司
company_num = df.company.value_counts(ascending=False)
company_num.head()
# 绘制柱形图
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(company_num.index.tolist())
bar1.add_yaxis('', company_num.values.tolist())
bar1.set_global_opts(title_opts=opts.TitleOpts(title='选手所在经济公司分布'),
visualmap_opts=opts.VisualMapOpts(max_=7),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate='60')),
)
bar1.render("经纪公司.html")
如下图:
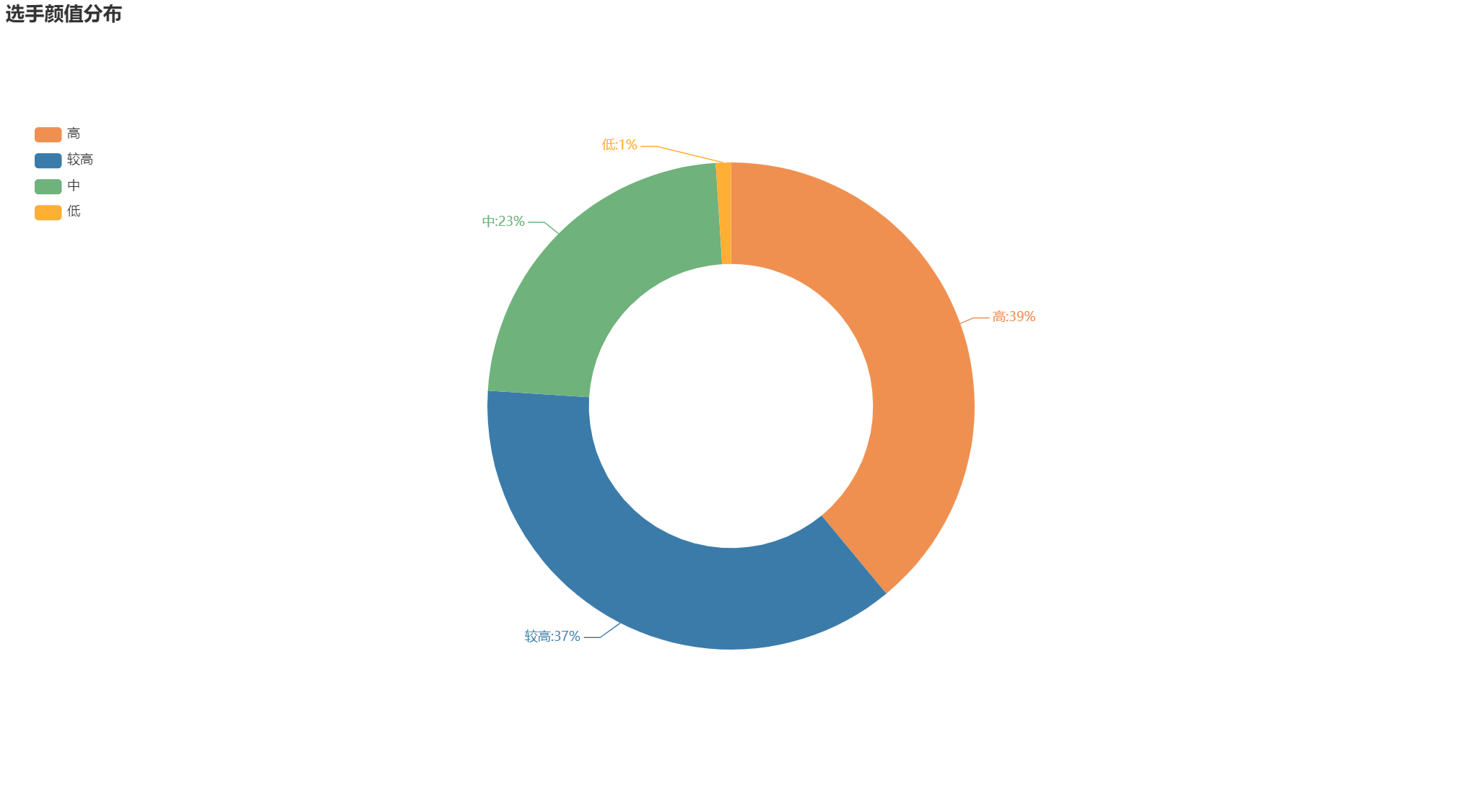
4 选手颜值分布
df_all.beauty.describe()
beauty_bins = [55,60,70,80,100]
beauty_labels = ['低', '中', '较高', '高']
# 分箱
beauty_num = pd.cut(df.beauty, bins=beauty_bins, labels=beauty_labels)
beauty_num = beauty_num.value_counts()
data_pair3 = [list(z) for z in zip(beauty_num.index.tolist(), beauty_num.values.tolist())]
# 绘制饼图
pie2 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))
pie2.add('', data_pair=data_pair3, radius=['35%', '60%'])
pie2.set_global_opts(title_opts=opts.TitleOpts(title='选手颜值分布'),
legend_opts=opts.LegendOpts(orient='vertical', pos_top='15%', pos_left='2%'))
pie2.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
pie2.set_colors(['#EF9050', '#3B7BA9', '#6FB27C', '#FFAF34'])
pie2.render("颜值.html")
如下图所示
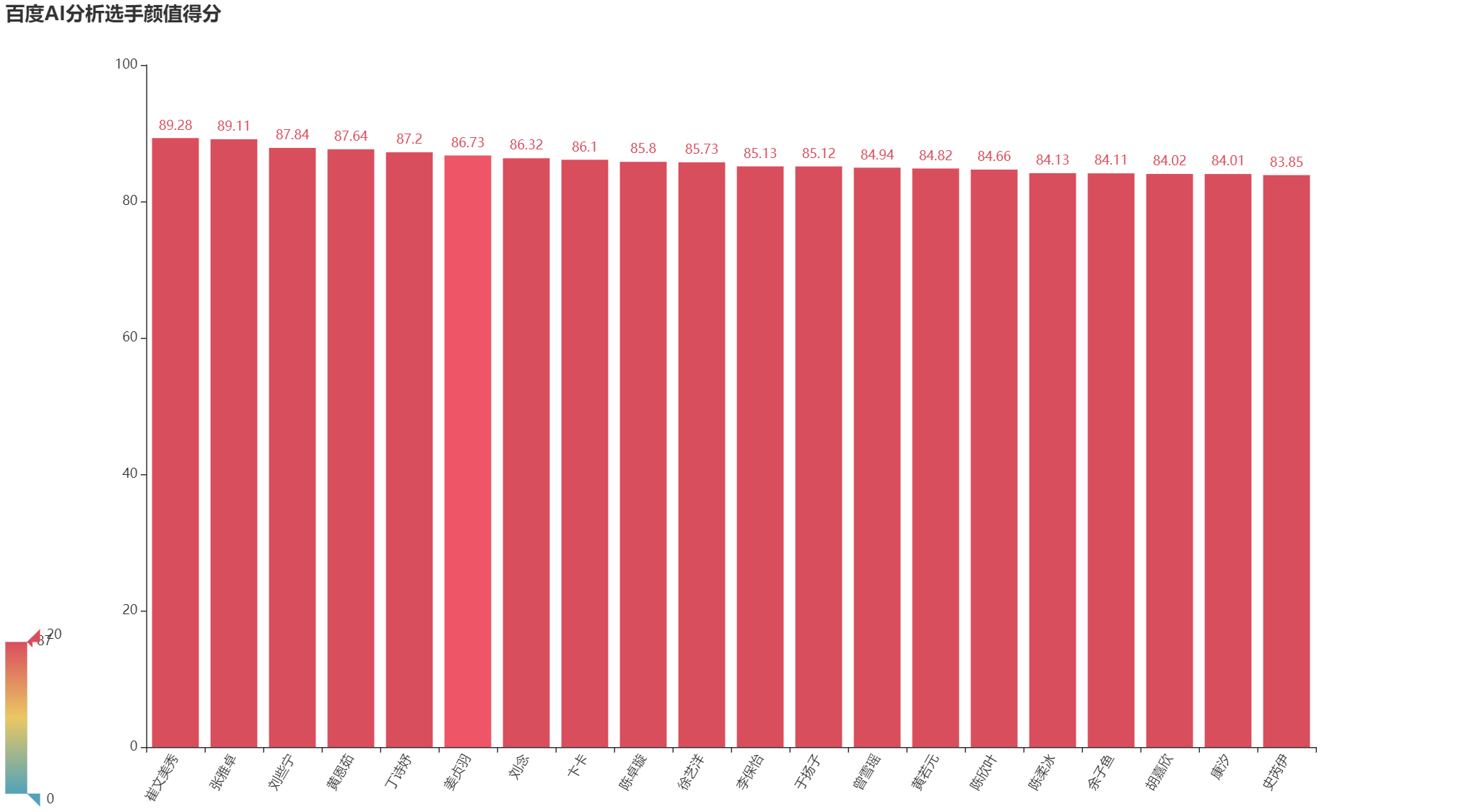
5 选手颜值排名
beauty = df.sort_values(by='beauty',ascending=False).head(20) # 设置读取多少个选手
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(beauty.names.tolist()) # x轴是姓名
bar1.add_yaxis('',beauty.beauty.tolist()) # y轴是颜值得分
bar1.set_global_opts(title_opts=opts.TitleOpts(title='百度AI分析选手颜值得分'),
visualmap_opts=opts.VisualMapOpts(max_=20),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate='60')),
)
bar1.render("选手颜值排名.html")
如下图所示:
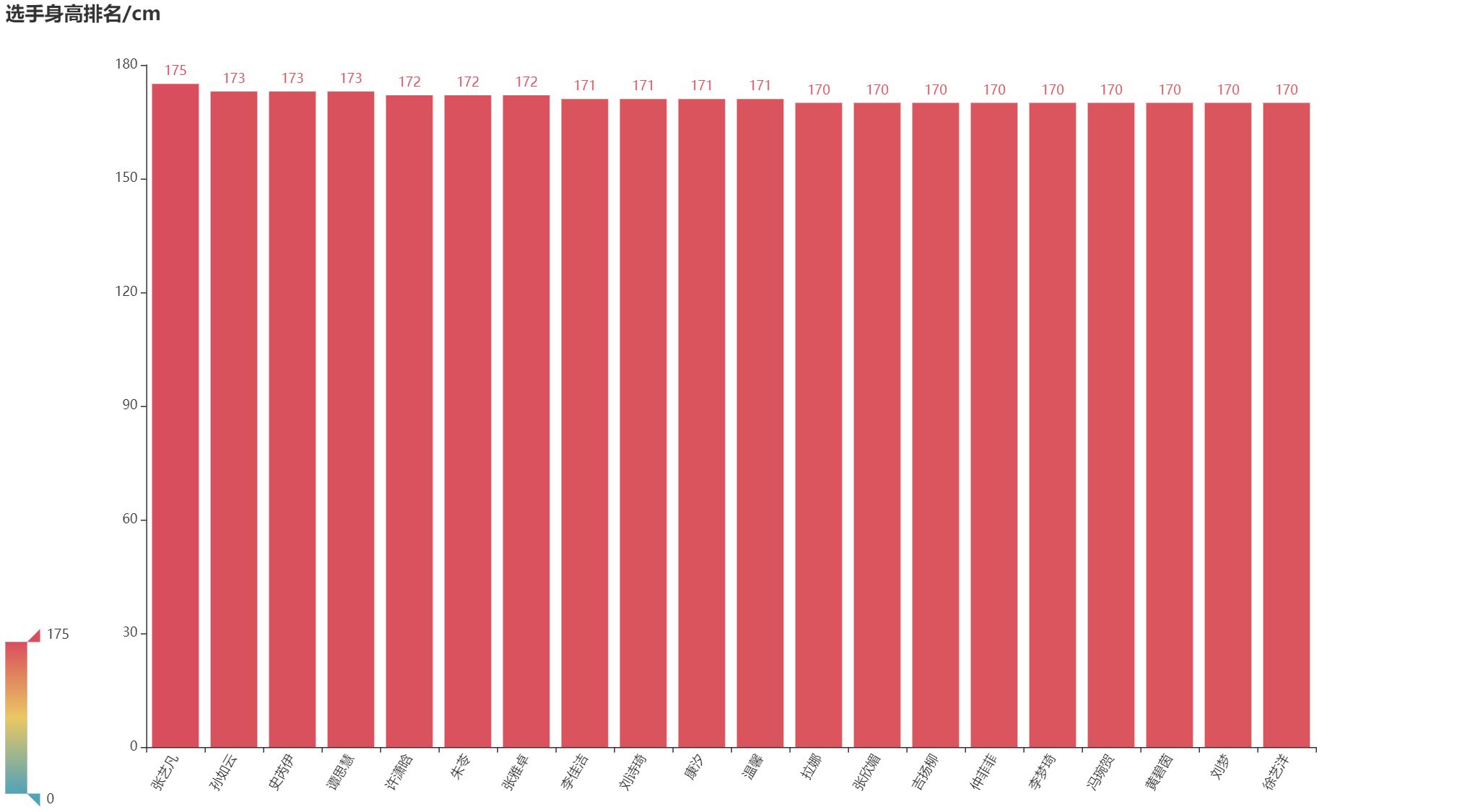
6 选手身高排名
height_num = df.sort_values(by='height',ascending=False).head(20) # 设置读取多少个选手
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(height_num.names.tolist()) # x轴是姓名
bar1.add_yaxis('',height_num.height.tolist()) # y轴是身高得分
bar1.set_global_opts(title_opts=opts.TitleOpts(title='选手身高排名/cm'),
visualmap_opts=opts.VisualMapOpts(max_=175),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate='60')),
)
bar1.render("选手身高排名.html")
如下图所示:
7 获得一个整体图形
page = Page()
page.add(pie1, pie2, map1, bar1)
page.render('创造营2020选手分析数据可视化.html')
就是把上面的四张图,全部放到同一个页面上面。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号