
初步了解内存机制
对于计算机来说,存储数据时通过申请内存来实现的,如果我们的数据是水的话,内存就是容器。对于int型的数据,需要以32bit大小的内存存储,对于字符串类型的需要8bit个单位大小的内存。

但是申请内存的时候到底是一个什么样的机制呢?或者是怎么保存的机制呢?我们还是以水和容器的例子来表达。在计算机中,内存是存在地址的,或者说是,容器是按照一定的顺序排列好的。当你申请需要存储的时候,就会给系列的容器。对于计算机来说,申请内存是需要耗费比较多的时间的是,所以如果我们能合理的根据我们的数据的大小,一次性给予一个合适大小的内存,或者申请内存的次数少一些,那么对于内存使用的效率来说是有极大的好处的。
所以我们可与i使用这样的方法,申请一部分内存,头部的两个节点用于保存和这部分内存信息相关的内容

这样我们就知道了我们申请了多大的内存,以及已经使用了多大的内存。
此时,我们考虑另外一个问题,如果内存里面存储的数据的类型是不一致的呢?例如,0位置储存的是int型,1位置存储的是str类型的,那么占据的内存大小就不一样了,他们的地址就不是均匀递增的了。通俗来说,还是容器里面放水,如果我们设定的是每八个容器里放的就是同一种溶液,这样我们要找某种溶液,直接在第一种溶液的位置的基础上加n个8的就可以找到了。但是如果数据类型不一样,第一种溶液需要8个容器,第二种溶液需要16个,第三个需要4个,这样就很繁琐了,我们无法通过地址取找到对应的溶液。
由此,就引入了另外一种方式,叫做元素外置。我们将容器划分为两部分,第一部分用来存放地址,第二部分用来存放我们需要用的数据。怎么理解呢?我们知道,容器的地址也是int型的。我们可以先将存储的int型数据,str型数据,float型数据的地址全都提出来,然后将所以的地址全都放进容器里,这样就可以通过查找连续的地址,阿里找到对应的元素。
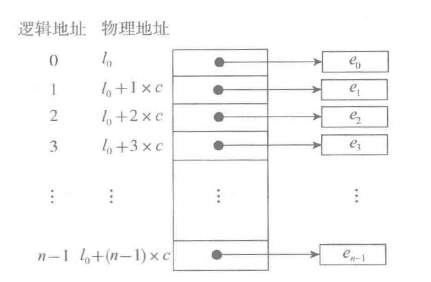
在解决了这个问题的基础上,我们考虑一下对内存里面的数据进行操作时候的难易程度,也就是时间复杂度。
- 查找下标为i的元素:知道地址可以直接访问,时间复杂度为O(1).
- 遍历操作:把所有元素都访问一遍,时间复杂度为O(n)。
- append:末尾添加一个元素/复杂度为o(1).
- pop():去掉末尾元素,直接访问最后一个元素,时间复杂度为o(1).
- pop(i):考虑最坏时间复杂度,也就是将第一个元素出来去掉,那么后面的所有的元素都要往前移动一个空格。时间复杂度为(n)。
- insert(i,item):在某个地址插入一个元素。也是考虑最坏时间复杂度。第一个位置插入一个元素,复杂度为n。
- contains(item):看是否包含某个元素。需要做一个遍历,时间复杂度为n。
- get slice(x:y):取地址x到y部分的元素。时间复杂度为(x-y)。
- set slice:设置某部分元素。考虑最坏时间复杂度,先设置前k个元素,原来的元素全部往后移动,所以时间复杂度为n+k。
- reverse:反转。时间复杂度为n。
- multiply:n个元素,乘以k个数。时间按复杂度为n*k。
- concatenate:代表使用的+, 把两个列表加到一起, k是第二个列表中的元素个数。时间复杂度为k。
- sorted:时间复杂度为nlogn。留疑问。
到目前来说,我们能发现,数据结构是用来研究如果更加高效的使用内存的一种工具,交叉了数学和信息这两个学科。但是这对于里面我们后面的算法有至关重要的作用。
