【mysql 】something about index
索引
索引是增长数据库查询效率的一种自排序的数据结构
在mysql中,是利用一种名为“B+ tree”的数据结构来组织索引数据的
大概如图所示:
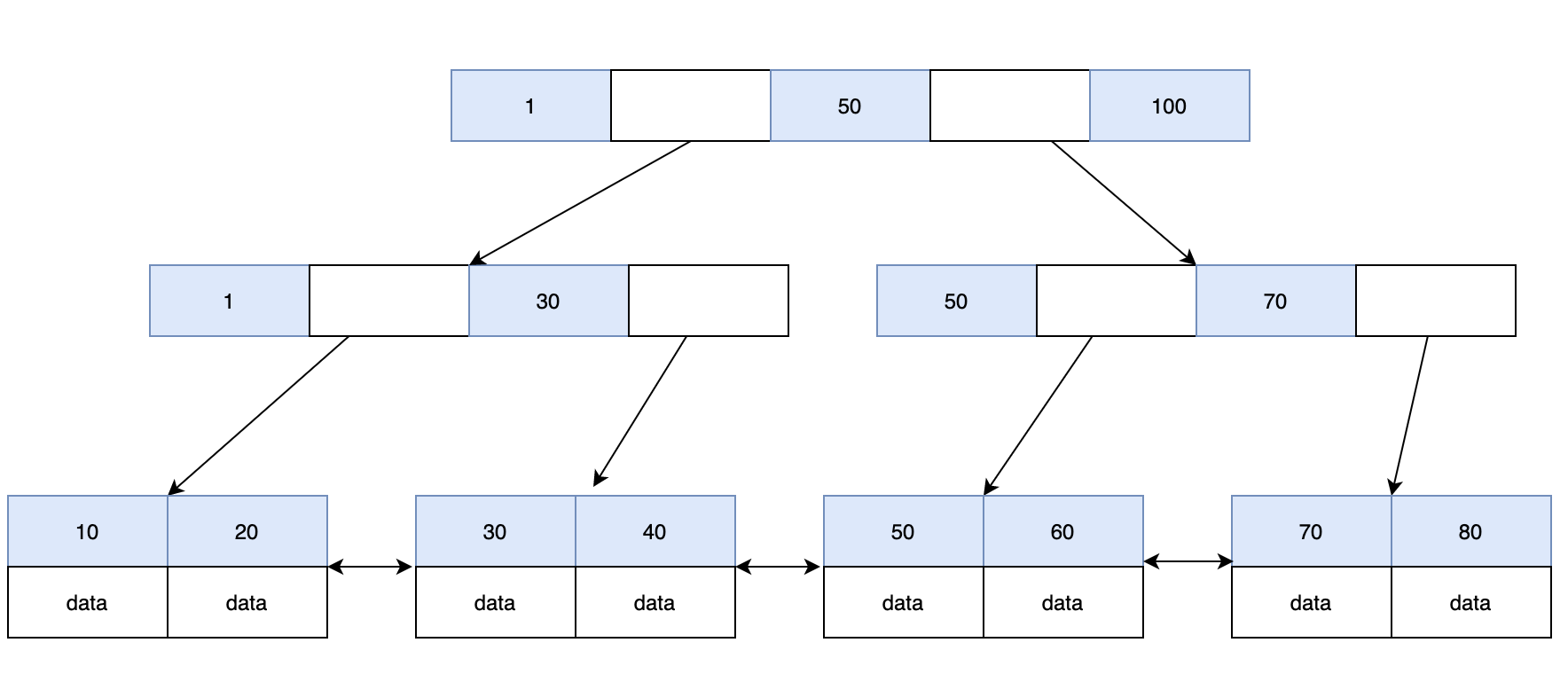
这种是二叉树,又不完全是二叉树的数据结构,最大的不同是尽可能在一个节点放置多的元素,从而来控制树的高度。树的高度越高,磁盘IO的开销就越多,查询效率随之降低,这就是mysql不用二叉树、红黑树来构建索引的原因。
那么用Hash表,或者b-树呢?
Hash这种数据结构查询效率固然很高,一次就可以定位到索引值,但是它无法支持范围查询,无法支持数据排序,不能很好的支持组合索引
b+树对b-树的优化,最大的不同点在于,b+树的节点中既存索引又存记录,b-树除了叶子节点以外只存索引,这样来看b+相对于b-,一页存储和读取的索引更多,单次磁盘IO的效率更高,磁盘IO次数也要降低。
还有,b+树的叶子节点通过双向指针维护了相邻两个节点的内存地址,b-树则没有这样的特征,这决定了b+树更好的支持了大范围查询。
聚集索引和非聚集索引
聚集和非聚集索引,是由索引是否和数据分离来决定的。
比如说myisam存储引擎,它的索引和数据是分开存放的,b+树的叶子节点与索引存放一起的是数据的访问地址。
对于Innodb来说,除了主键索引以外,其他二级索引都是非聚集索引,二级索引构建起来的b+树,叶子节点中与索引存放一起的是主键索引,相当于是通过二级普通索引先定位到主键索引,再根据主键索引查询到数据。这一过程也叫做回表。
那么如果建表没有指定主键,mysql底层将维护一个隐藏列来充当聚集索引。
不过照目前主流的开发规范,我们必须手动的指定一个自增的整型的字段来作为主键
mysql底层存储的基本单位是页,每页16kb,如果是自增的,insert的时候就可以按页连续写入了。如果不是自增,将会无休止的对主键值进行比较,哪怕是上一页填满了16kb,写入下一页的时候由于比较也要打乱上一页,这样在底层就增加了一些本可以避免的资源浪费。
联合索引
联合索引同样也是按b+树这种数据结构来构建的,都是一样的
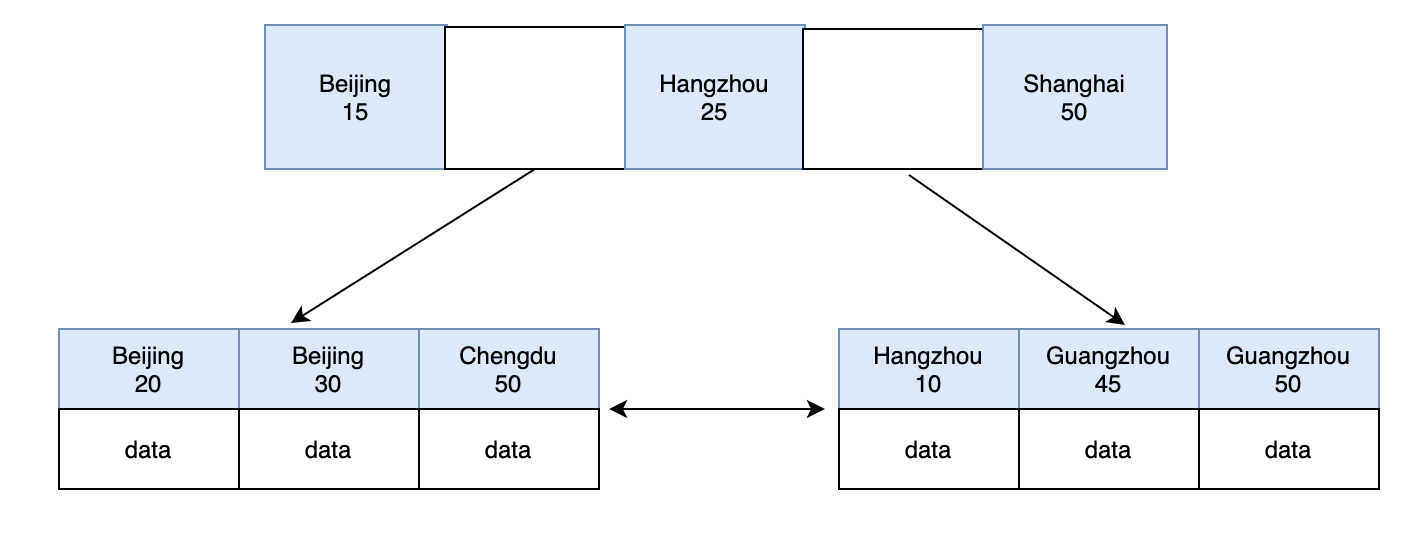
索引最左前缀原则
联合索引在插入的时候都是按照复合字段从左到右去排序的。查询也是左到右去匹配的,如果跳过最左字段去查表,势必要对全表进行扫描。
比如有一个name+age+role的联合索引,若按age+role去查询的话,只能保证name是正常排序的,无法保证age是不是排好序的,查询的时候要一个个比对,所以就不会走索引了。
一个问题
假如有一张表t1,主键是a,联合索引(b、c、d),看看以下sql会不会走索引
select * from t1 where b = 1;
select * from t1 where b > 1;
select b,c,d from t1 where b > 1;
select a,b,c,d from t1 where b > 1;
第1条走索引,第2条可能走,也可能不走,第3条走,第4条也走索引。
具体第2条为什么有时候会不走索引,这决定于回表的次数,如果只要少量的回表,那走索引查询效率高。如果需要大量的回表次数,那全表扫描比索引查询更优
