Turbo codes 浅学习
Turbo codes
在1993年于瑞士日内瓦召开的国际通信会议(ICC'93)上,两位任教于法国不列颠通信大学的教授C.Berrou、A.Glavieux和他们的缅甸籍博士生P.thitimajshima首次提出了一种新型信道编码方案——Turbo码,由于它很好地应用了shannon信道编码定理中的随机性编、译码条件,从而获得了几乎接近shannon理论极限的译码性能。
Turbo码又称并行级联卷积码(PCCC,Parallel Concatenated Convolutional Code)。它巧妙的将卷积码和随机交织器结合器结合,在实现了随机编码的思想的同时,也通过交织器实现了短码构造长码的方法,并且采用软输出(与硬输出不同,软输出不仅包含本次译码对接收码字的硬估值,而且给出这些估计值的可信度,软输出用似然度表示)迭代译码来逼近最大似然译码。
Turbo码的编码
Turbo码的编码结构可以分为并行级联卷积码(PCCC)、串行级联卷积码(SCCC)、和混合型级联卷积码(HCCC)。主要学习并行级联卷积码,另外两种不予详细学习。
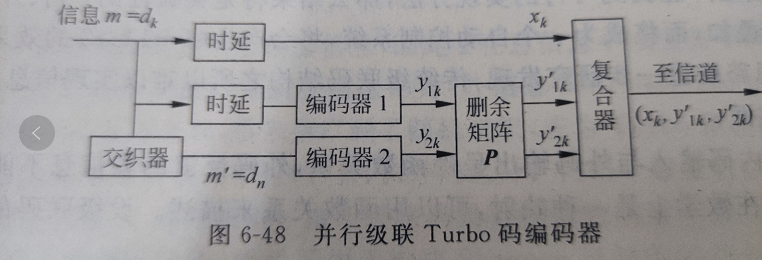
PCCC结构主要有分量编码器、交织器、删余矩阵(穿刺矩阵)和复接器组成。分量器一般选择递归系统卷积码(RSC)。通常两个分量码采用相同的生成矩阵(也可不同)。如果两个分量码的码率分别是\(R_1\)和\(R_2\),那么Turbo码的码率为
输入信息\(m=d_k\)并行的分成三支,分别处理后得到信息码\(x_k\)、删除后的校验码\(y'_{1k}\)和\(y'_{2k}\),再通过复合器合称为一个信息发送。第一支是直通通道,由于未作任何处理,所以时间是要比下面分支快,所以加上一个时延器,保证与下面的经交织、编码处理后的信息在时间是匹配。第二支经过时延、编码、删余处理后送入复合器。第三支经交织、编码、删余处理后送入复合器。编码器1、2叫做自编码器,也叫分量码,一般多去两者相同。交织的目的是随机化(交织器即将原始数据顺序按照给定的规则重新排序输出),是为了改变码重分布。
删余是通过删除冗余的校验位来调整码率。两分量码产生的校验位是对同一组信息(尽管信息进行了交织)的校验,它的数量是一个分组码的两倍,导致码率降低。这时考虑只传输其中的一部分,原则是不能完全排斥两个分量码中的任何一个,而是折中的按照一定规律的轮流选择发送两分量码的校验比特。
借助删余码可以用比较简单的编、译码器(比如1/2卷积码)实现较高的码率(比如\(R = 6/7\))的编、译码。一般来说,\(R = k/n\)编码器的每一状态要进行\(2^k\)次比较。如果用1/2编码器产生6/12码,然后将他缩短为6/7码,比用6/7编码器直接编、译码要简单些。这就是Turbo码中广泛应用删余技术的原因。
Turbo码的译码
Turbo码的译码器采用反馈结构,以迭代方式译码。与Turbo编码器的两个分量码相对应,译码端应该有两个分量译码器。Turbo码并行级联译码器如下图所示

接收到的数据流中包含三个部分:信息码\(x_k\),编码器1产生的校验码\(y'_{1k}\)(经删余)和编码器2产生的校验码\(y'_{2k}\)(经删余).在译码前首先要进行数据的分离:与发送端复合器逆向功能的分接处理,将数据流还原成\(x_k\)、\(y'_{1k}\)、\(y'_{2k}\)三路信息。发送端子编码器1,2的校验码由于删余并没有全部传送过来,\(y'_{1k}\)、\(y'_{2k}\)只是\(y_{1k}\)、\(y_{2k}\)的部分信息,分接后的校验序列的部分比特没有数据,这样就必须根据删余的规律对接收的校验序列进行内插,在被删除的数据位上补零,以保证序列的完整性。
Turbo码译码器包含两个独立的子译码器,记作DEC1、DEC2,与编码器的子编码器1、子编码器2对应。DEC1、DEC2都采用软输入、软输出的迭代译码算法。每次迭代有三路信息输入:一是信息码\(x_k\);二是校验码\(y_{1k}\)或\(y_{2k}\);三是外信息。也称为边信息或附加信息。Turbo码的译码特点主要有外信息体现,因为通常的系统译码只需要输入信息码和校验码,这里的外信息是本征信息以外的附加信息,如何产生这类信息以及如何运用这类信息就构成了不同的算法。
并行译码方案与编码相对应,送入DEC1的是\(x_k\)和\(y_{1k}\)其中\(x_k =m =d_k\).送入DEC2的是\(y_{2k}\)及交织后的\(x_k\)(即\(m'=d_n\)).完成一轮的译码算法后,两个译码器分别输出对\(d_k,y_{1k}\)和\(d_k,y_{2k}\)译码估值以及 估值的可靠程度,分别用似然度\(L_1(d_n)\)和\(L_2(d_n)\)表示。观察Turbo编码器,发现校验码\(y_{1k}\)和\(y_{2k}\)虽然是由两个编码器独立产生并分别传输的,但它们是同源的,都是却决于信息码\(m\)。所以说DEC1的译码器输出必定对DEC2的译码有参考作用;反之DEC2对DEC1的输出也有参考作用。事实上,DEC1提供给DEC2的译码软输出\(L_1(d_k)\)与DEC2的另一支输出\(y_{2k}\)而言是一种附加信息,使输入到DEC2的信息量增加,不确定度(信息熵)减小,从而提高了译码的正确性。一个译码器利用另一个译码器软输出提供的附加信息进行译码,然后将自己的软输出作为附加信息又反馈给另一编译器,整个译码过程可以看作是两个子译码器一次次的信息交换与迭代译码,类似与涡轮机的工作原理,故称这种码位Turbo码
由于与DEC2对应的\(y_{2k}\)是由{\({d_k}\)}的交织序列{\({d_n}\)}产生的,因此DEC1软输出\(L_1(d_k)\)在送入DEC2之前必须经过交织处理,变为\(L_1(d_n)\)以便于\(y_{2k}\)匹配。反之,DEC2软输入\(L_2(d_n)\)在送入DEC1之前必须要经过解交织处理。采用这种循环迭代方式,信息可以得到最充分的利用。可以推断:DEC2译码时利用过的\(y_{2k}\)信息并没有被DEC1利用过,将DEC2的译码信息反馈到DEC1必然有助于提高DEC1的译码性能;另一方面,即使用过了一次的信息也仅是利用了其中的一部分,必然还可以二次,三次的使用。如此,整个译码器的性能可随着迭代而步步提高。但是,随着迭代次数的增加,DEC2与DEC1译码信息中互相独立的成分(附加信息)越来越少,最终降至零。这时的信息量已经被用尽,迭代将无意义,于是终止迭代与DEC2 .最终的软输出经解交织和硬判决得到译码输出\(\hat{d_k}\)

