



java 爬虫:开源java爬虫 swing工具 Imgraber
1实现点:
- 1.返回给定URL网页内,所有图像url list
- 2.返回给定URL网页内,自动生成图像文件路径.txt 文件
- 3.返回给定URL网页内,下载txt文件指定的图片url,并将所有图像保存在 ./img文件夹下
- 4.实现简易swing 界面,有空再改造
2基于开源jsoup实现,鸣谢!
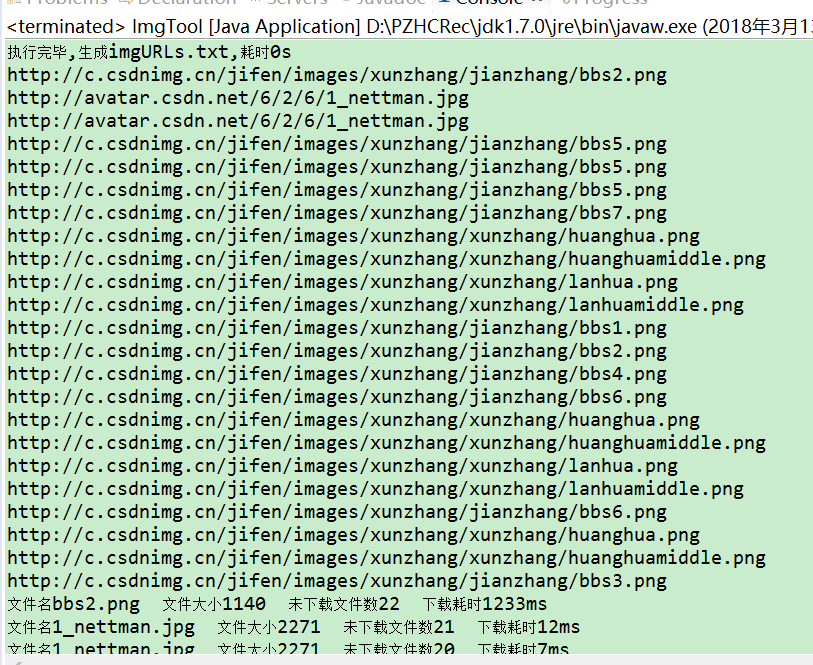
效果



github
package himi.crawler;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.jsoup.Jsoup;
import org.jsoup.helper.StringUtil;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
/**
*
* @ClassName: ImgTool
* @Description:IMG tool ,请先赋值URL 获取指定ULR的某个网页里面
* 1.返回所有图像url list
* 2.图像文件夹路径.txt
* 3.所有图像保存在img文件夹里面
* @author penny
* @date 2018年3月7日 下午10:07:49
*
*/
public class ImgTool {
// 参数域
/** 指定URL */
public static String URL = "https://www.oschina.net";
private int imgNumbs = 0;
public static List<String> downloadMsg=new ArrayList<String>();
public String imgUrlTxt = "imgURLs.txt";
public static String regex= "^((https|http|ftp|rtsp|mms)?://)"
+ "?(([0-9a-z_!~*'().&=+$%-]+: )?[0-9a-z_!~*'().&=+$%-]+@)?" //ftp的user@
+ "(([0-9].)[0-9]" // IP形式的URL- 199.194.52.184
+ "|" // 允许IP和DOMAIN(域名)
+ "([0-9a-z_!~*'()-]+.)*" // 域名-
+ "([0-9a-z][0-9a-z-])?[0-9a-z]." // 二级域名
+ "[a-z])" // first level domain- .com or .museum
+ "(:[0-9])?" // 端口- :80
+ "((/?)|" // a slash isn't required if there is no file name
+ "(/[0-9a-z_!~*'().;?:@&=+$,%#-]+)+/?)$";
private ImgTool() {
};
private static ImgTool instance = new ImgTool();
/** 获取ImgTool 单例 */
public static ImgTool getInstance() {
return instance;
}
public List<String> getURLs() {
return getURLs(null);
}
public boolean isURL(String str) {
if(StringUtil.isBlank(str)){
return false;
}else{
// String regex = "^(?:https?://)?[\\w]{1,}(?:\\.?[\\w]{1,})+[\\w-_/?&=#%:]*$";
// String regex = "^([hH][tT]{2}[pP]:/*|[hH][tT]{2}[pP][sS]:/*|[fF][tT][pP]:/*)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~\\/])+(\\?{0,1}(([A-Za-z0-9-~]+\\={0,1})([A-Za-z0-9-~]*)\\&{0,1})*)$";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(str);
if(matcher.matches()){
return true;
}else{
return false;
}
}};
/***
* @Title: getURLs
* @Description: 给定cssQuery对象
* @param @param cssQuery HTML中的CSS(或者 JQuery)选择器语法,更多详细用法见Jsoup介绍 < a
* href="https://jsoup.org/apidocs/org/jsoup/select/Selector.html"
* ></a>
* @param @return List
* @throws
*
*/
public List<String> getURLs(String cssQuery) {
List<String> urls = null;
Document doc;
Elements imgElements ;
if (!isURL(URL)) {
return null;
}
if(StringUtil.isBlank(cssQuery)){
cssQuery="img";
}
try {
doc = Jsoup.connect(URL).get();
} catch (IOException e) {
e.printStackTrace();
return null;
}
if(doc==null)return null;
imgElements = doc.select(cssQuery);
urls = new ArrayList<String>();
for (Object eleObj : imgElements) {
//"(https?|ftp|http)://[-A-Za-z0-9+&@#/%?=~_|!:,.;]+[-A-Za-z0-9+&@#/%=~_|]"
Pattern pattern = Pattern.compile("(https?|http)://[-A-Za-z0-9+&@#/%?=~_|!:,.;]+[-A-Za-z0-9+&@#/%=~_|]");
Matcher matcher = pattern.matcher(eleObj.toString());
if (matcher.find()) {
String url = matcher.group();
urls.add(url);
}
}
imgNumbs = imgElements.size();
return urls;
}
/**
*
* @Title: createImgURLTxt
* @Description:
* @param @param cssQuery:默认使用img HTML中的CSS(或者 JQuery)选择器语法,更多详细用法见Jsoup介绍 <
* a href="https://jsoup.org/apidocs/org/jsoup/select/Selector.html">
* </a>
* @throws 生成imgURLs.txt
*/
public String createImgURLTxt(String cssQuery) {
long start = System.currentTimeMillis();
List<String> urls;
urls = getURLs(cssQuery);
BufferedWriter os = null;
File urlsFiles = new File("imgURLs.txt");
if(urlsFiles.exists()){
try {
urlsFiles.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}
try {
os = new BufferedWriter(new FileWriter(urlsFiles));
if(urls==null)return null;
for (int i = 0; i < urls.size(); i++) {
os.write(urls.get(i) + "\n");
}
String result = "执行完毕,生成imgURLs.txt,耗时"
+ (System.currentTimeMillis() - start) / 1000 + "s";
System.out.println(result);
return result;
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (os != null)
os.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return null;
}
/**
*
* @Title: createImgs
* @Description:
* @param @param cssQuery
* @param @throws IOException
* @throws
*/
public void createImgs(String cssQuery) throws IOException {
long startTime = System.currentTimeMillis();
downloadMsg.add("Your images is downloading ");
BufferedReader br = null;
OutputStream out = null;
InputStream in = null;
ArrayList<String> imgList = null;
HttpURLConnection con = null;
String url; //待下载文件url
int fileSize = 0; //单个文件大小
int totalFileNum=0; //总文件数
int downLoadFileNum=0; //已下载文件
long totalTime=0; //总耗时/s
long singleTime=0; //单个文件耗时/ms
br = new BufferedReader(new FileReader(imgUrlTxt));
imgList = new ArrayList<String>();
while ((url = br.readLine()) != null) {
imgList.add(url);
}
downLoadFileNum=totalFileNum= imgList.size();
downloadMsg.add("总文件数"+(totalFileNum));
for (String listUrl : imgList) {
startTime = System.currentTimeMillis();
String fileName = listUrl.substring(listUrl.lastIndexOf('/') + 1);// 截取文件名
URL imgUrl = new URL(listUrl.trim());
if (con != null)
con.disconnect();
con = (HttpURLConnection) imgUrl.openConnection();
con.setRequestMethod("GET");
con.setDoInput(true);
con.setConnectTimeout(1000 * 30);
con.setReadTimeout(1000 * 30);
fileSize = con.getContentLength();
con.connect();
try {
in = con.getInputStream();
File file = new File("img" + File.separator, fileName);
if (!file.exists()) {
file.getParentFile().mkdirs();
file.createNewFile();
}
out = new BufferedOutputStream(new FileOutputStream(file));
int len = 0;
byte[] buff = new byte[1024 * 1024];
while ((len = new BufferedInputStream(in).read(buff)) != -1) {
out.write(buff, 0, len);
}
out.flush();
downLoadFileNum--;
} catch (Exception e) {
e.printStackTrace();
} finally {
if (br != null)
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
if (in != null)
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
if (out != null)
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
singleTime=System.currentTimeMillis() - startTime;
totalTime+=singleTime;
downloadMsg.add("文件名" + fileName + " 文件大小" + fileSize
+" 未下载文件数"+(downLoadFileNum)
+" 下载耗时"+ singleTime + "ms" );
System.out.println(downloadMsg.get(downloadMsg.size()-1));
}
}
downloadMsg.add("总耗时"+totalTime/1000+"s");
}
/**
* @throws IOException
*
* @Title: main
* @Description: test
* @param @param args
* @throws
*/
public static void main(String[] args) throws IOException {
ImgTool img = ImgTool.getInstance();
img.createImgURLTxt("img");
List<String> urls = img.getURLs("img");
for (Object str : urls) {
System.out.println(str.toString());
}
img.createImgs(null);
}
}
专注于JavaWeb

 浙公网安备 33010602011771号
浙公网安备 33010602011771号