
爬虫-ajax请求遇到Unicode编码问题
2018-08--4爬取金色财经网页
网址:https://www.jinse.com/search/EOS
第一步:我观察了网页;发现了网页是一个发送ajax请求的网页,发现如下:
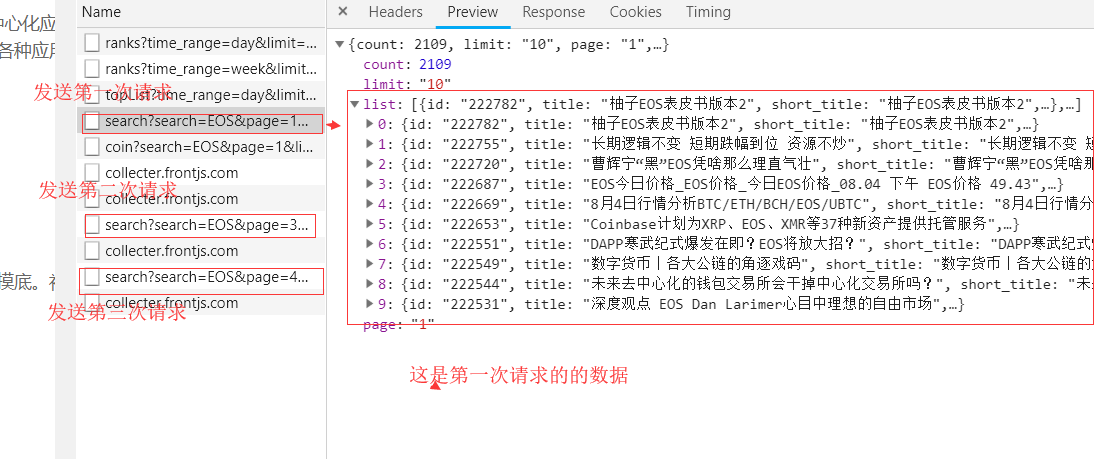
然后 我就先爬取第一次请求出来的信息,剩下的请求可以经过比较每次请求的参数的变化来做比较,从而发现规律。
第二步:我上代码,用requests 请求网页第一次发送ajax请求的网址:地址在上图的header的地方:
获取发送ajax请求的源代码,然后拿到网页源码,因为在上述图片中 我们想要的数据全在源码中-----这是开始的想法,
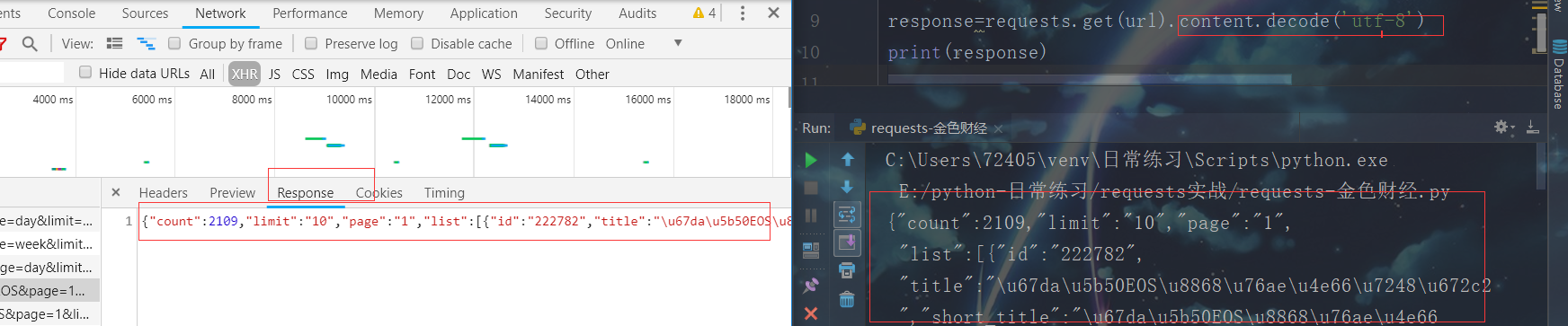
然而拿到源码的时候,返回的是一堆Unciode编码的数据,用。content.decode('utf-8')解析也没用,我有回到网页去观察,发现了如下下图:
发现ajax请求的response字段的内容跟我们获取的源码一模一样。
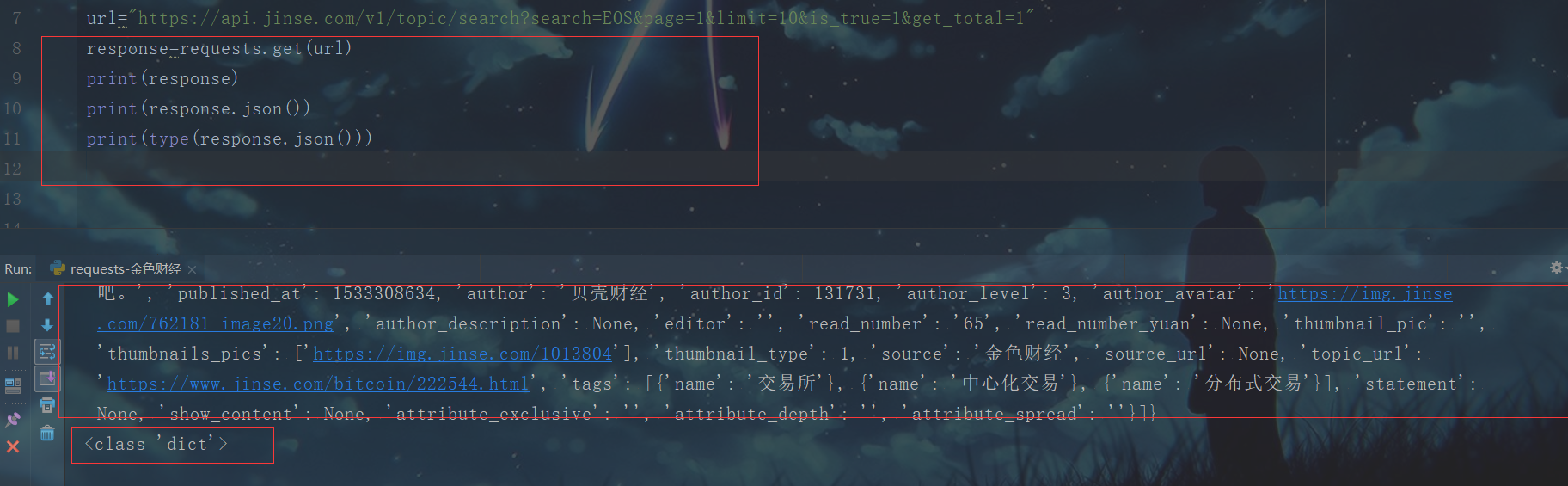
第三步:我我发现获取的内容是字典类型的数据,因此我想到了json ,因为json有两种结构:对象和数组。
1.对象: 对象以“{”开始,“}”结束,“key/value”之间运用 “,”分隔
var packjson={"name":"Liza" , "password":"123"}
2.数组:数组是值的有序集合。一个数组以”{“ 开始 以”}“ 结束。值之间运用逗号“,”隔开
var packjson=[{"name":"liza"},{"name":"asdas"}]
所以,我们获取的就是JSON格式的数据,而我们知道JSON格式的数据 需要用“双引号”括起来 不能用‘单引号’
所以我就试着用两种不同的方式来处理这个json格式显现出来的unciode编码的问题。
1.直接将源代码转化为json对象:
2.利用python内置模块import json 包含两个函数:
a.json.dumps() 将json 对象转化为json字符串
b.json.loads() 将json 字符串转化为json对象 而我们现在就要用到json.loads(str) 所需要讲源代码转化为字符串形式才行
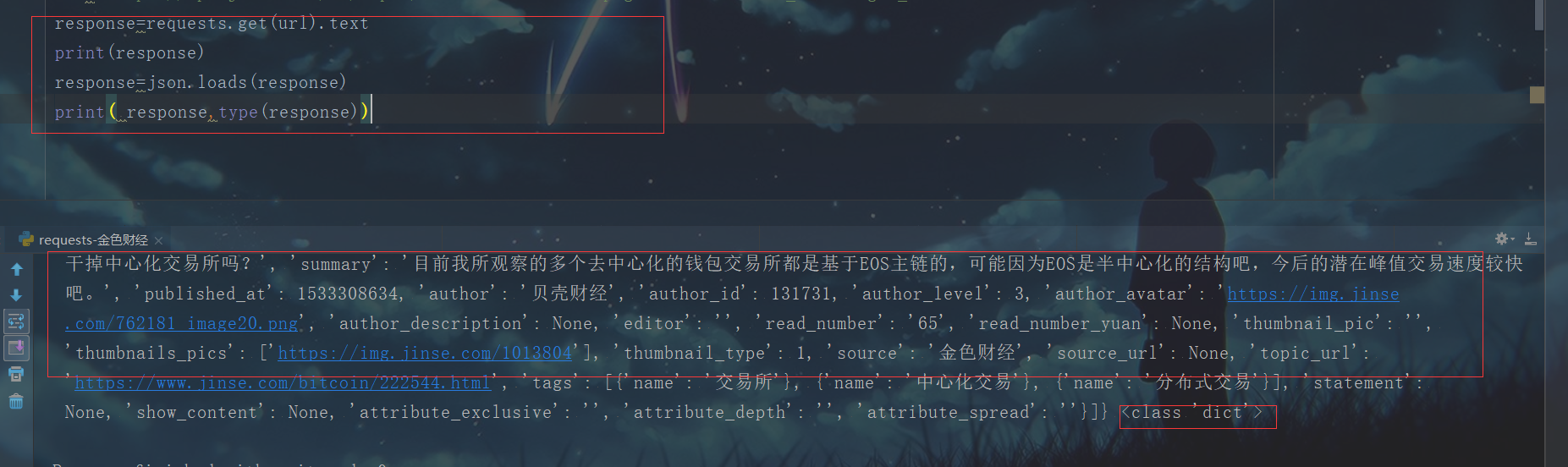
总结: d当我们在ajax请求的时候遇到JSON格式的数据的时候,看见输数据是Unciode编码的数据 ,我们就要把数据变成JSON对象

 浙公网安备 33010602011771号
浙公网安备 33010602011771号