Sql Server 的参数化查询
为什么要使用参数化查询呢?参数化查询写起来看起来都麻烦,还不如用拼接sql语句来的方便快捷。当然,拼接sql语句执行查询虽然看起来方便简洁,其实不然。远没有参数化查询来的安全和快捷。
今天刚好了解了一下关于Sql Server 参数化查询和拼接sql语句来执行查询的一点区别。
参数化查询与拼接sql语句查询相比主要有两点好处:
1、防止sql注入
2、 提高性能(复用查询计划)
首先我们来谈下参数化查询是如何防止sql注入的这个问题吧。
防注入例子:
拼接sql语句:
("select * from user where name={0}",username) 或者 ("select * from user where name="+username)
当 name传进来是一个'aa';Truncate Table user 的时候,这样会导致直接清除整个表数据
"select * from user where name='aa';Truncate Table user
我们使用参数化的时候:
("select * from user where name=@username",new {username=username})
这时候即使我们传进来的是'aa';Truncate Table user ,数据库端也会把这些当做字符串处理,执行的sql语句会变成
select * from user where name=''aa';Truncate Table user '
实际上把'aa';Truncate Table user 这个当做了name的值做查询条件了
以上就是一个简单的例子介绍关于参数化查询如何防止sql注入。
再看到底是如何提高性能的呢?
复用查询计划:
select * from AU_User where Id=1 select * from AU_User where Id=2
Sql Server在执行一条查询语句之前都对对它进行“编译 ”并生成“查询计划”,上面两条查询语句生成的查询计划就是两条不一样的查询计划,在下面这张图片当中我们可以去尝试下执行这两条sql语句
,结果显而易见会生成两条查询计划,Id后面所接的参数不一致。
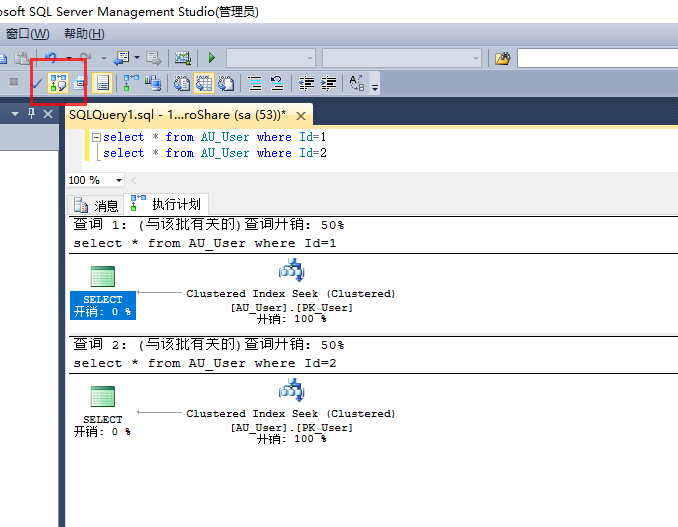
然后我们再来看看使用参数化查询
select * from AU_User where Id=@Id
这样不管你传的参数是多少,执行编译生成的查询计划都是 select * from AU_User where Id=@Id,这样可以实现查询计划的复用,并不需要同一个查询去生成多个查询计划
完全可以节省其中生成查询计划的时间
欢迎大家扫描下方二维码,和我一起学习更多的知识😊



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?