面试-计算机网络-从页面访问浏览器地址会发生什么
1.浏览器输入一个网址回车后会发生什么
参考 What really happens when you navigate to a URL
作为一个软件开发者,你必须知道web app的整体工作流程,其中涉及了一些什么技术:浏览器,HTTP,HTML,web server,request请求等等。
1)首先你从浏览器输入一个地址如下:

2)浏览器查找这个域名对应的ip地址:

设计者为了提高访问解析速度,所以设计了几层缓存,具体包括:
【1】浏览器缓存–浏览器缓存记录了一定时间的DNS记录,这个时间不是操作系统控制的,而是浏览器内置好的,一般在2-30minutes之间。这个缓存就是cookie,域名cookie只能设置当前域名或者顶级域名,其他不会生成。
【2】OS缓存–当浏览器缓存没有找到相应的DNS记录时,浏览器采用系统调用的方式来获取ip,操作系统有它自己的缓存。这个缓存实际上就是hosts文件,在Windows系统上位于c:/windows/system32/drivers/etc/hosts,linux系统上位于/etc/hosts ,如果有对应的下面键值对利用gethostbyname(“www.facebook.com”)即可得到10.110.110.120。
10.110.110.120 www.facebook.com
【3】路由器缓存–局域网内上网,一般都是基于路由器,这个路由器会有域名缓存,至于具体缓存方式,时间等没有具体研究。
【4】ISP(互联网服务提供商)缓存—查找的是其缓存DNS的服务器,相当于二级DNS服务器,这一般都能找得到。
【5】递归搜索—-如果ISP的域名服务器找不到对应记录,则你的ISP从域名服务器递归搜索,搜索方向是先从顶级域名服务器开始到Facebook的域名服务器。(我理解的域名服务器跟ISP域名服务器的关系是父与子的关系,如果子找不到则找父,反之则不成立。而且这个域名服务器往往不止一台,而是集群的形式,所以需要递归查找)
递归查找过程如下图:
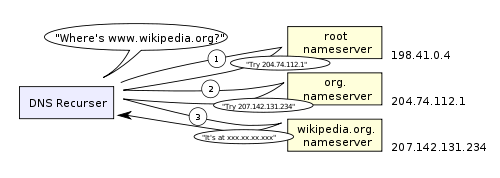
有点需要注意的是,像一些facebook 或者org等看上去只映射了一个ip地址,所以一般用下面的方式来解决瓶颈问题。
Round Robin DNS –轮询调读DNS,怎么理解这个呢,就是假设facebook有五台服务器,上面的资源是相同的,硬件性能也相同,当客服访问facebook的资源时,就可以任意访问某台服务器即可,所以设计了这样一个很简单的方式,每个用户访问将域名轮流解析到不同的ip上,使得各个服务器接受的访问数量达到均衡,当然仅仅是数量,请求的资源多少肯定会有差别。
Load-balancer —负载均衡,在上面方式的基础上加入了权值,使得请求按服务器处理能力,将域名解析到对应的服务器ip上。
Geographic DNS —地理上划分的DNS服务器,将域名按照客户的地理位置解析到就近的或者较优的服务器上,这种方式主要应用的静态内容上,动态内容涉及到同步更新等问题效果不那么明显。
Anycast —很少使用,与TCP协议适应不怎么好,它是将一个ip地址映射到多个主机的路由技术。大多数DNS服务器使用Anycast来获得高效低延迟的DNS查找。
3) 浏览器发送HTTP请求到web server
像facebook主页这样的动态页面,当访问过一次后,在浏览器中的缓存很快就会过期,所以要重新发送请求到facebook服务器上,请求包括三部分:
(1)GET这个请求定义了要读取的URL:“http://facebook.com/”。
(2)浏览器自身定义(User-Agent)
(3)它希望接收什么类型的响应(Accept and Accept-Encoding)。
GET http://facebook.com/ HTTP/1.1
Accept: application/x-ms-application, image/jpeg, application/xaml+xml, [...]
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...]
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Host: facebook.com
Cookie: datr=1265876274-[...]; locale=en_US; lsd=WW[...]; c_user=2101[...]其中Connection头就是tcp三次握手后保持的状态,这个状态保证了暂时不会断开连接。另外包括请求这个域名的cookie,正如大家所知道的,cookie的作用就是为了记录和跟踪不同网站请求的状态,这些状态包括登录名或者密码,某个验证token,一些用户的设置,这些cookie存于客户端,会在每次请求相同域名时被带上。
查看访问请求的工具很多,比如Fiddler,httpwatch, firebug, wireshark等。可以模仿http请求,包括js文件,cookie等任意构建。
当然做软件开发的肯定对post请求也很熟悉,它是用来提交form表单的。
有个小tips。就是结尾斜杠http://facebook.com/ 和http://example.com/folderOrFile,后者会导致多发一次请求,因为没有结尾没有斜杠则不明确是文件还是文件夹,会首先以文件来访问,如果不正确则重定向到文件夹。
4)facebook服务的永久重定向
下面是facebook服务器发送给浏览器的请求:
HTTP/1.1 301 Moved Permanently
Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0,
pre-check=0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
Location: http://www.facebook.com/
P3P: CP="DSP LAW"
Pragma: no-cache
Set-Cookie: made_write_conn=deleted; expires=Thu, 12-Feb-2009 05:09:50 GMT;
path=/; domain=.facebook.com; httponly
Content-Type: text/html; charset=utf-8
X-Cnection: close
Date: Fri, 12 Feb 2010 05:09:51 GMT
Content-Length: 0此请求目的就是让浏览器访问http://www.facebook.com/而不是http://facebook.com/,为什么要这样呢,为什么不直接发送给用户想看的内容呢?解释如下:
【1】浏览器的搜索排名,比如国内百度,会将上面两个域名看为不同的域名,而为了正式化,应用商将前者域名用于排名,试想如果用了两个域名,在相同数量用户请求下,对于应用商来说肯定不如一个域名搜索度更大,比如1000个用户请求如果都访问在一个域名上,则占权值大于500个用户于第一个域名,500个用户于另外一个域名。
【2】如果缓存了两个域名这样其实也不友好,不是一千个哈姆雷特,而是一个诸葛亮。其中的道理仔细想想就懂了。
5)浏览器发送真正的请求到服务器
此时浏览器知道正确的地址是http://www.facebook.com/,所以它发送了下面由服务器导致的重定向请求。
GET http://www.facebook.com/ HTTP/1.1
Accept: application/x-ms-application, image/jpeg, application/xaml+xml, [...]
Accept-Language: en-US
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...]
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Cookie: lsd=XW[...]; c_user=21[...]; x-referer=[...]
Host: www.facebook.com注意到除了请求url外,与第一次请求头是一样的。
6)服务器解析请求
Web server software
服务器接收到请求后,判断并决定用GET请求来处理。处理程序实际上就是生成一个HTML来发送到客户端的程序。如上文访问的是http://www.facebook.com/。具体根据服务器端的配置或者程序,会定位到某个页面,比如http://www.facebook.com/index.html 或者没有后缀形式的http://www.facebook.com/index 当然作为一个uri,最终会被服务端根据自己的后缀匹配规则配对到要访问的具体某个文件。如后一种会加.html。
Request handler
请求处理阅读其参数和cookies,可能会读数据进行操作或者查看,根据具体需求生成一个html响应。对于一个动态网站来说,往往涉及到数据库,数据库也可能分布于不同的地方,可能又会涉及到rpc调用。
7)服务器发回HTML响应
下面是响应:
HTTP/1.1 200 OK
Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0,
pre-check=0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
P3P: CP="DSP LAW"
Pragma: no-cache
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
X-Cnection: close
Transfer-Encoding: chunked
Date: Fri, 12 Feb 2010 09:05:55 GMT
响应的大小为35KB。主要以blob类型来传输,具体根据客户端要求接受的响应体方式—gzip进行压缩,解压后,可以看到下面的html.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en"
lang="en" id="facebook" class=" no_js">
<head>
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta http-equiv="Content-language" content="en" />
...头信息除了提供压缩方式,也说明了缓存Cache-Control ,以及过期时间Expires等等。同时,注意到设置了Content-Type: text/html; charset=utf-8,对应html里面 http-equiv=”Content-type” content=”text/html; charset=utf-8” 这个告诉浏览器是以html来解析而不是文件或者其他形式。
8)浏览器开始显示HTML
浏览器显示html,不必等到全解析完。所以经常会看到只有一半的网页显示出来。
9)浏览器发送请求,解析嵌入在浏览器中的其他内容
比如浏览器中包含了css文件,图片,js代码等等,会请求到对应资源继续解析,如下:
-
Imageshttp://static.ak.fbcdn.net/rsrc.php/z12E0/hash/8q2anwu7.gif
http://static.ak.fbcdn.net/rsrc.php/zBS5C/hash/7hwy7at6.gif
… -
CSS style sheetshttp://static.ak.fbcdn.net/rsrc.php/z448Z/hash/2plh8s4n.css
http://static.ak.fbcdn.net/rsrc.php/zANE1/hash/cvtutcee.css
… -
JavaScript files
http://static.ak.fbcdn.net/rsrc.php/zEMOA/hash/c8yzb6ub.js
http://static.ak.fbcdn.net/rsrc.php/z6R9L/hash/cq2lgbs8.js
…
每个url向前面一样,发送各自的请求,但是注意到这些资源大多是静态的,所以浏览器在第一次访问后会对其进行缓存,除了第一次访问外,其他基本都是从缓存中读取,当然服务器的响应中包含了这些静态文件的保存期限,告诉浏览器对他们的缓存时间。
另外一点,facebook用到了cdn,即内容分发网络,它利用cdn分发这些静态文件,而cdn往往在很多cdn的数据中心会留下备份。这些静态内容,经常用单独的服务器来处理,比如专门的图片处理服务器,比如阿里云,七牛。
10)浏览器发送AJAX请求
在web2.0中,客户端在解析到html后,依然可以通过AJAX来继续保持与服务器通信,采用的就是js代码构造请求,比如可以用来局部刷新,局部返回内容,实时监控等等。
如果你对webserver的工作原理感兴趣,可以来看看我的作品简单地实现了webserver的功能,其原理就是:接受http请求,并在服务端构造响应请求,这个响应请求必须严格遵循http协议,比如头内容等,最后生成html文件发送给客户端,具体代码可见hulichao_framework 下的myWebServer项目。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}
{kind=link}