DRBD 基础及安装
DRBD 简介
DRBD(Distributed ReplicatedBlock Device)是一种基于软件的,无共享,分布式块设备复制的存储解决方案,在服务器之间的对块设备(硬盘,分区,逻辑卷等)进行镜像。也就是说当某一个应用程序完成写操作后,它提交的数据不仅仅会保存在本地块设备上,DRBD也会将这份数据复制一份,通过网络传输到另一个节点的块设备上,这样,两个节点上的块设备上的数据将会保存一致,这就是镜像功能。
DRBD是由内核模块和相关脚本而构成,用以构建高可用性的集群,其实现方式是通过网络来镜像整个设备。它允许用户在远程机器上建立一个本地块设备的实时镜像,与心跳连接结合使用,可以把它看作是一种网络RAID,它允许用户在远程机器上建立一个本地块设备的实时镜像。
DRBD工作在内核当中,类似于一种驱动模块。DRBD工作的位置在文件系统的buffer cache和磁盘调度器之间,通过tcp/ip发给另外一台主机到对方的tcp/ip最终发送给对方的drbd,再由对方的drbd存储在本地对应磁盘 上,类似于一个网络RAID-1功能。在高可用(HA)中使用DRBD功能,可以代替使用一个共享盘阵。本地(主节点)
与远程主机(备节点)的数据可以保 证实时同步。当本地系统出现故障时,远程主机上还会保留有一份相同的数据,可以继续使用。
DRBD工作原理
DRBD是linux的内核的存储层中的一个分布式存储系统,可用使用DRBD在两台Linux服务器之间共享块设备,共享文件系统和数据。类似于一个网络RAID-1的功能,其工作原理的架构图如下:
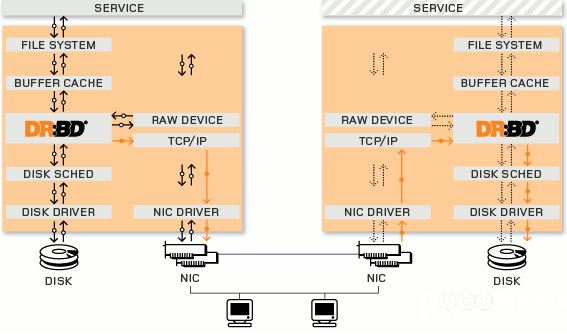
DRBD是如何工作的(工作机制)
(DRBD Primary)负责接收数据,把数据写到本地磁盘并发送给另一台主机(DRBD Secondary),另一个主机再将数据存到自己的磁盘中。目前,DRBD每次只允许对一个节点进行读写访问,但这对于通常的故障切换高可用集群来说已经足够用了。以后的版本(90版本已经支持)将支持两个节点进行读写存取。
DRBD协议说明
- 数据一旦写入磁盘并发送到网络中就认为完成了写入操作。
- 收到接收确认就认为完成了写入操作。
- 收到写入确认就认为完成了写入操作。
DRBD与HA的关系
一个DRBD系统由两个节点构成,与HA集群类似,也有主节点和备用节点之分,在带有主要设备的节点上,应用程序和操作系统可以运行和访问DRBD设备(/dev/drbd*)。
在主节点写入的数据通过DRBD设备存储到主节点的磁盘设备中,同时,这个数据也会自动发送到备用节点对应的DRBD设备,最终写入备用节点的磁盘设备上,在备用节点上,DRBD只是将数据从DRBD设备写入到备用节点的磁盘中。现在大部分的高可用性集群都会使用共享存储,而DRBD也可以作为一个共享存储设备,使用DRBD不需要太多的硬件的投资。因为它在TCP/IP网络中运行,所以,利用DRBD作为共享存储设备,要节约很多成本,因为价格要比专用的存储网络便宜很多;其性能与稳定性方面也不错。
DRBD的特性
分布式复制块设备(DRBD技术)是一种基于软件的,无共享,复制的存储解决方案,在服务器之间的对块设备(硬盘,分区,逻辑卷等)进行镜像。
DRBD镜像数据的特性:
- 实时性,当某个应用程序完成对数据的修改时,复制功能立即发生
- 透明性:应用程序的数据存储在镜像块设备上是独立透明的,他们的数据在两个节点上都保存一份,因此,无论哪一台服务器宕机,都不会影响应用程序读取数据的操作,所以说是透明的。
- 同步镜像和异步镜像:同步镜像表示当应用程序提交本地的写操作后,数据后会同步写到两个节点上去;异步镜像表示当应用程序提交写操作后,只有当本地的节点上完成写操作后,另一个节点才可以完成写操作。
DRBD的同步协议
DRBD的复制功能就是将应用程序提交的数据一份保存在本地节点,一份复制传输保存在另一个节点上。但是DRBD需要对传输的数据进行确认以便保证另一个节点的写操作完成,就需要用到DRBD的同步协议,DRBD同步协议有三种:
协议A:异步复制协议
一旦本地磁盘写入已经完成,数据包已在发送队列中,则写被认为是完成的。在一个节点发生故障时,可能发生数据丢失,因为被写入到远程节点上的数据可能仍在发送队列。尽管,在故障转移节点上的数据是一致的,但没有及时更新。这通常是用于地理上分开的节点。 数据在本地完成写操作且数据已经发送到TCP/IP协议栈的队列中,则认为写操作完成。如果本地节点的写操作完成,此时本地节点发生故障,而数据还处在TCP/IP队列中,则数据不会发送到对端节点上。因此,两个节点的数据将不会保持一致。这种协议虽然高效,但是并不能保证数据的可靠性。
协议B:内存同步(半同步)复制协议
一旦本地磁盘写入已完成且复制数据包达到了对等节点则认为写在主节点上被认为是完成的。数据丢失可能发生在参加的两个节点同时故障的情况下,因为在传输中的数据可能不会被提交到磁盘 数据在本地完成写操作且数据已到达对端节点则认为写操作完成。如果两个节点同时发生故障,即使数据到达对端节点,这种方式同样也会导致在对端节点和本地节点的数据不一致现象,也不具有可靠性。
协议C:同步复制协议
只有在本地和远程节点的磁盘已经确认了写操作完成,写才被认为完成。没有任何数据丢失,所以这是一个群集节点的流行模式,但I / O吞吐量依赖于网络带宽。只有当本地节点的磁盘和对端节点的磁盘都完成了写操作,才认为写操作完成。这是集群流行的一种方式,应用也是最多的,这种方式虽然不高效,但是最可靠。
以上三种协议中,一般使用协议C,但选择C协议将影响流量,从而影响网络时延。为了数据可靠性,在生产环境使用时须慎重选项使用哪一种协议。
DRBD的配置说明
DRBD的主配置文件为/etc/drbd.conf;为了管理的便捷性,目前通常会将配置文件分成多个部分,且都保存至/etc/drbd.d目录中,主配置文件中仅使用"include"指令将这些配置文件片断整合起来。通常,/etc/drbd.d目录中的配置文件为global_common.conf和所有以.res结尾的文件。其中global_common.conf中主要定义global段和common段,而每一个.res的文件用于定义一个资源。
global_common.conf
global {
usage-count no; //是否参加DRBD使用者统计,默认是参加(yes)
}
//定义出现以下问题(如splitbrain或out-of-sync错误)时处理策略
common {
handlers {
pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f";
}
//DRBD同步时使用的验证方式和密码。该配置段用来更加精细地调节DRBD属性,它作用于配置节点在启动或重启时。
startup {
}
options {
}
disk {
on-io-error detach; //默认策略,发生I/O错误的节点将放弃底层设备,以diskless mode继续工作。在diskless mode下,只要还有网络连接,DRBD将从secondary node读写数据,而不需要failover(故障转移)。该策略会导致一定的损失,但好处也很明显,DRBD服务不会中断。官方推荐和默认策略。
}
net {
protocol C; //指定复制协议,复制协议共有三种,为协议A,B,C,默认协议为协议C
cram-hmac-alg "sha1"; //该选项可以用来指定HMAC算法来启用对端节点授权。
shared-secret "mydrbd"; //该选项用来设定在对端节点授权中使用的密码,最长64个字符。
}
}
drbd0.res
resource drbd0 { //drbd0 为资源名称
on node01 { //on后面为节点的名称,有几个节点就有几个on段,这里是定义节点node01上的资源
device /dev/drbd0; //定义DRBD虚拟块设备,这个设备事先不要格式化。
disk /dev/vg_drbd/lv_drbd; //定义存储磁盘为逻辑卷,该卷创建完成之后就行了,不要进行格式化操作
address 192.168.199.101:7789; //定义DRBD监听的地址和端口,以便和对端进行通信
meta-disk internal; //该参数有2个选项:internal和externally,其中internal表示将元数据和数据存储在同一个磁盘上;而externally表示将元数据和数据分开存储,元数据被放在另一个磁盘上。
}
on node02 { //这里是定义节点node02上的资源
device /dev/drbd0;
disk /dev/vg_drbd/lv_drbd;
address 192.168.199.102:7789;
meta-disk internal;
}
}
DRDB主从安装记录
DRBD(Distributed Replicated Block Device) 可以理解为它其实就是个网络RAID-1,两台服务器间就算某台因断电或者宕机也不会对数据有任何影响,而真正的热切换可以通过Keepalived或Heartbeat方案解决,不需要人工干预。
DRBD安装
服务器信息
【两节点操作】
//IP及主机名
cat /etc/hosts
192.168.199.101 node01
192.168.199.102 node02
//系统版本
cat /etc/redhat-release
CentOS Linux release 7.8.2003 (Core)
//内核版本
uname -r
3.10.0-1127.el7.x86_64
初始化工作
【两节点操作】
1. 关闭selinux、firewalld
2. ntp时间校对
3. 修改主机名及/etc/hosts 申明
创建逻辑卷
【两节点操作】
vgcreate vg_drbd /dev/vdb1
lvcreate -L 5G -n lv_drbd vg_drbd
安装DRBD
【两节点操作】
yum install kmod-drbd90 drbd90-utils -y
这里安装 drbd90 会升级内核一个小版本,因此建立安装完成后重启
安装前,内核版本:
3.10.0-1127.el7.x86_64
reboot
安装后,内核版本:
3.10.0-1160.31.1.el7.x86_64
编辑配置文件
【node01 操作】
global_common.conf
global {
usage-count no;
}
common {
handlers {
pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f";
}
startup {
}
options {
}
disk {
on-io-error detach;
}
net {
protocol C;
cram-hmac-alg "sha1";
shared-secret "mydrbd";
}
}
drbd0.res
cat << EOF > /etc/drbd.d/drbd0.res
resource drbd0 {
on node01 {
device /dev/drbd0;
disk /dev/vg_drbd/lv_drbd;
address 192.168.199.101:7789;
meta-disk internal;
}
on node02 {
device /dev/drbd0;
disk /dev/vg_drbd/lv_drbd;
address 192.168.199.102:7789;
meta-disk internal;
}
}
EOF
将配置文件拷贝到 node02
scp /etc/drbd.d/* node02:/etc/drbd.d/
创建DRBD设备
【两节点操作】
drbdadm create-md drbd0
启动服务
【两节点操作】
systemctl enable drbd; systemctl start drbd
设置 primary节点
【node01 操作】
[root@node01(192.168.199.101) ~]#drbdadm status
drbd0 role:Secondary
disk:Inconsistent
node02 role:Secondary
peer-disk:Inconsistent
[root@node01(192.168.199.101) ~]#drbdadm primary drbd0 --force
[root@node01(192.168.199.101) ~]#drbdadm status
drbd0 role:Primary
disk:UpToDate
node02 role:Secondary
replication:SyncSource peer-disk:Inconsistent done:2.81
格式化DRBD设备并挂载
【node01 操作】
mkfs.xfs /dev/drbd0
mkdir -pv /mnt/test
mount /dev/drbd0 /mnt/test/
touch /mnt/test/file{1..10}
测试
//将 node01 切换为 Secondary
#umount /mnt/test
#drbdadm secondary drbd0
#drbdadm status
drbd0 role:Secondary
disk:UpToDate
node02 role:Secondary
peer-disk:UpToDate
//将 node02 切换为 primary
#drbdadm primary drbd0
#drbdadm status
drbd0 role:Primary
disk:UpToDate
node01 role:Secondary
peer-disk:UpToDate
#mkdir -pv /mnt/test
#ls /mnt/test/
file1 file10 file2 file3 file4 file5 file6 file7 file8 file9
通过测试发现,文件已经实时同步,drbd功能测试成功。
DRBD扩容
上面的安装过程中,采用了LVM逻辑卷的方式,这样的好处如下:
- 考虑到后期的扩容
- 在DRBD同步时,在同步完成之前SyncTarget的状态为 Inconsistent。如果在这种情况下SyncSource发生故障(无法修复),这将使您处于不幸的境地:具有良好数据的节点已死,并且尚存的节点具有不良(不一致)的数据。从LVM逻辑卷提供DRBD时,可以通过在同步开始时创建一个自动快照并在同步成功完成后自动删除该快照来减轻此问题。
接下来演示 扩容:
扩容逻辑卷
【两节点操作】
lvresize -L +5G /dev/vg_drbd/lv_drbd
重读drbd size大小
【Primary 节点操作】
drbdadm resize drbd0
xfs_growfs /dev/drbd0
DRBD 脑裂问题
当两个节点都处于 StandAlone 状态,则处于脑裂状态。
//node01 节点
[root@node01(192.168.199.101) ~]#drbdadm status
drbd0 role:Secondary
disk:UpToDate
node02 connection:StandAlone
// node02 节点
[root@node02(192.168.199.102) ~]#drbdadm status
drbd0 role:Secondary
disk:UpToDate
node01 connection:StandAlone
脑裂处理方式
//node01节点操作
[root@node01(192.168.199.101) ~]#drbdadm disconnect drbd0
[root@node01(192.168.199.101) ~]#drbdadm secondary drbd0
[root@node01(192.168.199.101) ~]#drbdadm -- --discard-my-data connect drbd0
[root@node01(192.168.199.101) ~]#drbdadm status
drbd0 role:Secondary
disk:UpToDate
node02 connection:Connecting
//node02节点操作
[root@node02(192.168.199.102) /etc/keepalived]#drbdadm disconnect drbd0
[root@node02(192.168.199.102) /etc/keepalived]#drbdadm connect drbd0
查看是否恢复正常
//node01 节点
[root@node01(192.168.199.101) ~]#drbdadm status
drbd0 role:Secondary
disk:Inconsistent
node02 role:Secondary
replication:SyncTarget peer-disk:UpToDate done:14.51
//node02 节点
[root@node02(192.168.199.102) ~]#drbdadm status
drbd0 role:Secondary
disk:UpToDate
node01 role:Secondary
replication:SyncSource peer-disk:Inconsistent done:7.22

 浙公网安备 33010602011771号
浙公网安备 33010602011771号