[ ceph ] 基本概念、原理、架构介绍
1. Ceph 架构
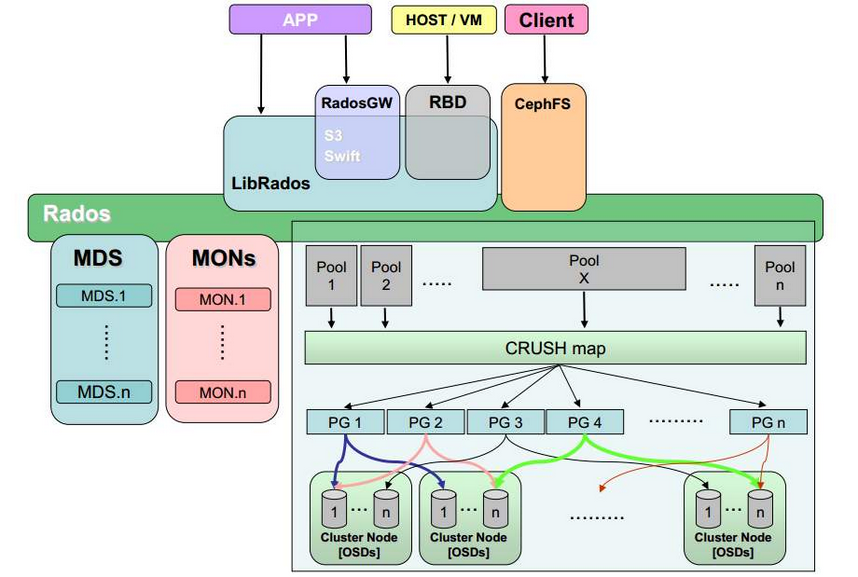
1.1 Ceph 接口
Ceph 支持三种接口:
- Object:有原生的API,而且也兼容 Swift 和 S3 的 API
- Block:支持精简配置、快照、克隆
- File:Posix 接口,支持快照
1.2 Ceph 核心组件及概念介绍
- Monitor:一个 Ceph 集群需要多个 Monitor 组成的小集群,它们通过 Paxos 同步数据,用来保存 OSD 的元数据。
- OSD:OSD 全称 Object Storage Device,也就是负责响应客户端请求返回具体数据的进程,一个Ceph集群一般有很多个OSD。
- CRUSH:CRUSH 是 Ceph 使用的数据分布算法,类似一致性哈希,让数据分配到预期的位置。
- PG:PG全称 Placement Groups,是一个逻辑的概念,一个PG 包含多个 OSD 。引入 PG 这一层其实是为了更好的分配数据和定位数据。
- Object:Ceph 最底层的存储单元是 Object对象,每个 Object 包含元数据和原始数据。
- RADOS:实现数据分配、Failover 等集群操作。
- Libradio:Libradio 是RADOS提供库,因为 RADOS 是协议,很难直接访问,因此上层的 RBD、RGW和CephFS都是通过libradios访问的,目前提供 PHP、Ruby、Java、Python、C 和 C++的支持。
- MDS:MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。
- RBD:RBD全称 RADOS Block Device,是 Ceph 对外提供的块设备服务。
- RGW:RGW全称RADOS gateway,是Ceph对外提供的对象存储服务,接口与S3和Swift兼容。
- CephFS:CephFS全称Ceph File System,是Ceph对外提供的文件系统服务。
2. 三种存储类型
块设备:主要是将裸磁盘空间映射给主机使用,类似于SAN存储,使用场景主要是文件存储,日志存储,虚拟化镜像文件等。
文件存储:典型代表:FTP 、NFS 为了克服块存储无法共享的问题,所以有了文件存储。
对象存储:具备块存储的读写高速和文件存储的共享等特性并且通过 Restful API 访问,通常适合图片、流媒体存储。
2.1 Ceph IO流程及数据分布
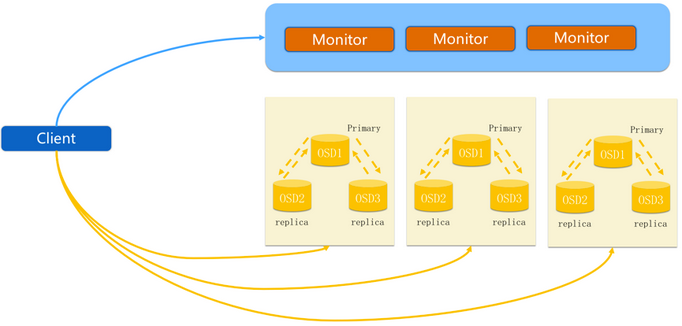
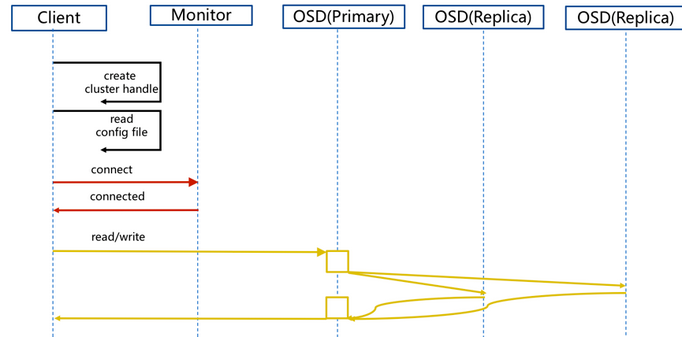
步骤:
- client 创建cluster handler。
- client 读取配置文件。
- client 连接上monitor,获取集群map信息。
- client 读写io 根据crushmap 算法请求对应的主osd数据节点。
- 主osd数据节点同时写入另外两个副本节点数据。
- 等待主节点以及另外两个副本节点写完数据状态。
- 主节点及副本节点写入状态都成功后,返回给client,io写入完成。
新主IO流程图
说明:
如果新加入的OSD1取代了原有的 OSD4成为 Primary OSD, 由于 OSD1 上未创建 PG , 不存在数据,那么 PG 上的 I/O 无法进行,怎样工作的呢?

步骤:
(1)client连接monitor获取集群map信息。
(2)同时新主osd1由于没有pg数据会主动上报monitor告知让osd2临时接替为主。
(3)临时主osd2会把数据全量同步给新主osd1。
(4)client IO读写直接连接临时主osd2进行读写。
(5)osd2收到读写io,同时写入另外两副本节点。
(6)等待osd2以及另外两副本写入成功。
(7)osd2三份数据都写入成功返回给client, 此时client io读写完毕。
(8)如果osd1数据同步完毕,临时主osd2会交出主角色。
(9)osd1成为主节点,osd2变成副本。
3. Ceph 如何存取数据
这里有一篇文章写的通俗易懂:http://www.xuxiaopang.com/2016/11/08/easy-ceph-CRUSH/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号