

畅谈一下告警
为什么要告警
一个业务系统维护了很长时间了,指不定什么时候会出现问题。不过有些系统也是依赖微信、支付宝平台的,大平台都有自身的监控和告警能力帮忙分析和定位商户系统问题,但并不是所有场景都能涵盖到。所以个人负责的业务模块需要制定合理的告警机制,系统发生故障要第一时间知道,而不是被通知。
告警指标
常见的指标有请求量、失败量、平均耗时等,其他指标可以根据业务自身的特点来提取上报。
告警阈值
告警的目的是出问题了,能够马上主动发现问题,简单的问题甚至可以在被投诉和其他人发现前就能修复了。
如果一个系统上报的指标多了,经常会发生没有设置告警阈值的情况。
尤其是对于后来新增的监控指标,尤其要注意是否设置监控阈值。
可以针对请求量、失败量,失败率,平均耗时,耗时中位数设置合理的阈值,触发阈值后发送告警通知。
告警处理
我们要明确告警的目的,告警是为了及时发现问题,然后快速处理并恢复业务系统。告警信息要明确,不要误告警。对于简单且能快速处理的问题,可以允许间断的发送告警;而对于相对复杂并且很长时间才能解决的问题,持续的告警就没有意义,这时需要屏蔽告警,问题修复之后再重新恢复告警机制。因此告警模块的灵活性配置是很重要的,根据业务场景可以配置不同的策略,另外也要支持屏蔽和恢复能力。
告警收敛
复杂的业务系统往往都是多实例部署的,如果每个实例都发生问题然后开始发送告警信息,那么技术人员会收到很多条无意义的信息,不利于告警信息分析。这时就要考虑对告警信息进行收集分析了,保证每个业务场景的告警信息同一时间内只是发送一次。及时多实例告警信息做了收集分析,故障没有及时处理,告警信息会持续发送,这是就要固定周期内发送告警信息,甚至可以通过配置进行屏蔽掉。告警一定要在系统故障的时候及时发出来,避免无意义的发送,否则技术人员会产生抵触心里,甚至手机端直接屏蔽。
合理阈值
告警模块要支持不同的业务场景设置不同的告警阈值,如果是一个固定的阈值可能会引入一系列的误告警。灵活的配置,配置中心的引入是少不了了。设置阈值时,要考虑同一个业务场景不同的时间段是不是需要设置不同的阈值,不同的业务场景需要设置不同的阈值。比如某个特殊业务场景,晚上的请求量比白天的请求量多;比如有的业务场景接口平均响应时间比其他的都长;比如某些业务场景在某个时间段不进行告警分析。
告警设计
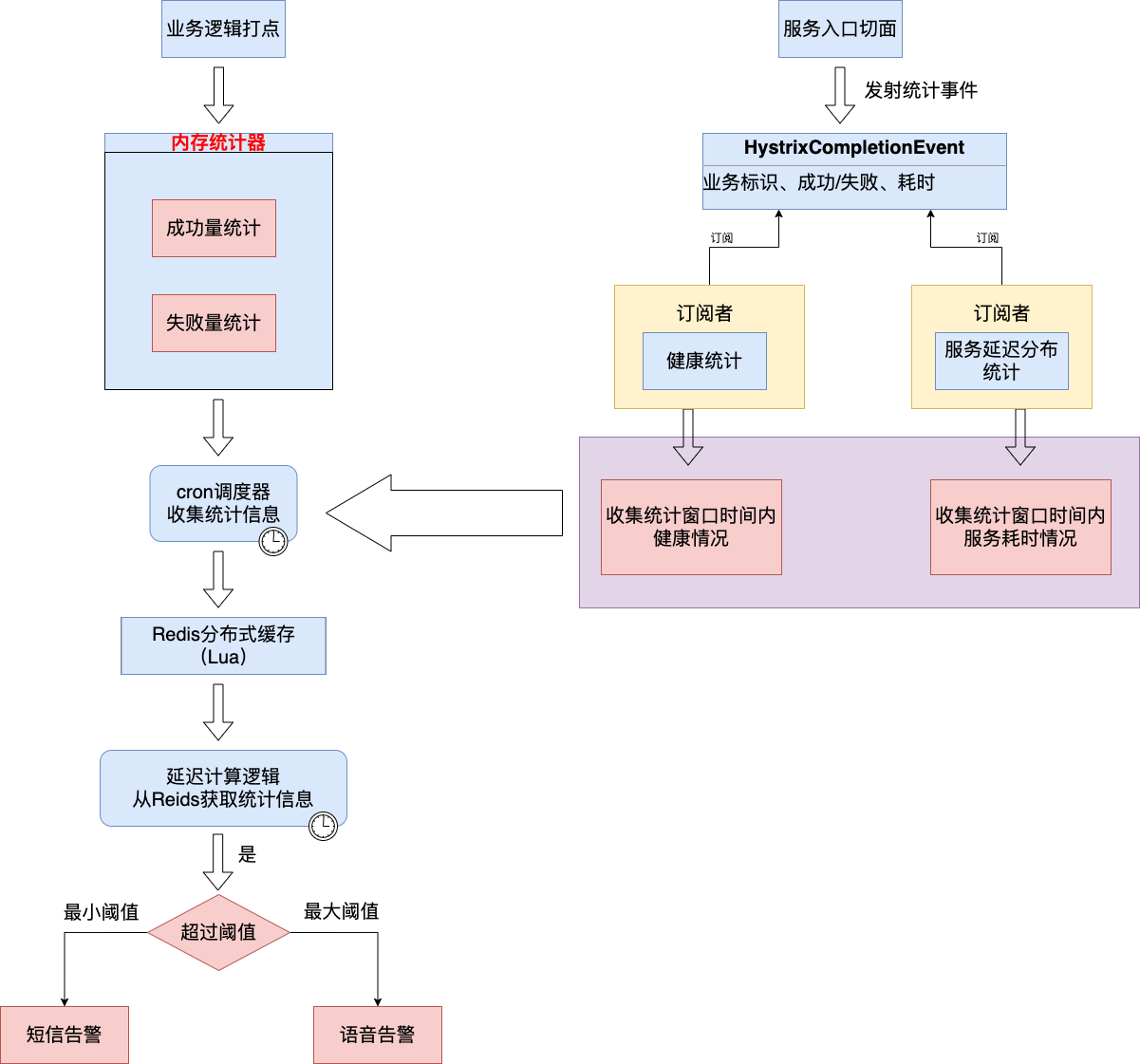
成功量和失败量的统计可以通过内存变量(AtomicLong)进行统计,或者使用RxJava提供的window操作符会在时间间隔内缓存统计结果,类似于buffer缓存一个list集合,区别在于window将这个结果集合封装成了observable。
使用RxJava可以很方便统计一个窗口内服务的成功量、失败量、延迟分布情况。
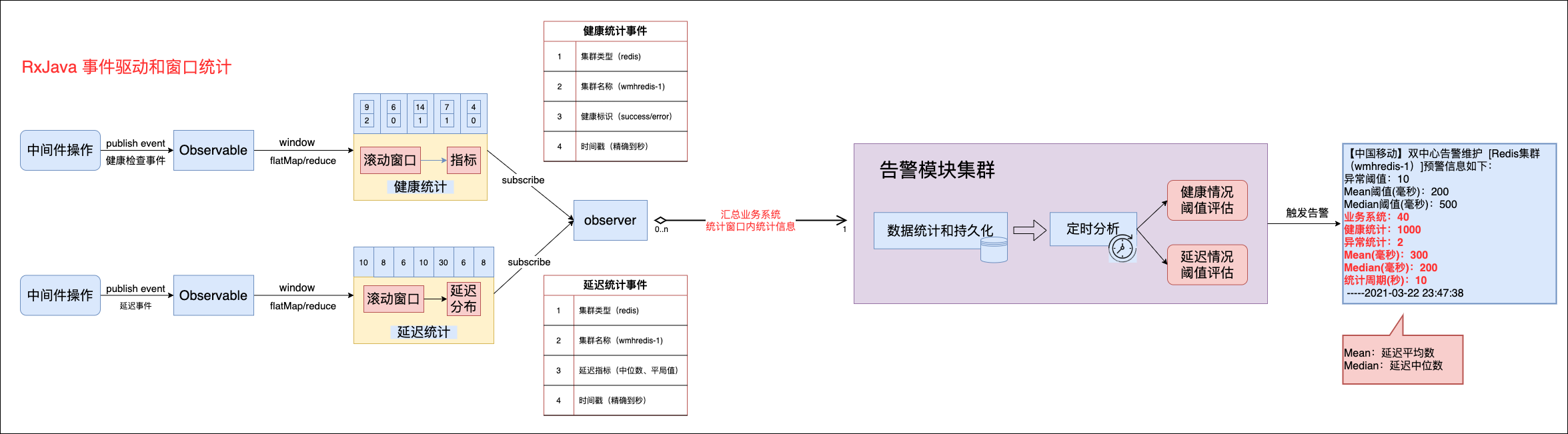
像常用的中间件(redis、kafka、rocketmq、es)相关操作都可以通过切面利用RxJava统计健康和延迟情况,然后汇总到告警模块进行分析并触发预警。
总结
希望本文章的告警设计思路可以给读者带来启发。一个优秀的告警系统,可以减少人力监控,也是自动化运维的一种手段。对于技术人员来说,自己写的业务代码出现问题一定要自己第一时间知道,而不是被人通知。如果现有的告警能力不能满足你的要求,一定要从长远的角度出发,制定告警方案,而不是把大部分精力都放在日志查询上。
本文来自博客园,作者:hjzqyx,转载请注明原文链接:https://www.cnblogs.com/hujunzheng/p/14616775.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!
2016-04-05 java自定义类加载器