ElasticSearch系列---【ElasticSearch使用教程】
ElasticSearch实战教程
一、背景介绍
2004 年,有一个以色列小伙子,名字叫谢伊·班 农( Shay Banon),他成亲不久来到伦敦,因为当时他的夫人正好在伦敦学厨师。初 来乍到,也没有找到工作,于是班农就打算写一个叫作 iCook 的小程序来管理和搜索菜 谱,一来练练手,方便找工作;二来这个小工具还可以给其夫人用。
班农在编写 iCook 的过程中,使用了 Lucene,感受到了直接使用 Lucene 开发 程序的各种暴击和痛苦,于是他在 Lucene 之上,封装了一个叫作 Compass 的程序框 架,与 Hibernate 和 JPA 等 ORM 框架进行集成,通过操作对象的方式来自动地调用 Lucene 以构建索引。方便地实现对‘领域对象’进行索引的创建,并实现‘字 段级别’的检索,以及实现‘全文搜索’功能。可以说,Compass 大大简化了给 Java 程序添加搜索功能的开发。Compass 开源出来,变得很流行。
Compass 编写到 2.x 版本的时候,社区里面出现了更多需求,比如需要有处理 更多数据的能力以及分布式的设计。班农发现只有重写 Compass ,才能更好地实现这 些分布式搜索的需求,于是 Compass 3.0 就没有了,取而代之的是一个全新的项目, 也就是 Elasticsearch。”
二、适用场景
1. 检索类服务
- 搜索文库
- 电商商品检索
- 海量系统日志检索

2. 问答类服务(本质上也是检索类)
- 在线智能客服
- 机器人
3. 地图类服务
- 打车app
- 外卖app
- 社区团购配送
- 陌生人社交
三、Es的安装
为了方便演示,这里以docker安装:
docker run -di --name es01-test -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.17.28
docker run -di --name kib01-test -p 5601:5601 -e "ELASTICSEARCH_HOSTS=http://192.168.137.15:9200" docker.elastic.co/kibana/kibana:7.17.28
四、Es的基本概念
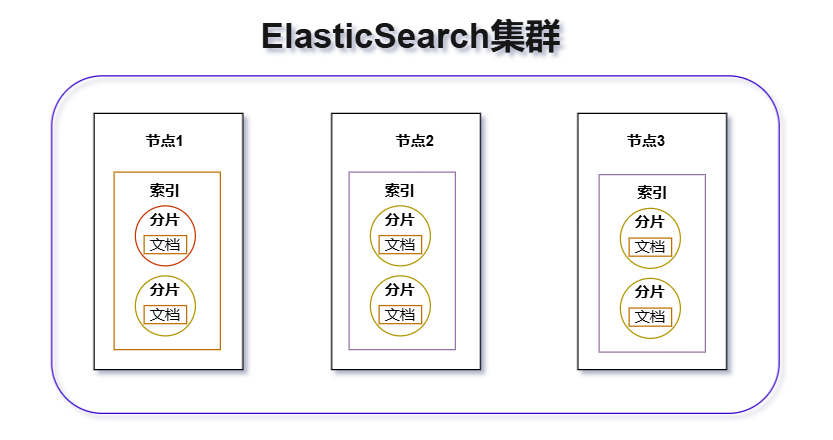
ES 的基本概念除了集群、节点之外,还有: 索引 、 Mapping 、 文档 、 字段 、 分词 、 分词器 、 分片 、 副本 、 倒排索引 。
- 索引 :索引是某一类文档的集合,类似 Mysql 的数据库。
- Mapping :Mapping 是定义索引中有哪些字段,以及字段类型,以及字段是否会分词等,类似数据库中定义的表结构。
- 文档 :文档就是索引里的一条记录,类似数据库表中的一行记录。
- 字段 :文档有一个或多个字段,每个字段有指定的类型,常用的类型有:keyword、text、数字类型(integer、long、float、double 等)、日期类型、对象类型等。类型是text类型时,创建文档时 ES 会对该字段进行分词操作,其余类型则不会做分词。
- 分词 :ES 里最核心的概念就是分词了,ES 会对text类型的字段进行分词,分词后就会得到一个个的词项,常用Term表述。
- 分词器 :ES 里有各种各样的分词器,用于不用场景下对text类型的字段进行分词。
- 分片 :分片实际上是将某个索引的数据切分成多个块,然后均匀地将各个块分配到集群里的各个 Node 节点上。可以通过 ES 的策略查找数据块所在的 Node。这种方案是面向海量数据而设计的,这样数据可以分布在各个节点上,数据量扩张时通过扩充 Node 数量来快速解决。
- 副本 :只要涉及到分布式的场景,几乎都有副本的概念。副本主要是为了备份数据,保障数据的安全性。同时也可以将查询请求分摊到各个副本里,缓解系统压力,提高吞吐量。ES 里的数据分为主分片和副本分片,写数据时先写入主分片,然后在异步写入副本分片。
- 倒排索引 :比如我们常用的数据库索引,是把索引字段建立目录,保存目录和数据的关系,然后根据目录去查找文档,使用 B+ 树来实现。但是倒排索引(又称反向索引),是根据分词后的 Term 与文档建立关系,每个 Term 都对应着一堆文档,然后搜索文本时先将文本分词,然后去匹配 Term,然后再去根据匹配的得分找出相关文档。
1.Elasticsearch 和Mysql概念对比
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是Elasticsearch提供的JSON风格的请求语句,用来操作Elasticsearch,实现CRUD |
2.Elasticsearch 数据类型
| 类型类别 | 数据类型 |
|---|---|
| 字符串类型 | keyword,text |
| 数值类型 | long, integer, short, byte, double, float, half float, scaled float |
| 日期类型 | date |
| 布尔值类型 | boolean |
| 二进制类型 | binary |
| 其他类型 | 等等... |
3.正向索引
mysql正常存储数据
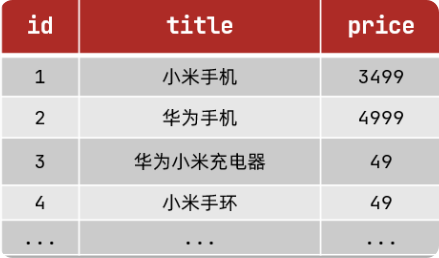
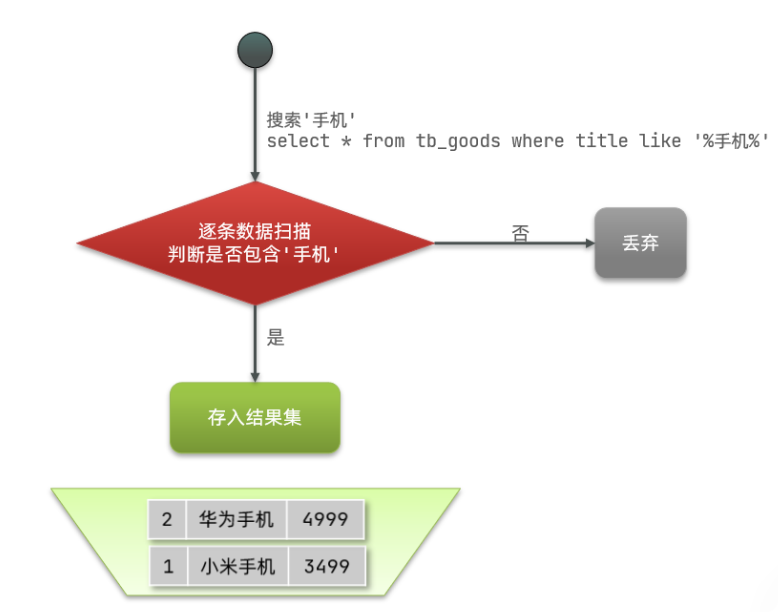
如果是根据id查询,那么直接走索引,查询速度非常快。
但如果是基于title做模糊查询,只能是逐行扫描数据,流程如下:
1)用户搜索数据,条件是title符合"%手机%"
2)逐行获取数据,比如id为1的数据
3)判断数据中的title是否符合用户搜索条件
4)如果符合则放入结果集,不符合则丢弃。回到步骤1
逐行扫描,也就是全表扫描,随着数据量增加,其查询效率也会越来越低。当数据量达到数百万时,就是一场灾难。
4.倒排索引

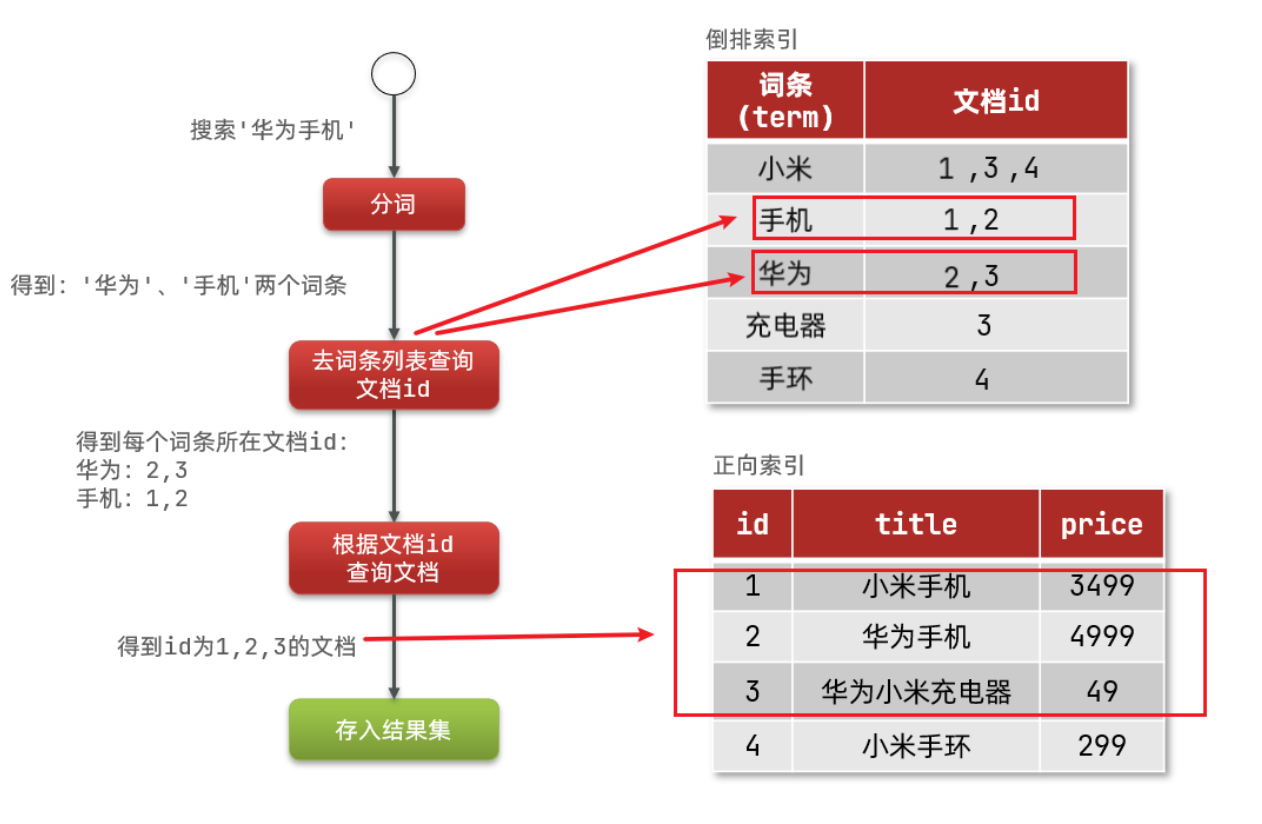
虽然要先查询倒排索引,再查询倒排索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快!无需全表扫描。
5.分词器
IK分词器有几种模式?
ik_smart:智能切分,粗粒度
ik_max_word:最细切分,细粒度
IK分词器如何拓展词条?如何停用词条?
利用config目录的IkAnalyzer.cfg.xml文件添加拓展词典和停用词典。
在词典中添加拓展词条或者停用词条。
五、DSL语法
# 1.新增索引test2
PUT /test2
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"name": {
"type": "text",
#fielddata:默认为false,启用 fielddata,即为true时,这样会消耗大量内存,因为Es需要在内存中加载字段的所有值。只有在非常必要的情况下才应使用此选项。为false时,该字段不可用于聚合、排序和脚本操作的。text类型主要是用来做全文检索的。
"fielddata": false
},
"age": {
"type": "long"
},
"birthday": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis",
#当值为false时,当传入的值的日期格式和上面指定的不一致时,不能存入es索引,直接报错。
"ignore_malformed": false
}
}
}
}
# 2.新增索引test2的一条数据
POST /test2/_doc
{
"name": "里斯",
"age": 17,
"desc": "一顿操作猛如虎",
"tags": ["抽烟","喝酒"]
}
# 3.新增或修改索引test2的一条数据(存在就修改,不存在就新增,注意:不传的字段会覆盖成null,因此不建议用这个)
PUT /test2/_doc/3
{
"_name": "里斯4",
"age": 17,
"desc": "一顿操作猛如虎",
"tags": ["抽烟","喝酒"]
}
# 推荐的修改方法,这种不会覆盖没有传的字段的值为null
POST /test/_update/4
{
"doc": {
"desc": "修改后"
}
}
# 这个是上面推荐的修改方法的过时的写法,不推荐使用,放这里,方便后续看到了认识这种写法也是对的。
POST /test/_doc/2/_update
{
"doc": {
"desc": "修改后"
}
}
# 4.删除索引test2里_id为3的数据
DELETE /test2/_doc/3
# 5.查看test2索引映射
GET test2/_mapping
# 6.查询所有数据
GET test2/_search?pretty
{
"query": {
"match_all": {}
},
"_source": ["field1", "field2"]
}
# 7.单字段模糊查询
GET test2/_search
{
"query": {
"match": { "name": "里斯"}
},
"_source": ["field1", "field2"]
}
# 8.bool的复合查询
#match:会自动分词,适用于text类型的字段,由于需要进行分词和文本处理,可能会比 term 查询慢一些。
#在 Elasticsearch 中,must、must_not 和 should 语句是 bool 查询的一部分,用于构建复杂的、逻辑组合的查询。它们的意义与我们在编程或者逻辑中常用的 and、not 和 or 相似。以下是每个语句的详细解释:
#must:所有 must 中的查询都必须匹配,以便该文档被包含在结果中。这类似于逻辑 and 操作。
#must_not:所有 must_not 中的查询都不能匹配,以便该文档被包含在结果中。这类似于逻辑 not 操作。
#should:至少有一个 should 查询必须匹配,以便该文档被包含在结果中。但是,如果 must 或 filter 查询也存在的话,那么 should 查询就不是必须的。这类似于逻辑 or 操作。
#和 SQL 中的逻辑操作符相比,这些语句有一些不同之处。例如,SQL 中的 AND、OR 和 NOT 操作符通常在同一个条件语句中一起使用,而在 Elasticsearch 的 bool 查询中,must、must_not 和 should是作为不同查询的数组来使用的,每个数组中可以包含多个查询。
#以下是一个使用 must、must_not 和 should 的 bool 查询示例:
GET test2/_search
{
"query": {
"bool": {
"must": [
{ "match": { "field1": "value1" } },
{ "match": { "field2": "value2" } }
],
"must_not": [
{ "match": { "field3": "value3" } }
],
"should": [
{ "match": { "field4": "value4" } },
{ "match": { "field5": "value5" } }
]
}
}
}
# 9.term精确查询(适用于数字、日期、关键字类型的字段)
#性能快
#在Elasticsearch中,term查询用于执行精确匹配搜索。它用于查找那些具有确切值的字段,不会对搜索的词条进行分词(tokenizing),也不会进行任何文本处理(例如,小写化)。
#term查询通常用于数字、日期或者不分词的精确值字段(例如,关键字字段类型,即keyword类型)上。当你想精确匹配一个字段的完整未分词的值时,你会使用term查询。
#这里有一个使用term查询的例子:
GET test2/_search
{
"query": {
"term": {
"status": {
"value": "active"
}
}
}
}
#在上述查询中,Elasticsearch查找status字段精确是active的所有文档。如果有文档的status字段值为Active或ACTIVE,默认情况下,这些文档将不会被匹配,因为term查询区分大小写并且不会进行任何文本处理。
#与之相对的是match查询,match查询会分析查询字符串,根据字段的分析器(analyzer)处理,例如,通常会自动小写化,并根据分词器的设置将字符串拆分成一个或多个词条。match查询更适合于全文本字段的搜索,如使用text字段类型的情况。
#因此,选择term还是match查询取决于你的具体需求:是否需要进行精确匹配以及字段是否被分析。对于那些需要根据确切值过滤的情况,term查询是更好的选择。
# 10.filter
#当然,让我们通过一个更具体的例子来理解 Elasticsearch 中的 filter 使用。假设我们有一个电子商务网站,我们想要找到所有价格在 10 到 100 美元之间,并且品牌为 "Nike" 或 "Adidas" 的产品。我们可以使用 bool 查询结合 filter 来实现这个需求。
#以下是一个使用 filter 的查询示例:
GET test2/_search
{
"query": {
"bool": {
"must": [
{ "match": { "product_name": "running shoes" } }
],
"filter": [
{
"range": {
"price": {
"gte": 10,
"lte": 100
}
}
},
{
"terms": {
"brand": [ "Nike", "Adidas" ]
}
}
]
}
}
}
#在这个查询中:
#must 子句用于匹配产品名称中包含 "running shoes" 的文档。这部分是查询上下文,会影响文档的相关性得分。
#filter 子句包含两个部分:
#第一个 filter 使用 range 查询来过滤价格在 10 到 100 美元之间的产品。
#第二个 filter 使用 terms 查询来过滤品牌为 "Nike" 或 "Adidas" 的产品。
#这两个 filter 子句都不会影响文档的得分,它们只是简单地过滤出满足条件的文档。由于 filter 上下文的结果可以被缓存,这种查询在多次执行时会非常高效。
#总结来说,filter 在 Elasticsearch 中用于精确匹配和过滤文档,而不考虑相关性得分,这使得它们在需要快速过滤大量数据时非常有用。
# 11.传统分页(使用 from 和 size 参数)-适用于小数据量
#在 Elasticsearch 中,主要有两种分页方式:通过 from 和 size 参数进行的传统分页,以及通过 search_after 参数进行的深度分页。
#这是最常见的分页方式,你可以通过设置 from 和 size 参数来获取查询结果的特定页面。
#例如,要获取第2页的结果(假设每页有10个结果),可以这样设置:
GET test2/_search
{
"from": 10,
"size": 10,
"query": {
"match_all": {}
}
}
#在这里,“from”参数表示结果开始的位置,“size”参数表示返回的文档数量。这种分页方式简单直接,但在处理大量数据时可能会遇到性能问题,因为“from + size”的值不能大于 index.max_result_window 设置的值(默认值是10000)。
# 12.深度分页(使用 search_after 参数)---适用于大数据量
#对于需要检索大量数据的情况,Elasticsearch 推荐使用 search_after 参数进行深度分页。search_after 参数使用上一次查询结果中的排序值来获取下一页的数据。
GET test2/_search
{
"size": 10,
"query": {
"match_all": {}
},
"sort": [
{"date": "asc"},
{"_id": "desc"}
],
"search_after": ["2022-01-01T00:00:00", "100"]
}
#在这个示例中,search_after 参数中的值对应于 sort 中的字段。这种方法能有效地处理大量数据,因为它不依赖于偏移,而是直接使用上一次查询的排序值。
#总结起来,from 和 size 适合处理较小的数据集,而 search_after 更适合处理大量数据的深度分页。
六、SpringBoot集成Easy-ES
上面的东西你都理解了吗?记住了吗?
没记住也没关系,现在来给大家介绍一款神器:Easy-Es。
愿你走出半生,归来仍是少年!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号