虚拟内存分页机制的地址映射
概述
在之前的文章虚拟内存对分页机制做了简单的介绍. 还有一个疑问, 那就是如何将虚存中的逻辑地址映射为物理地址呢? 今天就来简单分析一下.
对于一个分页的地址来说, 一般包含两个元素:
- 页号: 第几页
- 偏移量: 当前页的第几个字节
以下以 addr_virtual(p, o)表示一个逻辑地址, 以addr_real(p, o)表示一个物理地址(物理地址也是分页的).
页表
第一步先想一下, 如果要根据一个逻辑地址找到对应的物理地址, 那么这个对应关系必然是存放在某个地方的, 因为映射是没有规律的嘛. 应该使用什么数据结构来存储呢?
因为在分页中, 页是一个最小单位, 故我们只需要页号的映射关系即可, 逻辑地址和物理地址的页大小相同, 偏移量也是完全一样的.
根据 key 寻找 value, 这不就是一个map嘛. 再一看这个map的key, 页号都是数字, 而且是顺序连续的. 这不就是个数组嘛. 漂亮, 就是一个数组.
也就是说, 这个页表是一个以逻辑页号为索引, 物理页号为值的一维数组. 那么这么一个地址转换流程大致如下:
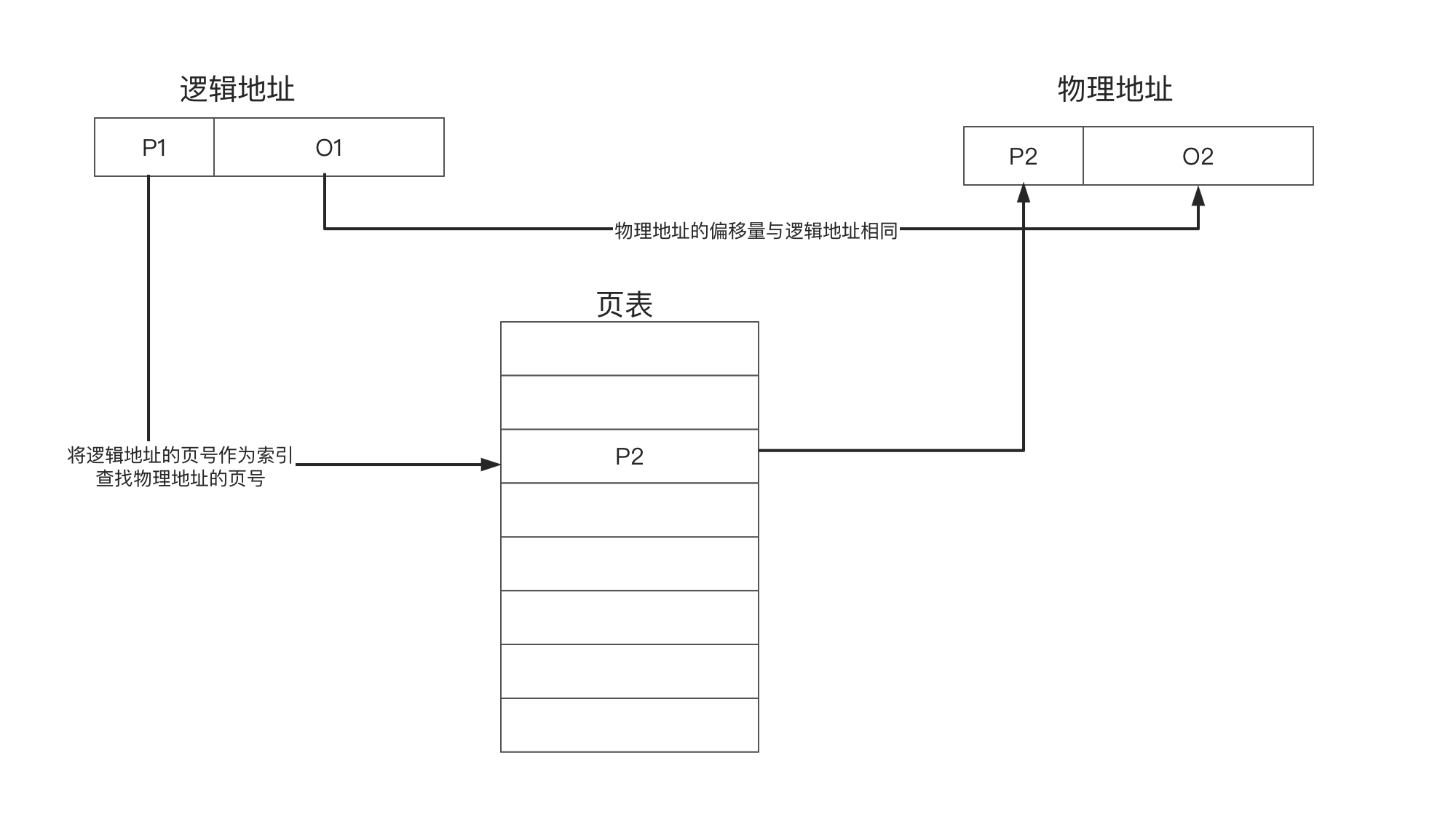
页表中的元素并不是仅仅存储物理页号, 还存储了一些额外的标志位, 用来标识当前页的属性, 简单举几个例子:
- 存在位: 当前也是否加载到内存中了. 若没有加载需要操作系统进行加载
- 修改位: 当前页在内存中是否被修改过. 若修改过, 则回收物理内存时需要将其写会硬盘
- 内核权限: 当前页是否需要内核模式才能访问
- 是否可读位
- 是否可写位
- 是否可执行
- 等等
因为每个进程都拥有独自的虚拟内存, 故每个进程都需要自己的页表.
为了提高运行效率, 这个翻译过程是通过硬件完成的, 既CPU中的内存管理单元mmu来完成的.
是不是看着还挺简单的? 好, 介绍完毕, 文章到此结束.
问题与解决方案#
哈哈, 开个玩笑. 哪有这么容易就结束了. 现在简单分析一下这个简单模型存在的问题. 根据算法的经验, 大部分算法实现, 要么时间复杂度太高, 要么空间复杂度太高.
时间问题#
试想一下访问一个内存的步骤:
- 查找页表找到对应的物理地址
- 访问物理地址
查找页表的操作也是一次内存访问. 也就是说, CPU每访问一次内存就需要一次额外的内存访问. 执行时间直接翻倍.
解决方案#
解决的方法就是我们现在已经用烂了的: 缓存. 内存到 CPU之间已经有了L1 L2缓存, 在mmu中还存在着一个页表的缓存TLB. 每次地址翻译的步骤如下(忽略缺页的情况):
- 查看
TLB中是否存在缓存, 若存在直接获取 - 若
TLB中不存在, 从内存页表中获取并放入TLB
TLB存在的前提, 是程序的访问具有局部性. 终于, 又是程序的局部性救了我们.
空间问题#
我们简单计算一下要存放这个页表需要多少空间.
在32位CPU 中, 可访问的逻辑地址空间为4G. 假设页大小为: 4kb, 那么总页数为:
4G / 4kb = (2^32) / (2^12) = 2^20 = 1mb
再假设, 页表的每个元素需要4个字节, 那么需要的总空间为: 4mb. 每个进程仅仅是存储页表就需要4mb. 而且这还是32位, 如果是64位呢? 可以计算下看看, 结果很夸张.
解决方案#
借鉴一下内存分页的思路, 我们将内存分为 n 个页, 就可以按需加载了. 同样, 也可以将一个大的页表分为n个小的页表, 就可以进行部分加载了, 既多级页表
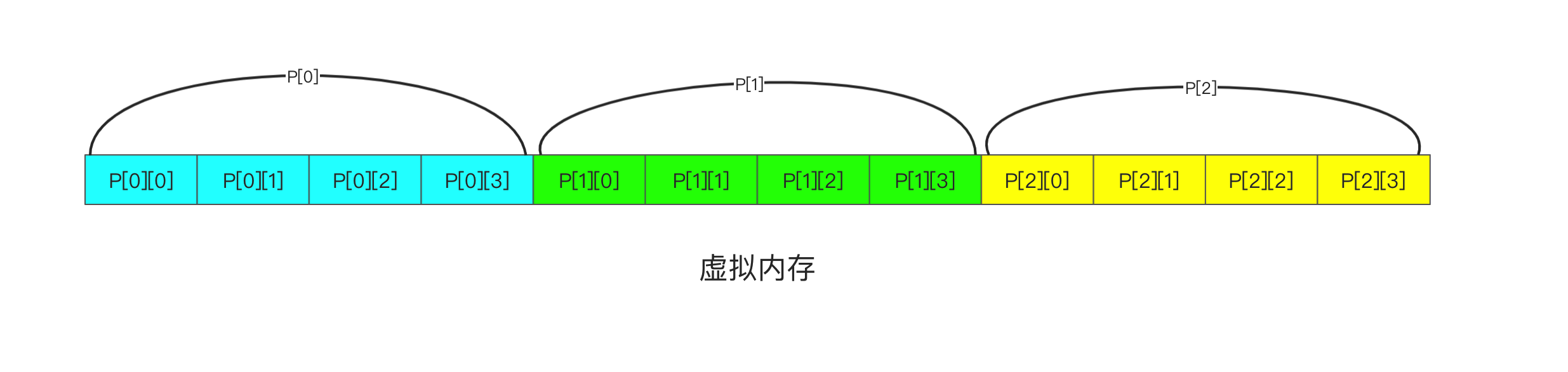
以最简单的二级页表进行说明, 其虚拟内存划分大致如下:
页表的结构大致如下:
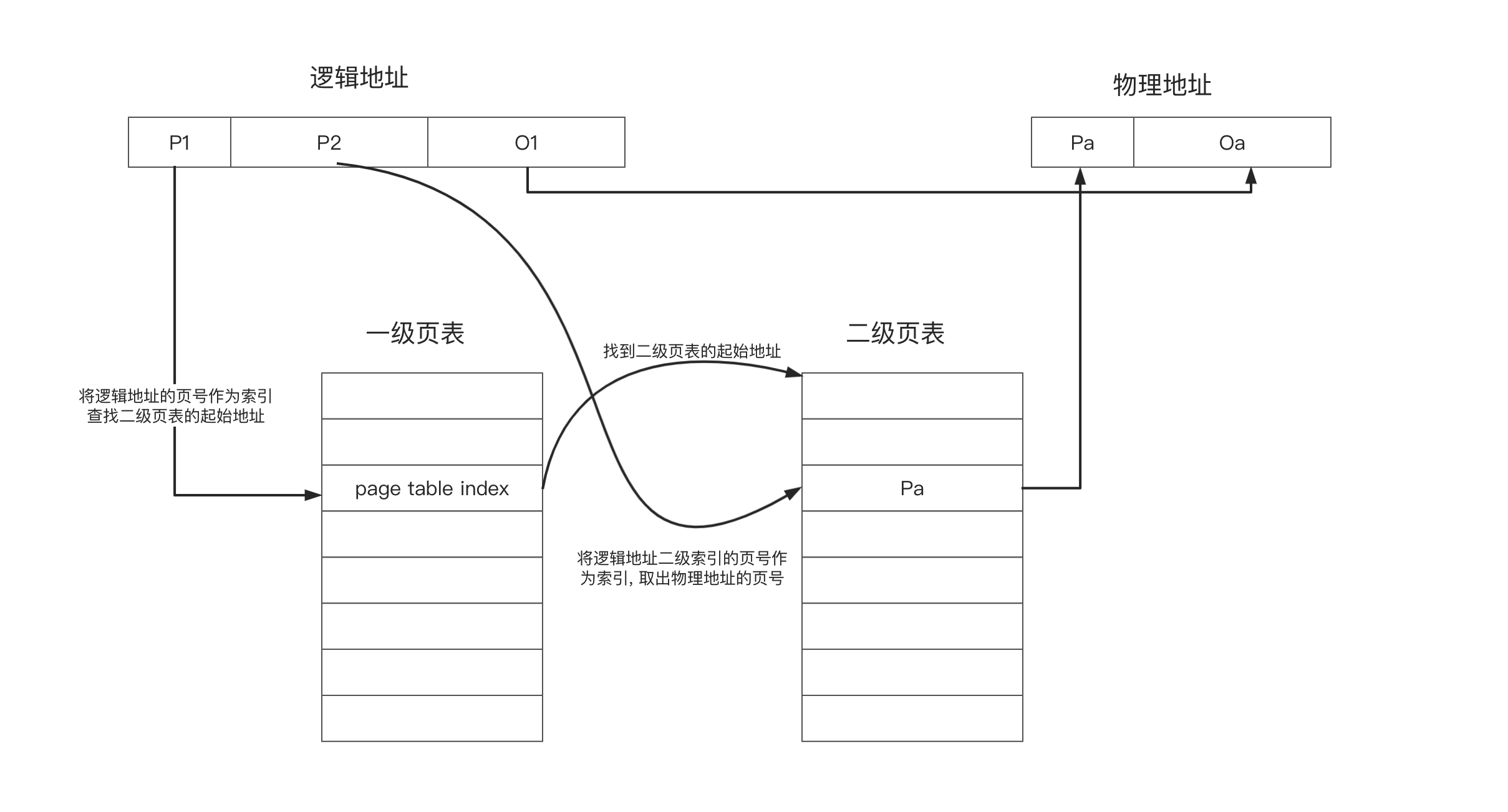
注意, 此时逻辑地址中页号内容存储了两个内容:
- 一级页表的索引
- 二级页表的索引
为什么说多级页表解决了空间的问题呢? 再次根据程序的局部性原理, 一级页表中的大部分对应的值为空, 既大部分二级页表并没有加载到内存中.
此时再算一下, 还是32位CPU, 页的大小还是4kb, 页中元素大小还是4字节. 此时假设一级页表每个元素负责4mb的空间. 那么一级页表占用的总页数为: 4G / 4mb = (2^32) / (2^22) = 2^10. 一级页表占用空间为: (2^10) * (2^2)=4kb
每个二级页表的总页数为: 4mb / 4kb = (2^22) / 2(12) = 2^10 = 1024, 占用空间: (2^10) * (2^2) = 4kb
其中只有一级页表是常驻内存的, 二级页表只需要加载其中一部分. 空间直接降下来了.
但是, 又带来一个新的问题, 现在获取一个物理地址, 需要访问两次内存, 这不是比原来还要慢么? 别忘了刚刚的TLB, 有了这一层缓存, 大部分访问都在mmu内部进行了. 又又又一次, 程序的局部性原理救了我们.
多级页表 , 将二级页表进一步扩展, 就可以得到多级页表了, 不再赘述.
程序的局部性
知道了地址是如何映射的, 对我们平常写程序有什么帮助呢?
页的转换是根据程序的局部性, 所以我们在写代码的时候, 要尽量保证写出来的是具有局部性的, 举个例子:
int main() {
int i, j;
int arr[1024][1024];
// 第一种方式
for(i = 0; i < 1024; i++){
for(j = 0; j < 1024; j++){
global_arr[i][j] = 0;
}
}
// 第二种方式
for(j = 0; j < 1024; j++){
for(i = 0; i < 1024; i++){
global_arr[i][j] = 0;
}
}
}
上面这段代码目的很简单, 给一个1024*1024的二维数组进行初始化. 你能看出这两种方式有什么不同么?
遍历方式不同, 方式一是一行一行的遍历, 方式二则是一列一列的遍历.
我们知道, 二维数组在内存中是顺序存储的. 也就是说, 一个二维数组: [[1, 2, 3], [4, 5, 6]], 在内存中的存储顺序是: 1, 2, 3, 4, 5, 6.
而我们这个数组, 每行1024个int元素, 正好是4kb 一页的大小.
因此, 方式一访问页的顺序是: page1, page1 ... page1024, page1024, 每页访问1024次后,切换到下一页, 共发生 1024 次页的切换
而, 方式二访问页的顺序是: page1, page2...page1024 ... page1, page2...page1024, 依次访问每一页, 每页访问1024次, 共发生 1024*1024次页的切换
性能高下立判, 方式一更加符合局部性原理, 方式二的访问太跳跃了.
当然, 现在内存很大的时候, 所有内容都加载到了内存中, 同时TLB缓存了所有页的映射, 此时两种方式是没有差别的. 但是:
- 若
TLB容量不足, 新的缓存会淘汰旧的缓存, 频繁访问不同的页会造成更多的缓存失效 - 若内存容量不足, 写入新的页会淘汰旧的页, 频繁访问不同的页会导致更多内存的换入换出.
口说无凭#
当然, 口说无凭, 为了对上面页的切换机制有个直观的感受, 我们通过getrusage函数来获取程序运行的页切换信息. 代码如下:
#include <stdio.h>
#include <sys/resource.h>
const int M = 1024;
// 增加列的大小, 以使得效果明显. 10mb
const int N = 1024*10;
// 因为限制了栈的大小, 故将变量提升为全局, 放到堆中
int global_arr[1024][1024*10];
int main() {
int i, j;
// 第一种方式
for(i = 0; i < M; i++){
for(j = 0; j < N; j++){
global_arr[i][j] = 0;
}
}
// 第二种方式
// for(j = 0; j < N; j++){
// for(i = 0; i < M; i++){
// global_arr[i][j] = 0;
// }
// }
struct rusage usage;
getrusage(RUSAGE_SELF, &usage);
printf("页回收次数: %ld\n", usage.ru_minflt);
printf("缺页中断的次数: %ld\n", usage.ru_majflt);
}
现在电脑跑这么个小程序还是比较简单的, 不会有什么区别, 因此还要对进程的内存进行限制. 我是通过限制docker可用内存来实现的:
docker run -it -m 6m --memory-swap -1 debian bash
好, 万事具备, 来看看结果:
方式一

方式二

可以看到, 方式一想比方式二要好很多.
故, 对于性能要求很高的程序, 当你没有优化方向了, 局部性可能会帮到你.




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
2020-11-21 GO 内存对齐