redis的多路复用是什么鬼
有没有人和我一样, 自打知道了redis, 就一直听说什么redis单线程, 使用了多路复用等等. 天真的我以为多路复用是redis实现的技术. 今天才发现, 我被自己骗了, 多路复用是系统来实现的. 对不起自己的专业了.
为了引出多路复用, 我来大胆设想一下技术的发展路程.
前提
一个应用程序, 想对外提供服务, 一般都是通过建立套接字监听端口来实现, 也就是socket. 在这个时候, 应用对外提供服务的过程大概是这样.
- 创建套接字
- 绑定端口号
- 开始监听
- 当监听到连接时, 调用系统read去读取内容, 但是读取操作是阻塞的(也就是说,如果主线程处理read,就不能接收其他连接了, 所以只能开新的线程去处理这个事情)
画个丑丑的流程图:
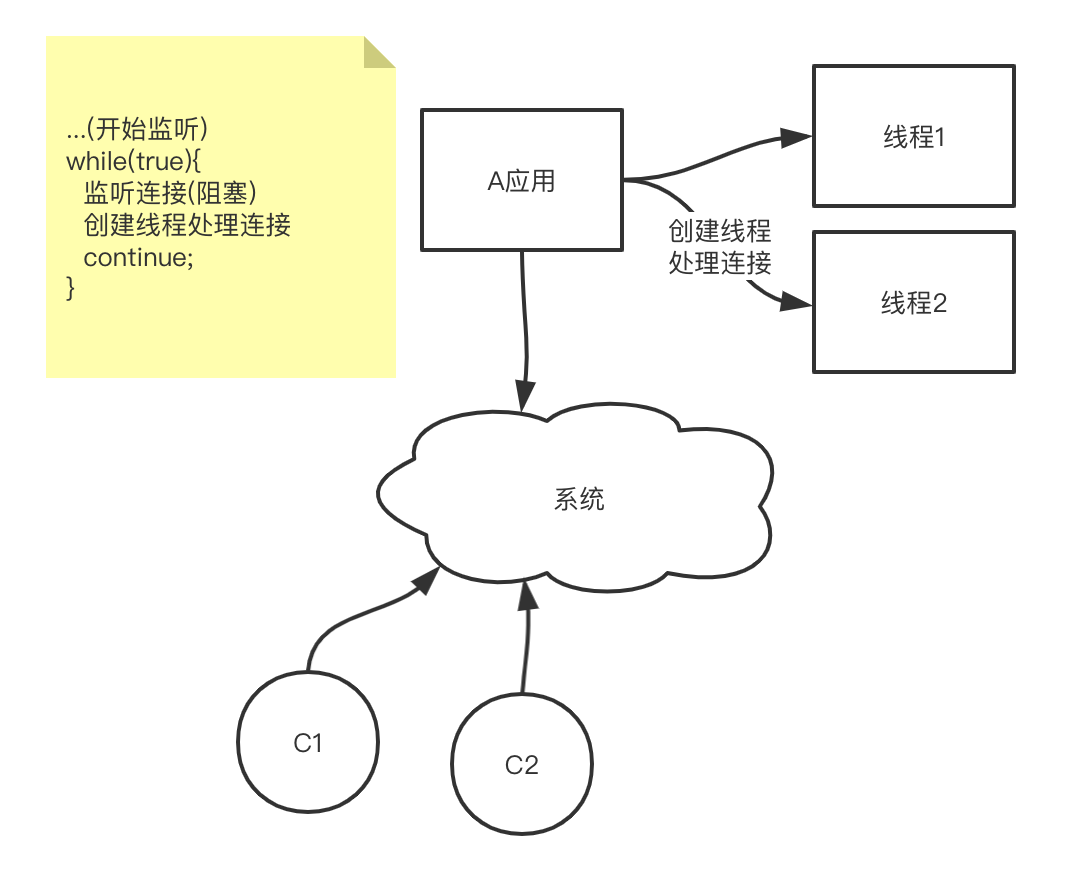
问题分析
这个流程的问题很明显, 会不停的创建线程, 当然, 可以维护一个线程池. 但是线程之间的不停切换也是消耗资源的. 而且也不可能无限的创建线程. 那我如果想一个线程处理呢? 从上面流程图能看的出来, 问题出在阻塞上面. 如果read操作可以立刻返回结果, 如果没有读到数据, 就可以继续处理后边的事情了.
简版
整个简单版本. 主线程维护一个所有连接的列表, 每次循环读取所有列表, 有数据就处理, 没有就跳过.
- 创建套接字
- 绑定端口号
- 开始监听
- 监听到连接, 将连接加到连接列表中, 循环读取连接列表中的所有连接, 对有数据的进行处理
画个丑图:
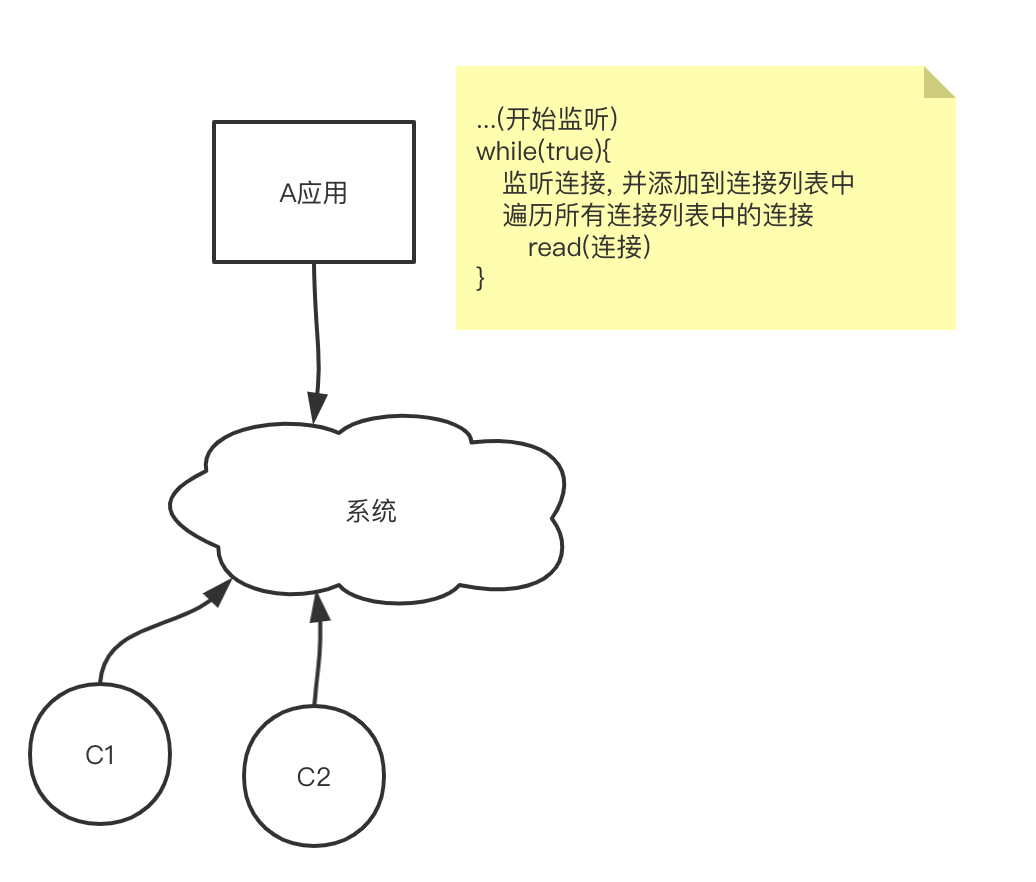
问题分析
现在这样处理貌似是比开线程要好一些了, 但是事实是这样么? 众所周知, 其中的read操作是调用系统函数, 简单说就是要进行进程的切换, 从用户进程切换到系统进程. 连接少还好, 如果有十万个连接, 甚至更多呢? 每次循环都会频繁的调用系统函数, 可能十万次调用, 甚至其中有数据的只有一次, 其余调用都白掉了. 这无疑降低了性能.
其实解决方法说起来也很容易想到. 问题出在系统调用上, 频繁的系统调用导致了问题的出现. 如果能够一次性将需要查询的所有数据都发给系统, 让系统进行查询, 那不就只需要一次切换就可以了么?.
select版本
为了解决上面的问题. 可以批量将待查询的连接发给系统. 出现了select, 这就是说的 多路复用 了. 在系统 中, 无论是监听端口还是建立了连接, 程序拿到的都是一个文件描述符, 将这些文件描述符批量查询就是了.
直接上丑图:

这里和上一个版本相比, 将循环检查交到了系统去做, 只发生一次进程的切换. select 简单说, 就是你告诉系统, 你需要哪些数据, 你同帮你遍历找找, 然后将结果返回给你.
问题分析
这样确实要好上一些, 但是上面的问题还没有完全解决. 比如有10万个连接, 其中有数据的只有一个, 那就回有9999次无效的操作, 虽然这些无效的操作是由系统做的, 但不一样么, 系统做的无效操作, 你应用程序也得等着啊. 而且每次查询都要把所有的需要的都传过去, 10万个就要传10万了, 蓝瘦.
问题出在哪呢? 需要循环遍历, 是因为不知道哪些连接是有数据的, 所以只能一个一个的看. 如果可以不 需要遍历, 直接知道哪些连接是有数据的, 然后直接拿到数据返回就好了.
epoll
跟上一个版本相比, 现在不通过批量查询的方式了, 而是通过回调的方式. 简单说, 建立一个需要回调的连接, 将需要监听的文件描述符都扔给他, 当有新数据到达时, 会返回给你.
上丑图:
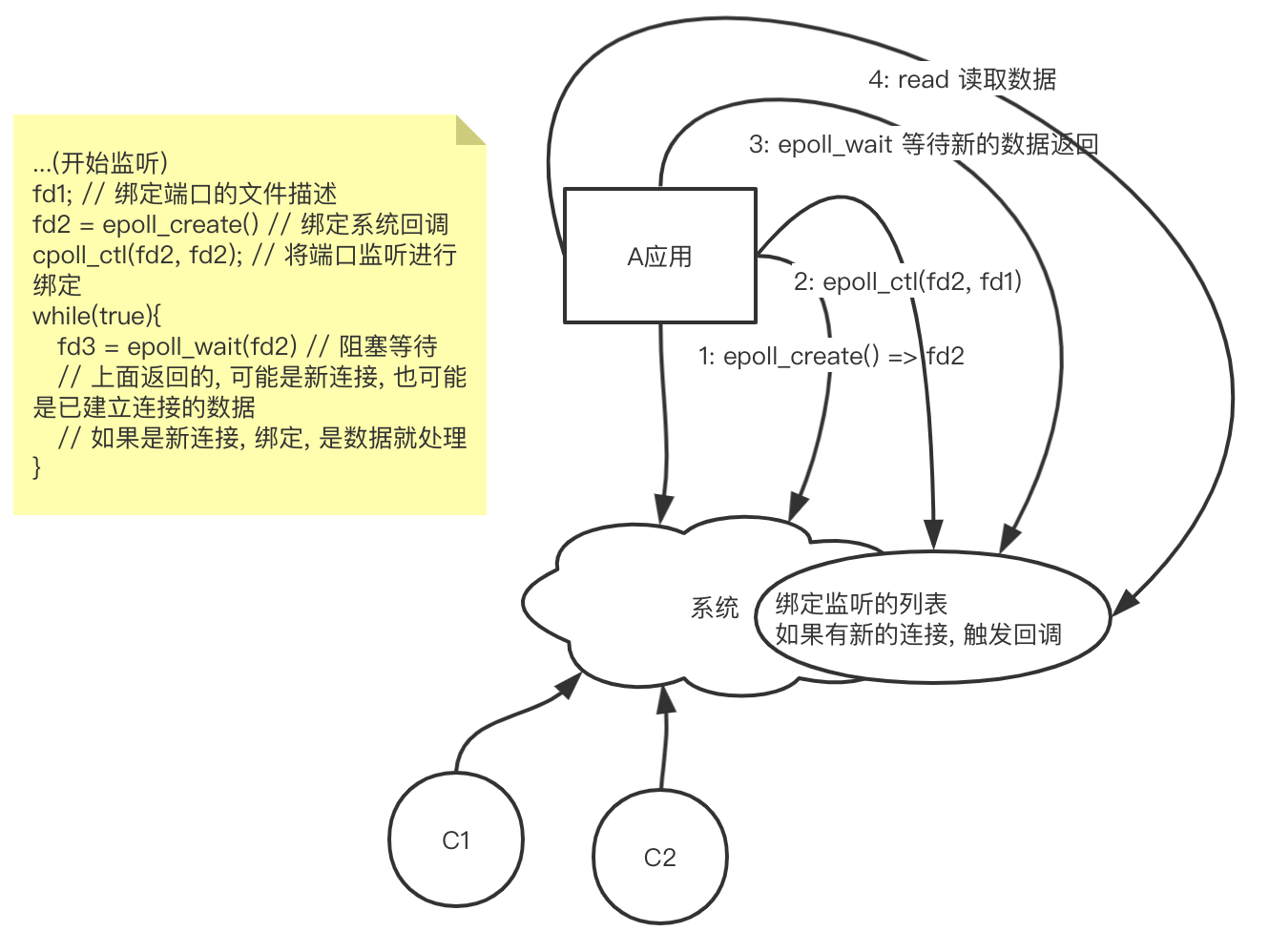
看着是不是有点晕了? 其实它和select版本的区别简单来说, epoll是将你需要监听的列表交给系统维护, 这样当有新数据来的时候, 系统知道这是你要的, 等你下次来拿的时候, 直接给你了, 少去了上面的系统遍历. 同时, 也没有select查询时那一大堆参数, 每次都只调用一次进行绑定即可.
那系统是怎么知道新数据的到来呢? 这里靠的是事件中断, 忘得差不多了, 回头再看看.
epoll 简单说就是, 你告诉系统, 你需要哪些数据, 然后等着, 有数据了系统就通知你, 然后你去读.
以上select, epoll是两种多路复用的技术, 当然, 还有多路复用还有其他的.
据说redis的多路复用对系统方法进行了封装, 不过我还没看, 再议!!!

