跳表
概述
线性表中的链表是我们都很熟悉的结构了, 链表的增删优于数组, 但是不支持随机访问, 链表在查找时, 只能从头节点向后遍历, 那么针对链表, 能不能解决其访问效率的问题呢? 跳表来了, 顾名思义, 跳表就是可以跳跃的表, 我简单画了张图:
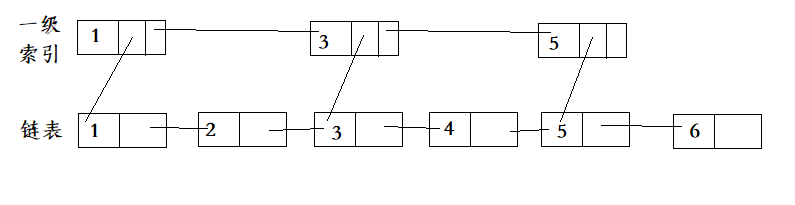
在原来链表的基础上, 建立一个新的索引链表, 原链表没两个建立一个
原来查找节点5的访问顺序是: 1->2->3->4->5->6, 共遍历了6个节点
现在在索引的基础上查找5的访问顺序是: 1->3->5->5->6(先访问索引), 共遍历了5个节点
这种链表加索引的结构就是跳表
查找
从刚才的介绍中可以看出, 加了一层索引后, 访问效率变高了, 那么再加一层呢?

我们再次访问节点6, 访问顺序是: 1->5->5->5->6, 需要访问的节点又变少了, 原来访问节点6需要遍历6次, 现在只需要遍历5次
什么, 效率提升不明显? 好, 我加大数据量你再看:

图画的有些简陋, 将就看吧. 原来链表访问节点128需要遍历128次, 现在只需要遍历14次就可以, 很明显的看出, 跳表确实可以提高查询效率
时间复杂度#
在一个链表种, 查询时间复杂度是O(n)
那么, 添加了索引之后, 跳表的查询时间复杂度能优化多少呢? 从上面的例子可以看出, 简直就是二分查找的翻版, 时间复杂度O(logn)
空间复杂度#
很清楚的看出来, 跳表的解决方案就是用空间来换时间
若原来的链表占用空间为n, 那么一级索引占用空间为n/2, 二级索引占用空间为n/4
总占用空间=n+n/2+n/4+...+2=2n-2
所以, 其空间复杂度为O(n)
插入和删除
当链表有了高效的查找时, 高效的删除和插入也就是顺理成章的事了.
先别高兴太早, 当我们对链表的数据进行插入和删除操作时, 一个因为建立索引而带来的新问题出现了, 当更新链表时, 也要更新索引. 当我们在两个节点之间频繁更新数据时, 就会导致这一段数据过多, 索引就减少了他的意义, 甚至极端情况会退化为单链表.
那么如何保证跳表的平衡, 避免跳表因为插入而出现复杂度退化呢?
一种解决方案是, 当链表插入新的数据时, 同时将新插入的数据添加到跳表的索引中, 这样就解决了索引的问题, 但是将节点更新到所有索引中显然不可取, 同时也会降低查询的效率, 针对这种情况, 通过一个随机函数, 比如: 链表共又3级索引, 随机数是2, 那么就将新插入的节点添加到第一、二级索引中, 如下图:
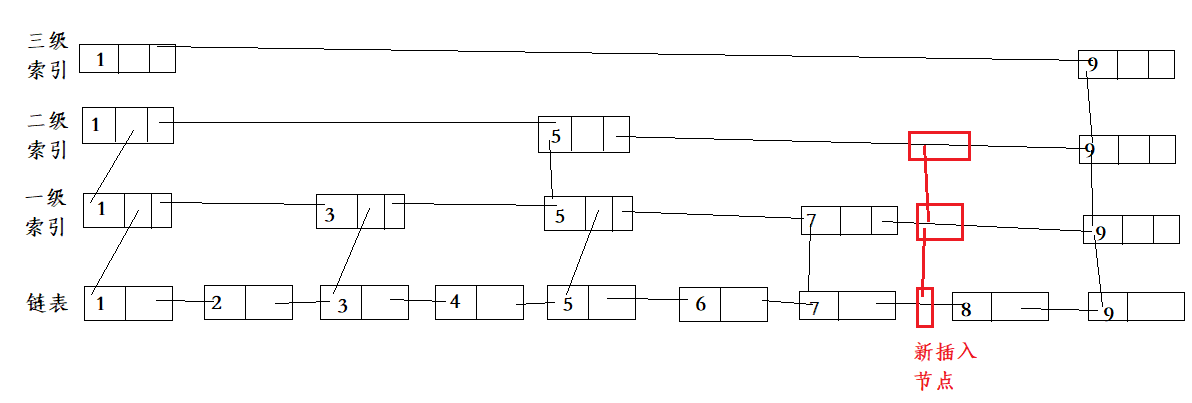
以上, 就是跳表的简单介绍!!




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY